Databases
Step 9 in the System Design path · 12 concepts · 0 problems
📘 Learn Databases from zero
A database is the component you'll defend most in a system design interview: every "where does the data live?" question forces you to justify a storage engine, a consistency model, and an access pattern under load. Interviewers don't want you to recite "SQL is relational, NoSQL is flexible" — they want you to reason from the workload (read/write ratio, query shape, scale, consistency needs) to a concrete choice, and to name the cost you're paying. This walkthrough is question-first: try to answer each prompt out loud before you reveal the reasoning, because that's exactly the muscle the interview tests.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○Introduction to Databases
- ○SQL Databases
- ○NoSQL Databases
- ○SQL vs NoSQL
- ○ACID vs BASE Properties
- ○RealWorld Examples and Case Studies
- ○SQL Normalization and Denormalization
- ○InMemory Database vs OnDisk Database
- ○Data Replication vs Data Mirroring
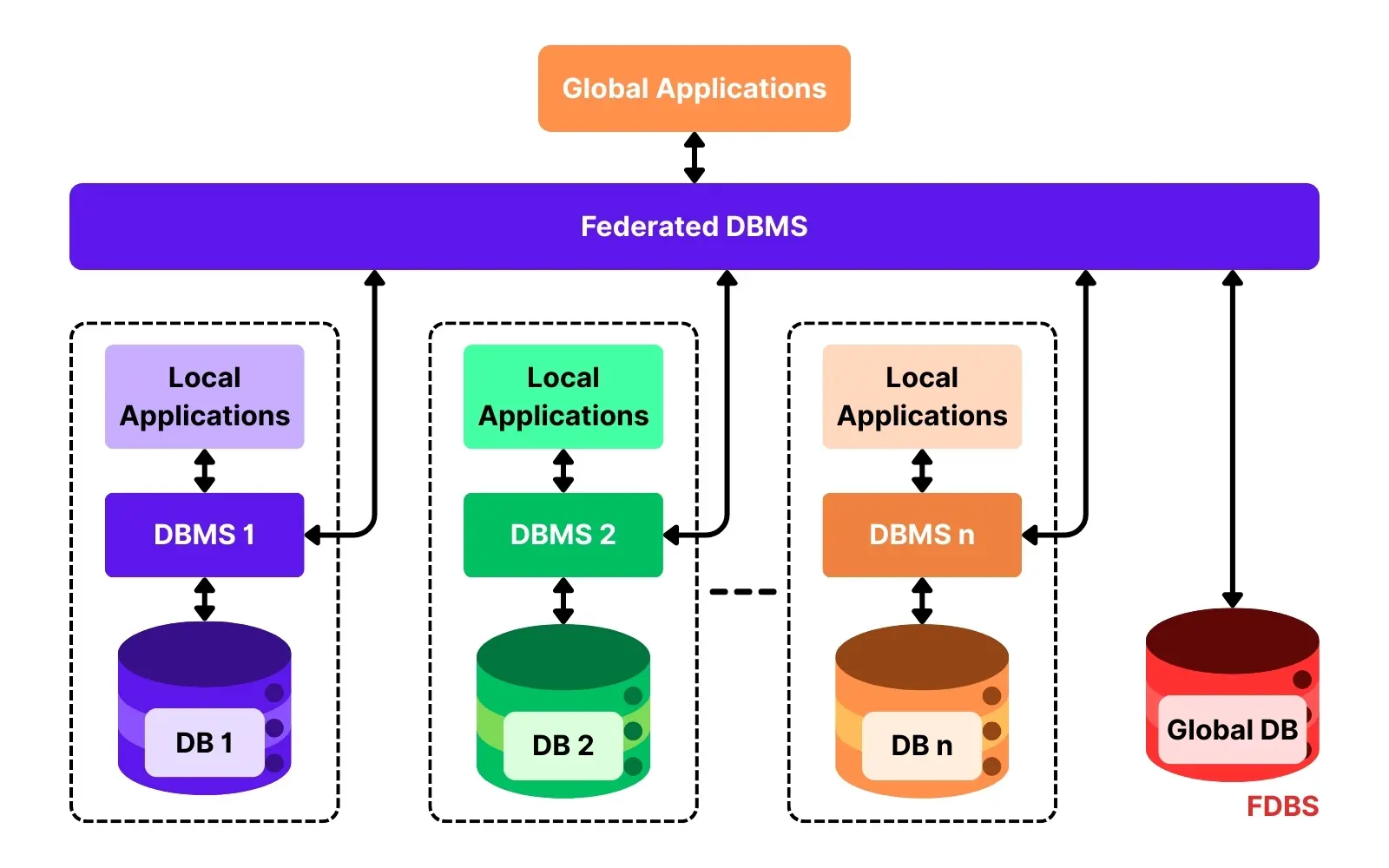
- ○Database Federation
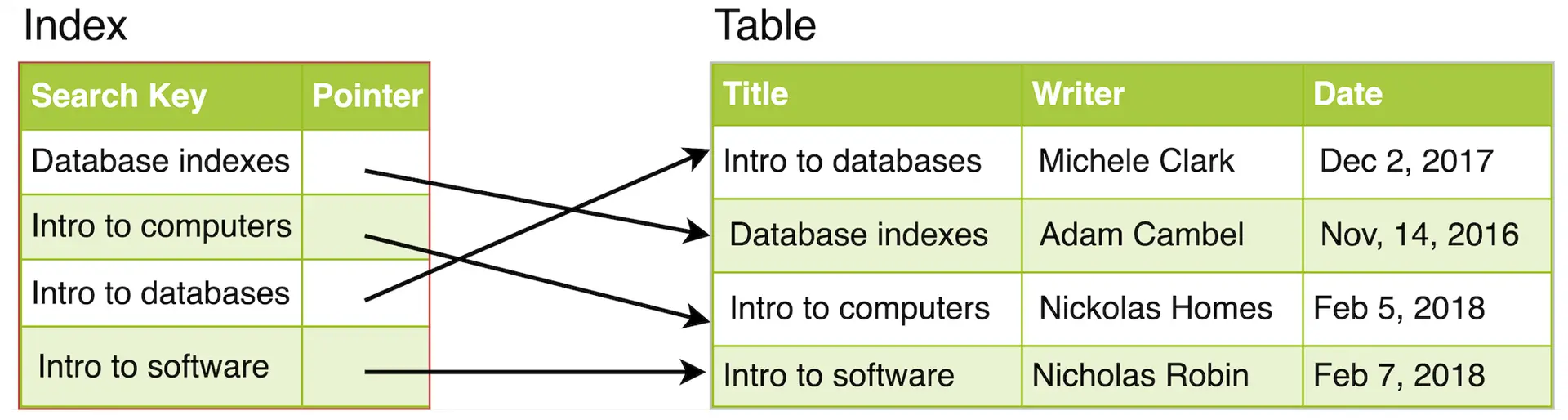
- ○What are Indexes
- ○Types of Indexes
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 You're storing 50M user records. A banking ledger needs every debit+credit to balance; a social feed just needs to show recent posts fast. Same data store for both?
Reveal the reasoning
No — the access pattern and consistency need decide, not the data size.
- Banking → SQL. Money requires multi-row atomicity (debit account A, credit account B as one unit). Chain: a relational engine gives you
ACIDtransactions → either both rows commit or neither → balances never drift. A foreign key + schema also rejects a transfer to a nonexistent account at write time. - Social feed → NoSQL (e.g. a wide-column or document store). Chain: you read one user's feed by key, you tolerate a post showing up 200ms late, and you need to scale writes across hundreds of nodes → a horizontally-sharded NoSQL store gives you that throughput without join overhead.
Cost: SQL's strong guarantees make horizontal write-scaling hard (you eventually shard manually, losing easy cross-shard joins and cross-shard transactions). NoSQL's scale costs you joins, multi-key transactions, and forces the app to handle stale reads. The honest interview answer: pick by workload + consistency, and most real systems use both — SQL for the ledger, NoSQL for the feed.
🤔 Two people book the last seat on a flight at the same millisecond. Without isolation, what concretely goes wrong — and which letter prevents it?
Reveal the reasoning
Both transactions read seats_left = 1, both write seats_left = 0, and you've sold one seat twice — a classic lost update.
- Isolation is the letter at work: the engine serializes the two transactions (via row locks, or MVCC plus a write-conflict check) so the second booking sees the committed
seats_left = 0and is rejected. Chain: first txn locks the row → second txn waits → re-reads0→ fails cleanly. - Atomicity: if the payment step fails mid-transaction, the seat decrement is rolled back too → no orphaned holds.
- Durability: once the commit returns, a power loss can't lose the booking — it was flushed to the write-ahead log on disk before commit acknowledged.
- Consistency: declared constraints (e.g.
seats_left >= 0) are never left violated by a committed transaction.
Cost: isolation isn't free. Stronger isolation (SERIALIZABLE) takes more/longer locks → more contention → lower throughput and possible deadlocks (or, under MVCC, more serialization-failure retries). Many systems run at READ COMMITTED and accept some anomalies for speed. The trade-off you state in interview: correctness vs. concurrency.
🤔 A shopping cart at Amazon scale spans hundreds of servers across regions. They deliberately let two devices show slightly different cart contents for a few hundred ms. Why would anyone choose that on purpose?
Reveal the reasoning
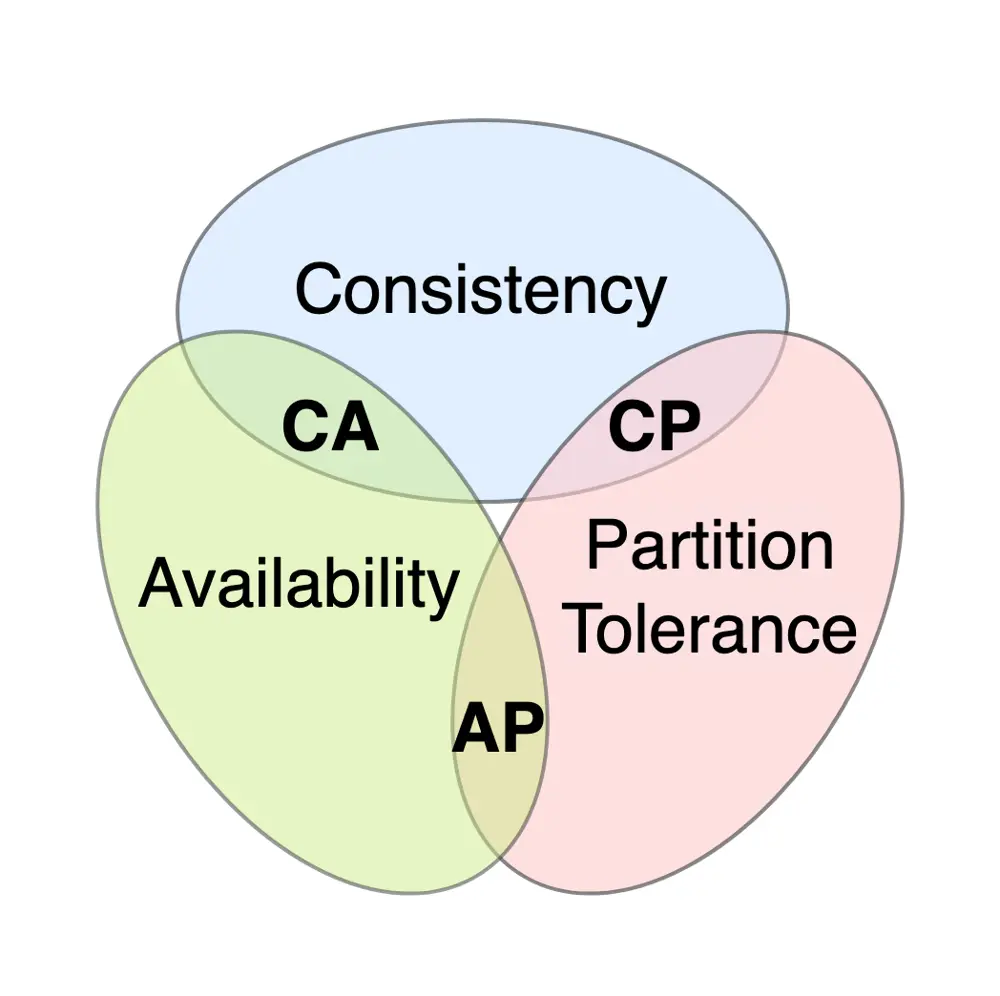
Because of the CAP reality: when a network partition happens (and at that scale it constantly does), a distributed store must choose between rejecting writes to stay consistent (CP) or serving them on whichever replica answers and reconciling later (AP). For a cart, a rejected 'Add to cart' loses revenue; a few-second-stale cart does not — so you pick availability.
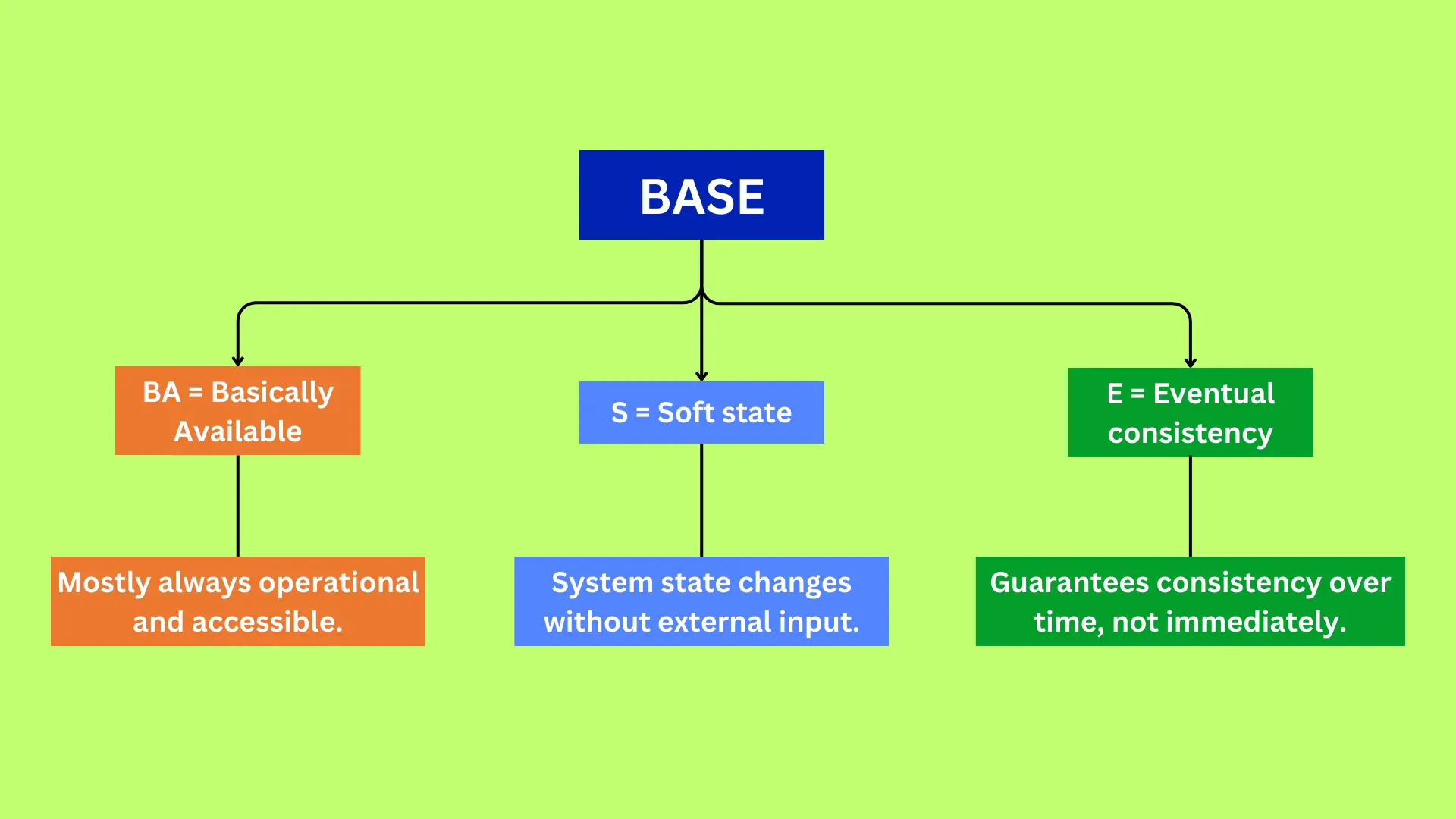
BASE = Basically Available, Soft state, Eventual consistency. Chain: accept the write on whatever replica answers → return success immediately (low latency, stays up during a partition) → replicas propagate the change in the background → after the writes stop, all replicas converge to the same value.
Concrete win: p99 write latency stays in the low-ms range and the site keeps serving during a partition, instead of timing out while waiting for a cross-region quorum.
Cost: you can read stale data (write on one replica, read from another, see the old value), and concurrent writes can conflict — now the app must resolve them (last-write-wins silently drops one update; or you merge, e.g. cart = union of items, which is exactly what Dynamo-style carts do). You've moved correctness work from the database into application logic. That's the BASE bargain: availability + scale, paid for with staleness and conflict-handling.
🤔 An e-commerce orders table currently joins 5 tables (user, address, product, price, tax) on every read, and your order page does 40,000 reads/sec. The joins are killing p99. Do you copy the product name and price into the orders row?
Reveal the reasoning
For this read-heavy path, yes — denormalize.
- Normalized (3NF) stores each fact once → no update anomalies, smaller storage, a price change touches one row. Chain: but every read must
JOIN5 tables → at 40k rps the repeated join work dominates → p99 climbs. - Denormalized copies
product_nameandprice_at_purchaseinto the order row → the read becomes a single-row, single-table fetch → p99 drops, often by an order of magnitude.
Bonus: an order should snapshot the price at purchase time anyway — denormalizing here is also more correct, since a later price change must not rewrite what past orders charged.
Cost: redundancy. The product name now lives in millions of order rows; renaming a product means rewriting all of them (or accepting they keep the old name). You've traded write-time complexity + storage + risk of inconsistency for read speed. Rule of thumb to say out loud: normalize for write-heavy / source-of-truth data, denormalize the hot read paths.
🤔 SELECT * FROM users WHERE email = ? on a 100M-row table takes 8 seconds. You add an index on email and it drops to ~2ms. Mechanically, what did the index do?
Reveal the reasoning
Without an index the engine does a full table scan: read all 100M rows and compare each email → O(n), seconds.
An index is a separate sorted structure — typically a B-tree (really a B+ tree) — keyed on email, where each leaf entry points back to the row. Because each node holds many keys, the fan-out is high (hundreds of keys per page), so the tree is shallow. Chain: the lookup walks the tree top-down, narrowing the search range at each level → for 100M rows the tree is only ~4 levels deep → ~4 page reads instead of millions of row comparisons → O(log n), ~2ms. (A hash index gives ~O(1) for exact-match equality, but can't serve range queries like created_at > ?; B-trees serve both equality and ranges, which is why they're the default.)
Cost: the index is a derived copy that must be kept in sync. Every INSERT/UPDATE/DELETE to an indexed column now also updates and rebalances the B-tree → writes get slower and you spend extra disk on the index. So indexing is the classic read-speed-for-write-speed-and-storage trade. Don't index everything — index the columns your WHERE, JOIN, and ORDER BY clauses actually filter on.
🤔 You have three slow queries: (1) login by exact email, (2) 'orders in the last 30 days', (3) 'fetch a user + their most recent order in one read'. Would one generic index fix all three?
Reveal the reasoning
No — the query shape dictates the index type.
- (1) Exact match → a hash index (~O(1) equality) or a plain B-tree both work. A hash can't do ranges, so a B-tree is the safe default when in doubt.
- (2) Range / sort (
created_at > now() - 30 days) → a B-tree: because its leaves are sorted, the engine seeks to the start of the range and scans sequentially → no full scan. - (3) User + their latest order together → a composite index on
(user_id, created_at DESC)so the latest order is the first match for that user, and/or a clustered index that physically stores rows in key order so related rows sit on the same page (one read serves several). A covering index — one that includes every column the query needs — lets the DB answer straight from the index without touching the table at all.
Other types worth naming: full-text indexes for search-in-text, geospatial (R-tree / geohash) for 'restaurants near me'.
Cost: each index added is more write amplification and disk. A table can have only one clustered index (it defines the physical row order), so you must spend it on your single most important access path. More index types ≠ faster — the wrong index for the query shape just sits unused while still slowing down writes.
🤔 Reads are 95% of your traffic and one DB can't keep up. A teammate says 'just turn on replication, that's also our backup.' Two things are wrong with that sentence — what?
Reveal the reasoning
First, what replication actually fixes: it solves read scaling, not the teammate's mental model of a backup. Chain: a primary takes all writes and streams its change log to N read replicas → you route the 95% read traffic across the replicas → each replica serves a fraction of reads → you scale reads roughly linearly by adding replicas. (Writes still funnel through the single primary, so this does not scale writes — that's what sharding is for.)
Wrong thing #1 — replication is not a backup. A replica is a live mirror, so it faithfully replays your mistakes: a bad UPDATE, an accidental DROP TABLE, or app-level corruption hits the primary and is copied to every replica within milliseconds. A backup is a point-in-time snapshot you can restore from before the damage — replication gives you no such time travel.
Wrong thing #2 — replicas serve stale reads, and async failover can lose data. Most setups replicate asynchronously: the primary acks the write before the replica has it, so a read replica is always slightly behind (replication lag). Chain: user writes, immediately reads from a replica → sees old data ('read-your-writes' violation). Worse, if the primary dies before lag catches up, those un-replicated writes are simply gone on failover.
Cost / the trade-off: asynchronous replication buys high availability and read scale but gives up consistency (stale reads, possible data loss on failover). Synchronous replication fixes that — the primary waits for a replica to confirm before acking → no lost writes — but every write now pays the round-trip latency to the replica, and the primary can stall if a replica is slow. So: replicate for read scale and failover, take real periodic backups for recovery, and choose sync vs. async by whether you can tolerate stale-or-lost writes.
📐 Architecture diagrams (6)


🎯 Guided practice
- Easy — Should I add an index, and which kind? You have a 50-million-row
orderstable. "My orders" runsSELECT * FROM orders WHERE user_id = ?and it's slow. Step 1: Identify the access pattern — equality filter onuser_id, returning a small subset. Step 2: Without an index the DB does a full table scan,O(n)= 50M row reads. Step 3:user_idhas high cardinality (many distinct values) and sits on the hot read path — a textbook index candidate. Step 4: Create a B-tree index onuser_id; the lookup becomesO(log n), a handful of page reads. If the query also didORDER BY created_at, a composite index(user_id, created_at)serves filter + sort together; if it selected only a couple of columns, a covering index could answer it without touching the table. A hash index would work for the equality but couldn't help a range likeamount > 100. Step 5: Note the cost — each INSERT/UPDATE now also maintains this index (O(log n)write overhead plus storage). Pattern: index columns used in WHERE/JOIN/ORDER BY on read-heavy paths with high cardinality; avoid indexing low-cardinality columns or write-hot tables blindly. - Medium — Pick the storage strategy for a two-workload system. Design storage for a payments service (account balances, transfers) and an activity feed (billions of "user liked post" events). Step 1: List requirements per workload. Payments: multi-row atomic transfer (debit A and credit B together), strong consistency, correctness non-negotiable, moderate volume. Feed: enormous write volume, simple append + read-by-user, schema may evolve, eventual consistency tolerable. Step 2: Map to guarantees — payments demand ACID (a partial transfer that debits but never credits is unacceptable; isolation prevents double-spend). The feed fits BASE (a like showing a second late is fine). Step 3: Choose models — payments: a relational/SQL DB (Postgres/MySQL) with transactions; feed: a wide-column NoSQL store (Cassandra) partitioned by
user_idfor horizontal write scale. Step 4: Scale each — payments: vertical scale plus read replicas for reporting (watch replication lag; route balance reads to the primary); feed: shard by partition key and denormalize so each read is a single-partition lookup. As the relational side grows, you can federate by splitting unrelated domains (accounts vs. ledger vs. user profile) into separate databases to spread load. Step 5 (latency layer): front hot reads (balances, recent feed) with an in-memory cache (Redis) over the on-disk source of truth. Pattern (Alex Xu): derive the data model from access pattern + consistency need + scale, not from a default favorite. Mixing engines in one system (polyglot persistence) is normal and a strong interview answer.
✨ Added by the guide — work these before the full problem set.