CAP Theorem
Step 13 in the System Design path · 6 concepts · 0 problems
📘 Learn CAP Theorem from zero
CAP Theorem is the first principle interviewers reach for when you propose a distributed datastore: it forces you to admit that during a network partition you can keep serving requests OR keep data consistent, but not both. Knowing the mechanism (not just the three letters) lets you justify "I'll pick an AP store like Cassandra for the shopping cart, but a CP store like ZooKeeper for the leader-election lock" — a concrete, defensible trade-off rather than hand-waving. This walkthrough makes you reason through each decision before revealing the textbook answer.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○Introduction to CAP Theorem
- ○Components of CAP Theorem
- ○Tradeoffs in CAP Theorem
- ○Examples of CAP Theorem in Practice
- ○Beyond CAP Theorem
- ○System Design Tradeoffs in Interviews
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 You have a key-value store replicated across 3 nodes. A request reads from node B while node A just took a write. Which of the three letters — C, A, or P — is at stake here, and what does each one promise?
Reveal the reasoning
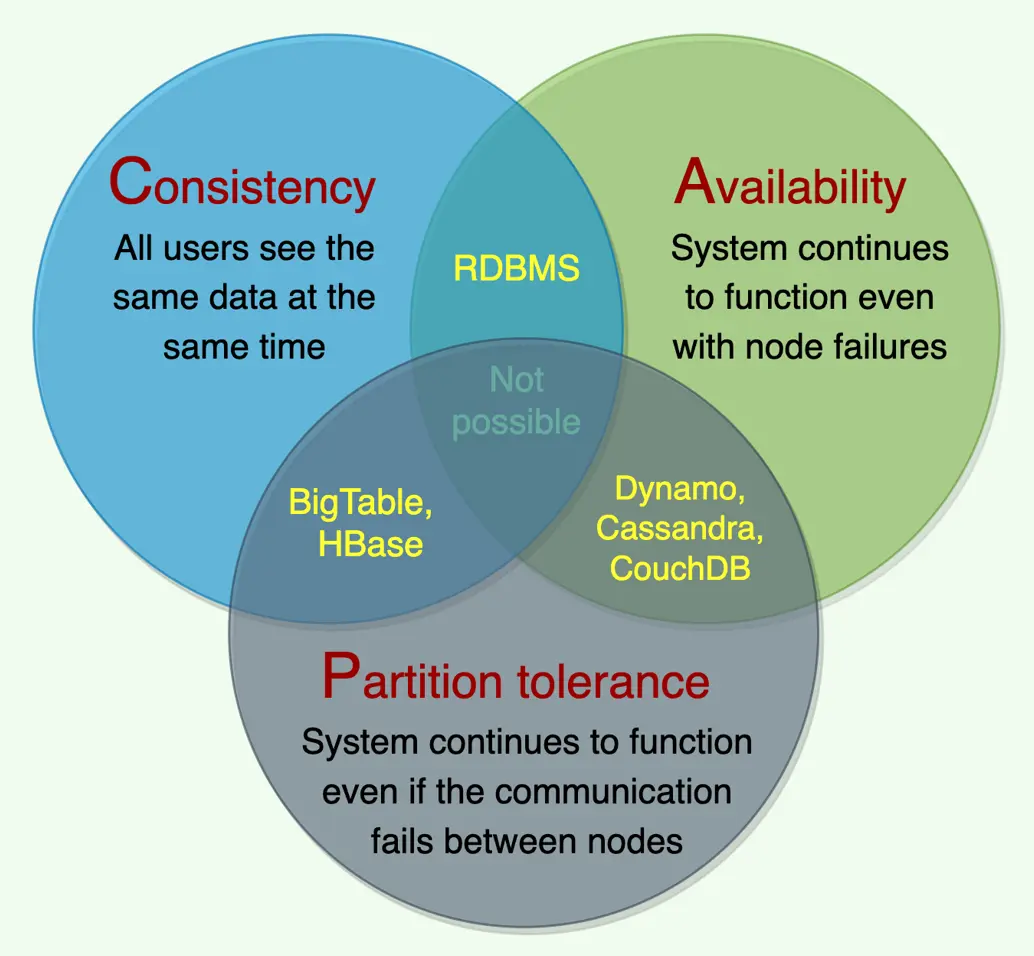
- Consistency (C) here is linearizability, NOT the 'C' in ACID. It promises: every read sees the most recent committed write, as if there were one single copy. So node B must return the value node A just wrote.
- Availability (A): every request to a non-failing node returns a non-error response in bounded time. Node B must answer, never 'try again later'.
- Partition tolerance (P): the system keeps operating even when the network drops/delays messages between nodes (e.g. A and B can't talk for 5 seconds).
Chain: replication exists → replicas can diverge → to make B's read match A's write, A must ship the update to B and B must wait for it → that waiting is exactly the C-vs-A tension. Cost: people conflate this C with ACID consistency and over-claim 'my SQL DB is CP' without checking what it actually does under a partition.
🤔 The network between node A and node B is cut for 10 seconds. A client writes x=2 to A, then immediately reads x from B (which still has x=1). Walk through what B must do — and prove you can't satisfy C and A at the same time.
Reveal the reasoning
Chain: client writes x=2 to A → A tries to replicate to B but the link is down → B never learns about x=2 → now B receives the read. B has exactly two choices:
- Return x=1 (the stale value) → it answered, so it stayed Available, but it broke Consistency.
- Refuse / block until the partition heals → it preserved Consistency, but it sacrificed Availability.
There is no third door: while partitioned, B cannot both answer instantly AND answer correctly. Cost / nuance: the theorem is a statement about the partition moment only. The real choice is binary — CP or AP — and it only bites for the seconds/minutes a partition actually lasts.
🤔 A candidate says 'I'll build a CA system — consistent and available, I just won't tolerate partitions.' Why does this answer get you marked down?
Reveal the reasoning
Chain: any system spread across more than one machine communicates over a network → real networks will drop packets, GC-pause a node for 8s, or sever a switch → so partitions are not optional, they are a fact you must plan for. 'Not tolerating partitions' just means 'when a partition happens, I have no defined behavior' — which in practice degrades to either stale reads (AP) or errors (CP) anyway.
So for any distributed system, P is mandatory; the genuine dial is C vs A. Cost: the only true 'CA' system is a single node (no network = no partition), e.g. one Postgres instance — but that gives up the very scalability/fault-tolerance you replicated for. Saying 'CA' signals you think partitions are avoidable; they aren't.
🤔 You run a 5-node etcd/ZooKeeper cluster that needs a quorum of 3 to commit. A partition isolates 2 nodes from the other 3. What happens to writes on the minority side, and what real latency/availability number does this cost you?
Reveal the reasoning
Chain: a write needs majority acknowledgment (3 of 5) before it commits → the 2-node minority partition can't reach a majority → it rejects writes (and linearizable reads) to avoid serving stale data → the 3-node majority side keeps committing because it still has quorum.
Result: the system stayed Consistent by making the minority side Unavailable for the partition's duration. Concretely, a client hitting the minority gets errors for, say, the 5–30s until the partition heals or a new leader is elected.
When to use: coordination/locks, leader election, config, financial ledgers — anywhere a stale read is dangerous. Cost: you trade uptime for correctness; if no side can reach quorum, the whole cluster halts. That is the point, not a bug.
🤔 In Cassandra/DynamoDB with replication factor 3, a partition splits your replicas. Two clients write to the SAME key on two different sides — one sets price=10, the other price=12. The system accepts both. How does it ever reconcile to a single value?
Reveal the reasoning
Chain: AP stores accept the write on whatever replica is reachable → so both sides succeed and the key now has two conflicting versions → when the partition heals, replicas reconcile via gossip/anti-entropy and discover the conflict → they resolve it with a rule: last-write-wins by timestamp (Cassandra) or application-level merge via vector clocks / CRDTs (Dynamo, Riak shopping carts merge by union).
This is eventual consistency: given no new writes, all replicas converge to the same value within a bounded window (often tens of ms, longer under partition).
When to use: shopping carts, social feeds, metrics, session stores — high write availability matters more than a momentary stale read. Cost: last-write-wins can silently drop the price=10 write; the app must tolerate stale reads and design merge logic, pushing complexity up into your code.
🤔 Your cluster is perfectly healthy — no partition at all. You still chose to wait for all 3 replicas to ack every write, adding ~40ms of cross-region latency per request. CAP says nothing about this. What framework names this trade-off, and what is it?
Reveal the reasoning
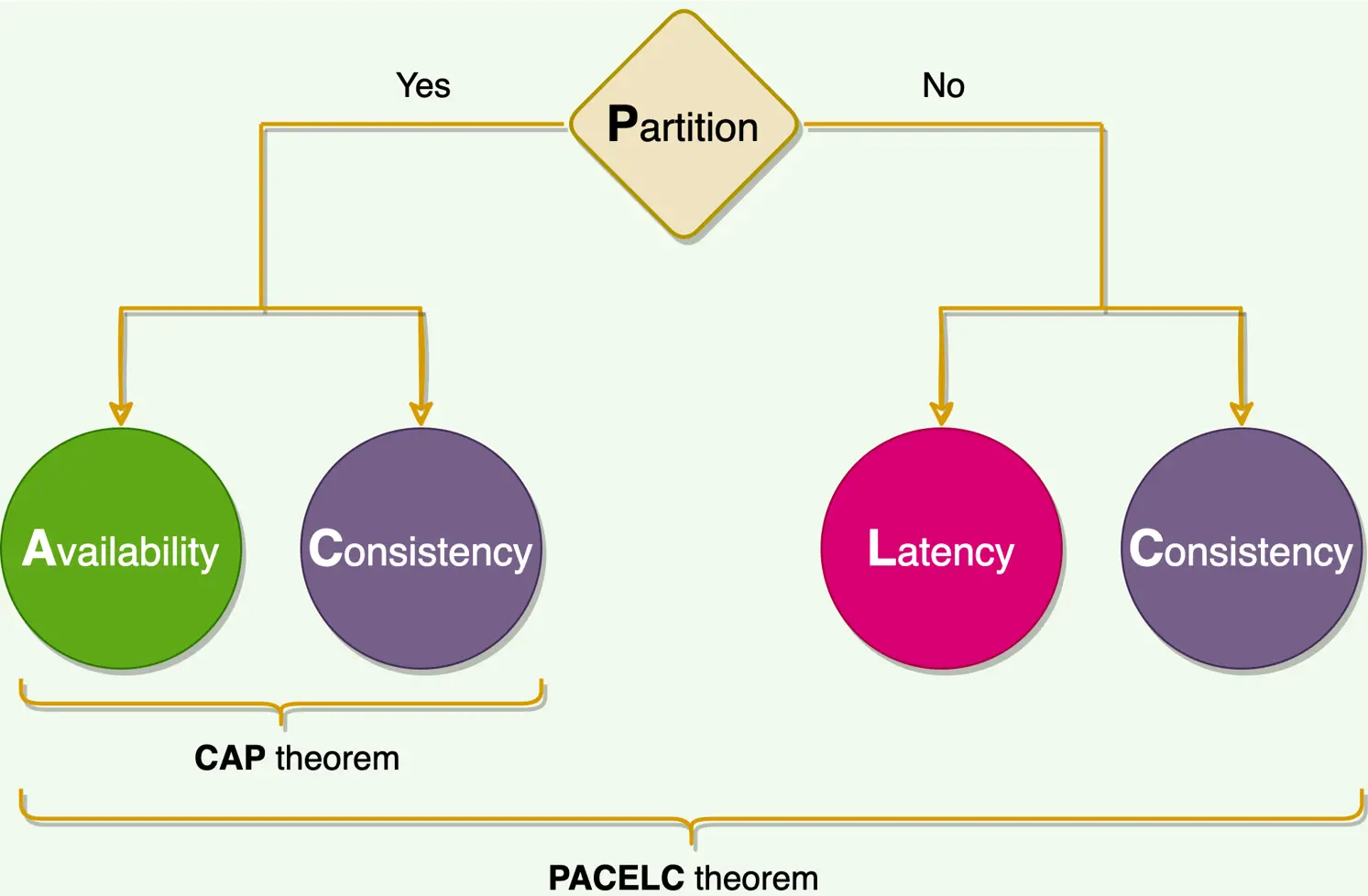
Chain: CAP only describes the partition moment, but the vast majority of the time there's no partition → yet you still face a choice every request: wait for more replicas (stronger consistency, higher latency) or answer from one replica (lower latency, possible staleness).
PACELC captures both regimes: if Partition → choose A or C; Else (normal operation) → choose Latency or Consistency.
- DynamoDB / Cassandra default: PA/EL — available under partition, low-latency otherwise.
- etcd / Spanner: PC/EC — consistent under partition AND willing to pay latency normally.
Concrete cost: Spanner's strong consistency leans on TrueTime and adds a few ms of commit-wait even with no partition — you pay latency on every write for correctness you rarely 'see' exercised. Mentioning PACELC shows you know CAP isn't the whole story.
🤔 Cassandra lets you tune per query with N=3 replicas. Why does setting read-quorum R=2 and write-quorum W=2 guarantee you read the latest acked write — and what does picking R=1, W=1 instead buy and cost you?
Reveal the reasoning
Chain: a write isn't acked until W replicas confirm it; a read polls R replicas and takes the newest version → if R + W > N, the read set and write set must overlap on at least one replica → that overlapping replica is guaranteed to hold the latest acked write → so the read sees it. With N=3, R=2, W=2: 2+2=4 > 3, overlap guaranteed → strong-ish consistency.
- R=1, W=1 → 1+1=2, NOT > 3 → no guaranteed overlap → fastest and most available (any single replica can serve), but you can read stale data.
- W=3 (write all), R=1 → 3+1=4 > 3, fresh reads from one node, but a single slow/down replica blocks every write (availability hit).
Insight: CAP isn't one global switch — you can dial C-vs-A per operation. Note quorum overlap guarantees you see the latest acked value, not full linearizability (no global ordering of concurrent writes). Cost: higher R+W means more nodes must respond → higher latency and lower availability; you're literally trading p99 latency for freshness on each query.
🤔 You're designing checkout: a payments ledger and an 'add to cart' service. The interviewer asks which CAP side each gets. What do you answer, and how do you justify it in one sentence each?
Reveal the reasoning
Chain — match the data's tolerance for staleness to the side:
- Payments / ledger → CP. A stale balance lets a user double-spend → correctness is non-negotiable → choose CP (e.g. Spanner, a quorum SQL store); accept that a partition may reject some writes (better a failed payment than a wrong one).
- Add-to-cart → AP. A user must always be able to add items, even mid-partition → choose an AP store that stays writable and reconciles on heal (e.g. DynamoDB/Cassandra, merging carts by union so no item is lost); accept that a stale cart for a few seconds is harmless.
The winning move: don't pick one side for the whole system — split it per data type and name the store for each. Cost / nuance: two stores means two consistency models to reason about and a reconciliation seam between them (e.g. cart → order → ledger), so you must define what happens if the AP side and CP side disagree at checkout.
📐 Architecture diagrams (2)
🎯 Guided practice
Problem 1 (Easy): Classify the system. You're designing a shopping cart for an e-commerce site. A user adds items from a phone while a replica in another region is briefly unreachable. CP or AP?
- Ask the CAP question: what happens during a partition? Either refuse the "add to cart" (CP) or accept it on a reachable replica and merge later (AP).
- Weigh each failure mode: refusing a cart write = lost sale and an angry user. Accepting a possibly-stale cart = at worst a transient conflict, cheap to reconcile.
- Conclude AP. This is exactly Amazon's Dynamo case: always accept writes, reconcile concurrent versions afterward using vector clocks. Note the real-world catch — Dynamo's cart resolution merges (union) divergent versions, so a deleted item can reappear. The business accepts that anomaly because a resurrected item is far cheaper than a dropped write.
- Core pattern learned: map the decision to "how bad is stale/conflicting data here?" Low harm -> favor Availability, and know your reconciliation strategy (and its anomalies).
Problem 2 (Medium): Tune a quorum + spot a contradiction. A key-value store has N=3 replicas. A teammate claims: "Set W=1, R=1 so reads and writes are fast, and we'll still get strongly consistent reads." Evaluate, then pick settings for a CP use case (an inventory counter that must never oversell).
- State the rule: a read is guaranteed to see the latest write only if the read and write quorums overlap on at least one replica:
W + R > N. - Test the claim: W=1, R=1 gives
1 + 1 = 2, which is not > 3. The read set and write set can land on disjoint replicas, so a read can miss the newest write. The claim is false — that's an eventually-consistent (AP-leaning) config, not strong consistency. - Fix for CP: pick W and R so
W + R > 3, e.g.W=2, R=2(any read pair must share a replica with any write pair). This guarantees fresh reads. - Surface the tradeoff: W=2, R=2 means each op must reach 2 of 3 replicas, so a partition that isolates the minority side leaves it unable to reach quorum, and the system blocks there. That blocking is the price of consistency — exactly right for inventory (never oversell > serve a stale count). Caveat: quorums alone give a freshness guarantee, not full linearizability; production CP stores layer in a consensus protocol (Raft/Paxos, as in etcd/Spanner) for that.
- Core pattern learned: the CAP choice is operationalized by the quorum inequality.
W + R > Nbuys Consistency at the cost of Availability under partition; relaxing it buys Availability at the cost of stale reads. Senior engineers go further and choose per operation (strong reads for checkout, eventual for browsing) — and remember PACELC: even with no partition (Else), you still trade Latency vs Consistency on every quorum round-trip. "Beyond CAP," recognize that C=linearizability is the strongest rung; many "CP" systems actually ship weaker models (causal, sequential), and real guarantees should be checked empirically (e.g., Jepsen), not trusted from the marketing label.
✨ Added by the guide — work these before the full problem set.