API Gateway
Step 6 in the System Design path · 14 concepts · 0 problems
📘 Learn API Gateway from zero
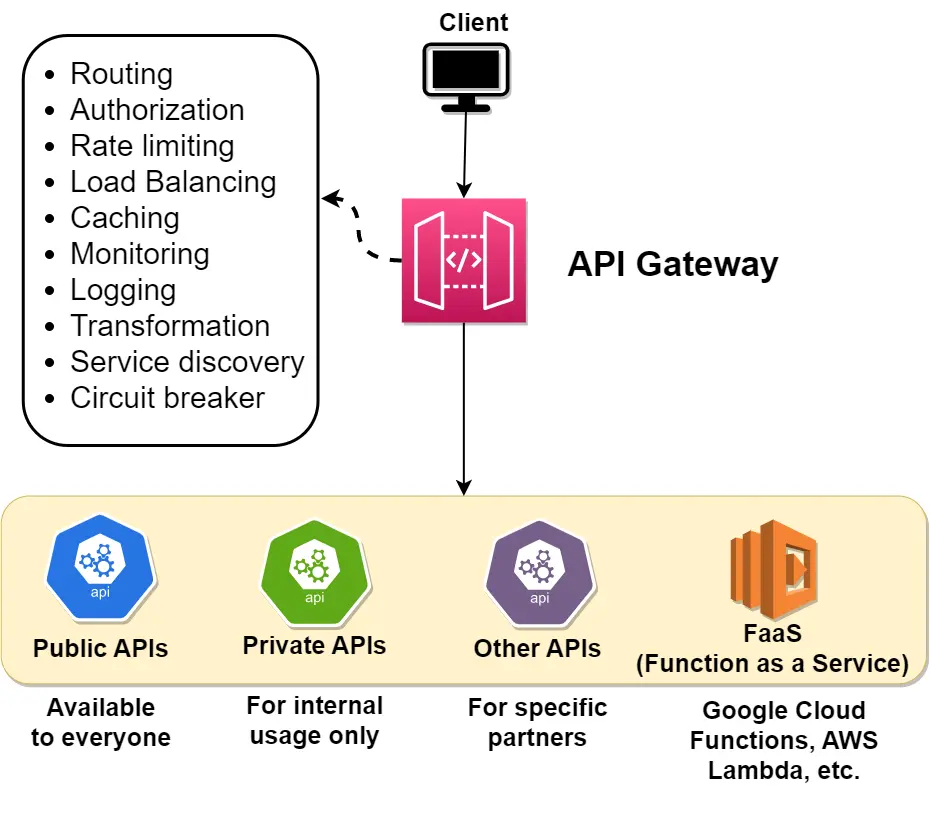
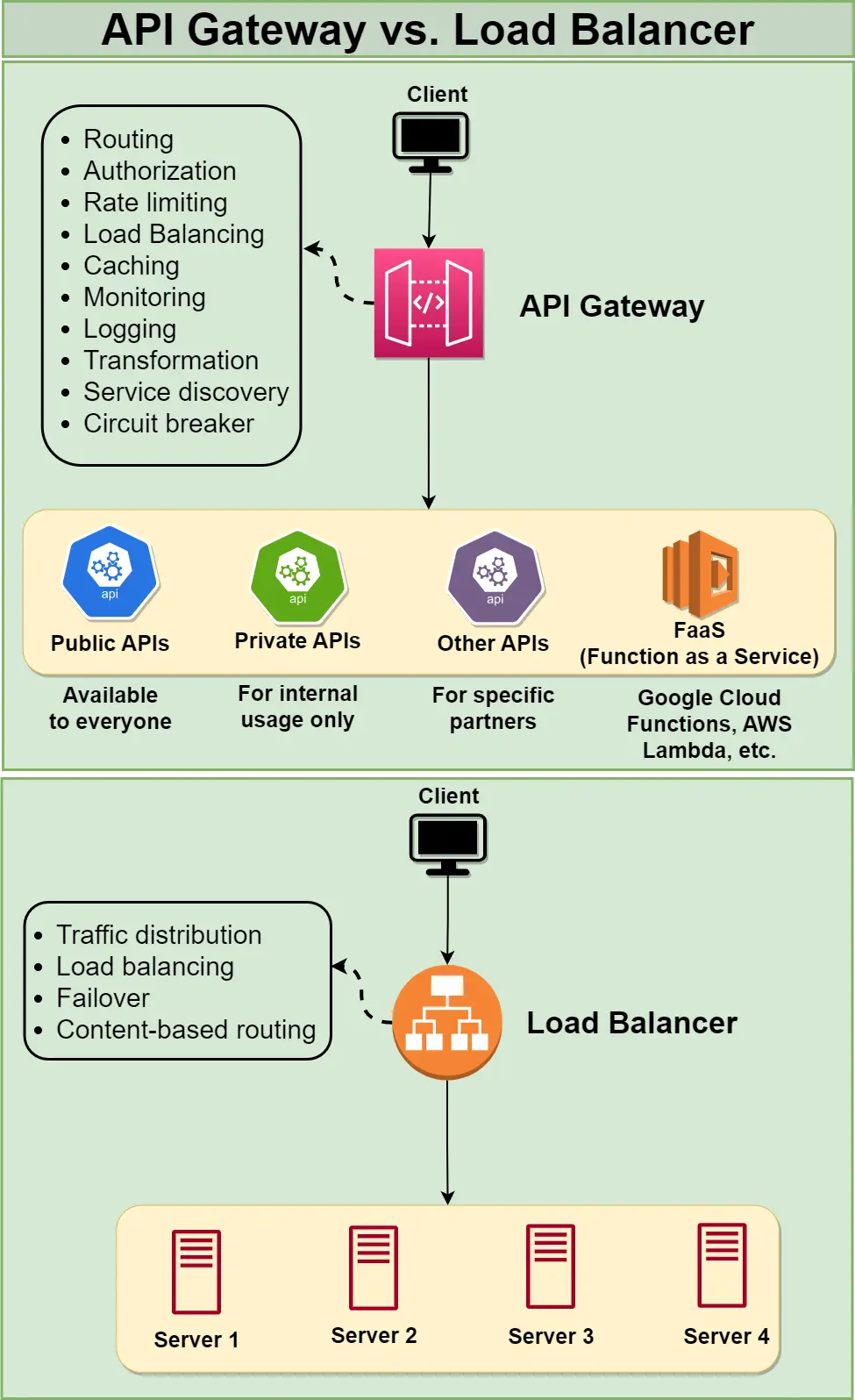
An API Gateway is a single entry point that sits in front of your microservices: every client request hits the gateway first, which then routes it to the right backend service. It exists because once you split a monolith into dozens of services, you do NOT want clients to know dozens of hostnames, re-implement auth in every service, or have each service handle its own rate limiting and TLS. In an interview, reaching for "put an API Gateway here" is how you cleanly offload cross-cutting concerns (auth, rate limiting, routing, TLS termination, aggregation) off your services — but you must defend WHY and name the cost (an extra hop, and a component that becomes a single point of failure unless replicated), or it just looks like buzzword-dropping.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○Introduction to API Gateway
- ○Usage of API gateway
- ○Advantages and disadvantages of using API gateway
- ○Scalability
- ○Availability
- ○Latency and Performance
- ○Concurrency and Coordination
- ○Monitoring and Observability
- ○Resilience and Error Handling
- ○Fault Tolerance vs High Availability
- ○HTTP vs HTTPS
- ○TCP vs UDP
- ○HTTP 10 vs 11 vs 20 vs 30
- ○URL vs URI vs URN
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 You have 40 microservices. A mobile client needs auth, rate limiting, and TLS. Where does that logic live if there is NO gateway, and what breaks as you add services?
Reveal the reasoning
Without a gateway, the cross-cutting logic gets duplicated into every service. Chain of consequences:
- Each of the 40 services re-implements JWT validation, rate limiting, and TLS termination → ~40x duplicated code, 40 places a bug can hide and 40 places to patch a CVE.
- The client must know 40 hostnames and re-do auth per service → chatty, fragile, and it leaks your internal topology to the public.
- A policy change (e.g. rotate the signing key, tighten a rate limit) means redeploying all 40 services instead of 1.
Effect: a gateway centralizes these concerns at one entry point. The client talks to api.example.com; the gateway authenticates once, then routes internally by path/host.
Cost/trade-off: you add a network hop (typically +1–5ms) and a component that, if it falls over, takes down ALL traffic — so it must be replicated (see the SPOF step). You also risk centralizing too much: business logic creeping into the gateway turns it back into a monolith.
🤔 A request hits the gateway at POST /orders. Walk the exact ordered pipeline of stages BEFORE it reaches the orders service — what runs first, and why does order matter?
Reveal the reasoning
The gateway runs a filter/middleware pipeline, and the order is deliberate (decrypt first, then reject cheaply before touching the backend):
- 1. TLS termination — decrypt HTTPS once at the edge. This MUST be first: you cannot read headers, the JWT, or the path until the bytes are decrypted.
- 2. AuthN/AuthZ — validate the JWT/API key. Reject invalid tokens here with a
401so they never touch a backend. - 3. Rate limiting — check the caller's quota (e.g. 1000 req/min). Reject over-quota with
429early. - 4. Routing — match
/ordersto the orders service via a route table / service discovery. - 5. Request transformation — rewrite headers, strip internal fields, inject a trace ID.
- 6. Forward → orders service, then transform + return the response.
Why this order: TLS has to come first physically; after that, auth and rate limiting are the cheapest ways to discard bad traffic. Doing them before routing means a flood of unauthenticated or over-quota requests is rejected at the edge, not amplified into your backend.
Cost/trade-off: every stage adds latency (a 6-stage pipeline might add a few ms), and over-stuffing the gateway with business logic is the classic anti-pattern that turns it into a new monolith and a deployment bottleneck.
🤔 A mobile home screen needs data from 5 services. On a 200ms-latency cellular link, why is it dramatically better for the gateway to fan-out those 5 calls than for the phone to make them?
Reveal the reasoning
This is the API composition / aggregation pattern (often packaged as a Backend-for-Frontend, BFF).
- If the phone makes 5 sequential round trips at 200ms each (mobile RTT), that's 5 × 200 = 1000ms in network latency alone, plus repeated connection/TLS setup.
- If the gateway fans out, the phone makes
1round trip (≈200ms). The gateway lives inside the data center where service-to-service RTT is ~1ms, and it issues the 5 calls in parallel → bounded by the slowest call, say 30ms. - Effect: total ≈ 200 + 30 ≈ 230ms vs ~1000ms+. The phone also receives one payload tailored to that screen instead of 5 raw ones it has to stitch together.
Cost/trade-off: the gateway now owns partial-failure logic (if service 3 of 5 times out, do you return partial data or error?), which is business-aware coupling. That is why aggregation usually lives in a dedicated BFF, not the generic gateway — otherwise the gateway becomes a dumping ground for client-specific logic and every UI change forces a gateway deploy.
🤔 Every request goes through the gateway, so if it dies, everything dies. Concretely, how do you stop it being a single point of failure — and what does that do to your availability math?
Reveal the reasoning
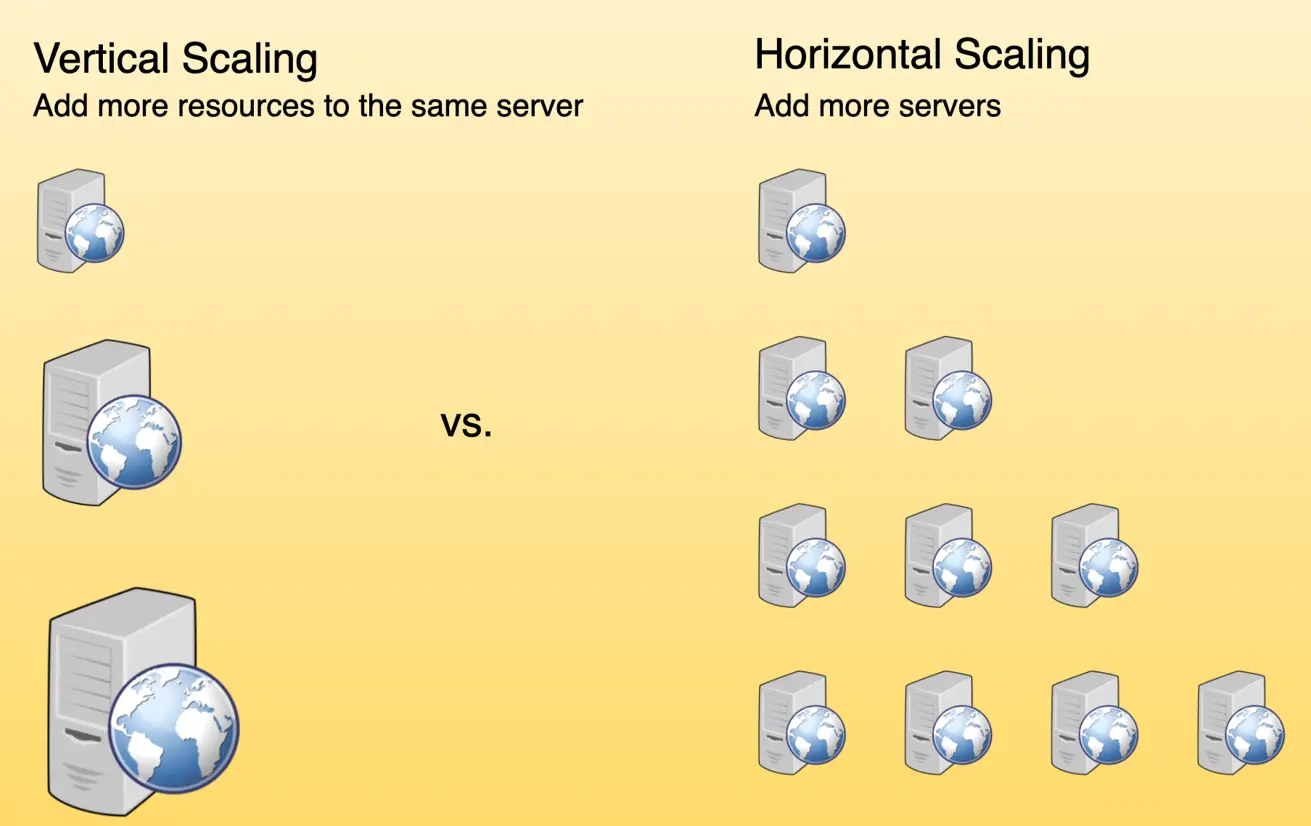
You make the gateway horizontally scaled and stateless, behind a load balancer, ideally spread across availability zones.
- Run
Nidentical gateway instances (say 3+) behind an L4/L7 load balancer with health checks. The LB ejects an unhealthy instance within seconds. - Keep gateways stateless — push session/rate-limit counters to a shared store like Redis — so any instance can serve any request and you can add/remove instances freely.
- Availability math: one instance at 99.9% means ≈8.76h of downtime per year. If you run 3 instances and need only one alive, and you treat their failures as independent, the system is down only when all three fail at once: 1 − (0.001)³ = 1 − 10⁻⁹ ≈ 99.9999999% (nine nines). The headline win is that downtime is now the probability of simultaneous failure, not the failure of any one box.
Cost/trade-off: that nine-nines figure assumes independent failures — in reality the shared LB, shared AZ, a bad config push, or a poison request correlate the failures, so real availability is far lower; the redundancy buys you resilience against independent instance loss, not against a shared-fate bug. Statelessness also forces shared state (Redis) into the hot path → that store is now a dependency you must also replicate. And N instances cost roughly N× compute even at low traffic. "Highly available" (redundant, survives instance loss with seconds of disruption) is not the same as "fault tolerant" (seamless failover with zero perceived impact).
🤔 You run 3 gateway instances and want to cap a user at 1000 req/min. If each instance counts locally, what's the bug — and what fixes it at what cost?
Reveal the reasoning
The bug: with local counters, each of the 3 instances independently allows 1000 req/min. The load balancer spreads the user across all three → the real ceiling becomes 3000 req/min, 3× your intended limit. The limit is global but the state is local, so no instance sees the true total.
- Fix: centralize the counter in a shared store (e.g. Redis with an atomic
INCR+ TTL, or a token-bucket key updated atomically). Every instance reads/writes the same counter, so the 1000/min cap holds globally. - Algorithms: token bucket (allows bursts up to the bucket size, refills at a steady rate) vs fixed window (simple counter per minute, but can permit up to 2× the limit across a window boundary) vs sliding window (smooths that boundary spike at higher cost).
Cost/trade-off: every request now does a network round trip to Redis on the hot path (+~1ms and a hard dependency that can itself become a bottleneck or SPOF). Under extreme load you may relax to approximate limiting — local counters reconciled periodically — trading exactness for lower latency and no shared-store hot spot. This is the coordination tension: strict global correctness costs latency and a shared dependency.
🤔 The payments service gets slow (5s responses). Without protection, why does that one slow service take down the whole gateway, and which patterns prevent it?
Reveal the reasoning
The cascade: each request to payments holds a gateway thread/connection for the full 5s. Requests pile up; the gateway's connection pool (say 200 slots) fills with stuck payment calls. Now requests for healthy services (search, profile) can't get a slot → the whole gateway appears down. One slow dependency exhausts shared capacity and poisons everything.
Resilience patterns the gateway applies:
- Timeouts: cap payment calls at, say, 1s instead of waiting 5s — fail fast and free the thread.
- Circuit breaker: once failures/timeouts cross a threshold (e.g. 50% over a window), "open" the breaker and immediately return a fallback for a cool-off period (~30s) instead of calling payments at all; then go "half-open" and let a few trial requests through to test recovery before fully closing. This frees gateway capacity and gives payments room to recover.
- Bulkheads: give each downstream its own connection pool so a saturated payments pool can't starve search.
- Retries with backoff + jitter: retry transient failures, but capped and jittered, so you don't synchronize a retry-storm onto a struggling service.
Cost/trade-off: aggressive timeouts can abort requests that were legitimately slow-but-fine (false failures). Retries amplify load if unbounded — the cure becomes the disease. An open circuit means users get degraded/fallback responses even for requests that might have succeeded — you trade some correct successes for overall system survival.
🤔 The gateway terminates HTTPS at the edge and talks plain HTTP internally, and speaks HTTP/2 to the client but HTTP/1.1 to a legacy backend. Why these specific choices, and what's the catch?
Reveal the reasoning
TLS termination (HTTPS → HTTP): HTTPS is HTTP carried over TLS, and the TLS handshake (asymmetric crypto + cert exchange) is CPU-expensive. Terminating it once at the gateway means backend services skip per-connection crypto and serve plain HTTP over the trusted internal network → less CPU per service, and certificates/rotation are managed in one place instead of 40.
- Protocol translation: the gateway can speak HTTP/2 to clients (multiplexing many requests over one connection, header compression, lower mobile latency) while still talking HTTP/1.1 to a backend that doesn't support h2 — the client gets the modern protocol without forcing every service to upgrade at once.
Cost/trade-off: terminating TLS means traffic is plaintext on the internal hop, which is only acceptable if that network is trusted; under a zero-trust model you instead re-encrypt to the backend (TLS passthrough or, more commonly, a service mesh doing mutual TLS), trading extra crypto CPU and operational complexity for end-to-end confidentiality. Protocol translation likewise adds a conversion step and means features like h2 server push or streaming may not survive the downgrade to HTTP/1.1.
📐 Architecture diagrams (3)
🎯 Guided practice
- Easy — "Where does auth go?" A startup has 3 microservices, each independently parsing and verifying the same JWT and maintaining its own rate-limit counters; token-validation bugs differ across services.
Step 1: Spot the smell — a cross-cutting concern (auth + rate limiting) duplicated N times. Step 2: The recognition rule says centralize cross-cutting concerns at the front door. Step 3: Put an API Gateway in front; it verifies the JWT once and forwards a trusted internal identity claim (e.g.
X-User-Id) to services. Caveat (FAANG bar): in a zero-trust model services should still not blindly trust a header — bind it to mTLS or a signed internal token so a leaked header cannot impersonate a user. Result: one place to fix auth, consistent rate limiting, simpler services. Core pattern: gateway = single choke point for policy, with defense in depth behind it. - Medium — "Make the gateway not be the SPOF and not melt under a slow dependency." A single gateway instance died at 2 a.m. and the whole product went dark; another night, a slow
payment-servicemade every request hang. Design for availability and resilience.Step 1 (availability): Make the gateway stateless — validate the self-contained JWT rather than holding sessions, and push shared state (rate-limit counters) to an external store like Redis. Statelessness lets you run a fleet behind a load balancer across multiple AZs, removing the SPOF — this is high availability via redundancy. (Note the distinction the scope asks for: fault tolerance is surviving a component failure with no user-visible impact; high availability is keeping uptime high via redundancy and fast failover — related but not identical.) Step 2 (resilience): Wrap every downstream call with a timeout so a slow service cannot pin a thread forever, a circuit breaker that trips open after a failure threshold and fails fast (returning a cached/default fallback) instead of piling on, and a bulkhead (isolated connection/thread pools per downstream) so a sick
payment-servicecannot starvefeed-service. Step 3 (observability): Emit per-route latency, error-rate, and traffic metrics (the RED method) and propagate a trace ID downstream, so you detect the slow dependency before it cascades. Core pattern: stateless fleet + LB across AZs for HA; timeout + circuit breaker + bulkhead for fault isolation — the two pillars that keep the gateway from becoming the system's weakest link.
✨ Added by the guide — work these before the full problem set.