Distributed File System
Step 21 in the System Design path · 11 concepts · 0 problems
📘 Learn Distributed File System from zero
A Distributed File System (DFS) like HDFS or GFS stores files across hundreds of cheap machines but presents them as one filesystem. It is a favorite interview topic because it forces you to reason about the three hard problems of distributed storage at once: how do you split a 10 GB file across machines, how do you survive disk failures that happen daily at scale, and how do you keep one tiny "brain" (the metadata node) from becoming a bottleneck? This walkthrough won't hand you the answers — each step poses a question. Try to reason it out before you reveal the chain. Master these mechanisms (chunking, replication, the metadata/data split, lease-ordered writes, heartbeat-based failure detection) and you can defend almost any storage-heavy design.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○What is a Distributed File System
- ○Architecture of a Distributed File System
- ○Key Components of a DFS
- ○Batch Processing vs Stream Processing
- ○XML vs JSON
- ○Synchronous vs Asynchronous Communication
- ○Push vs Pull Notification Systems
- ○Microservices vs Serverless Architecture
- ○Message Queues vs Service Bus
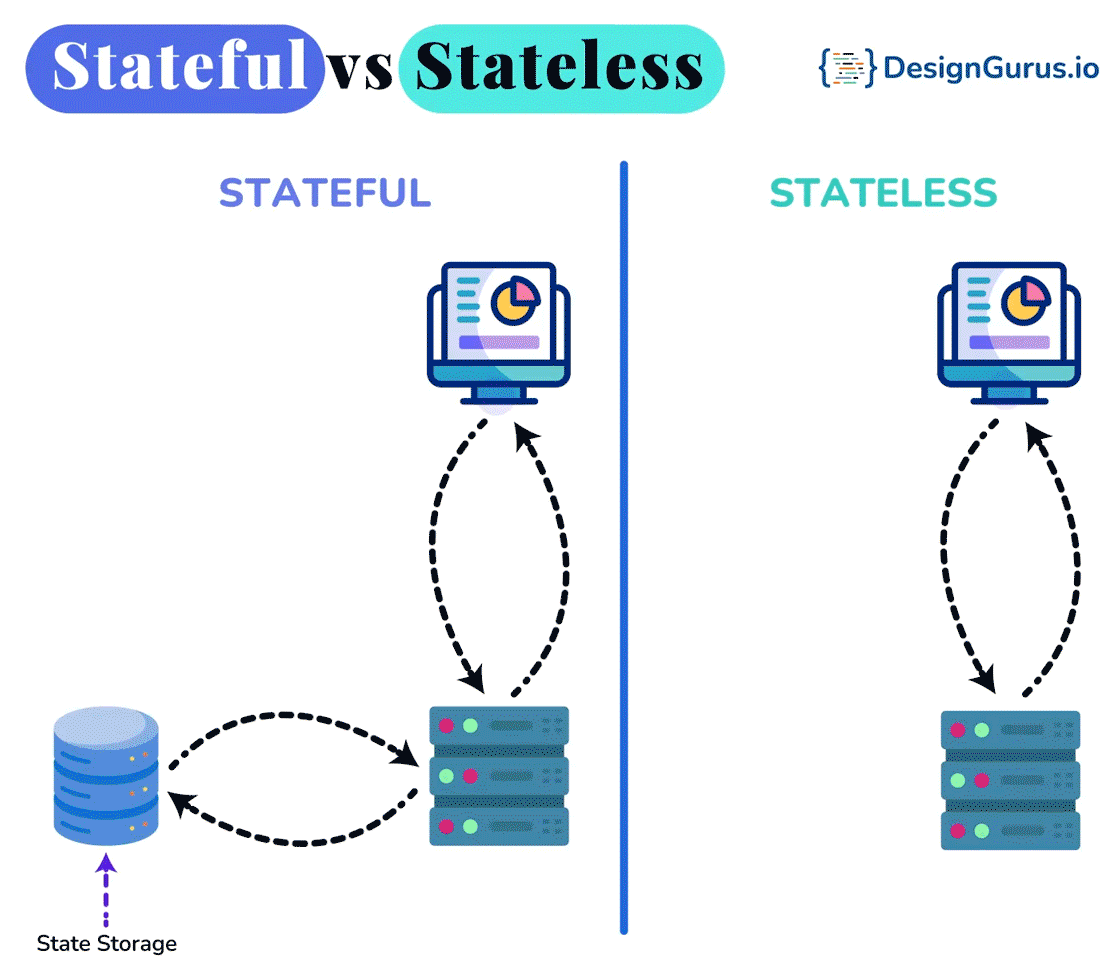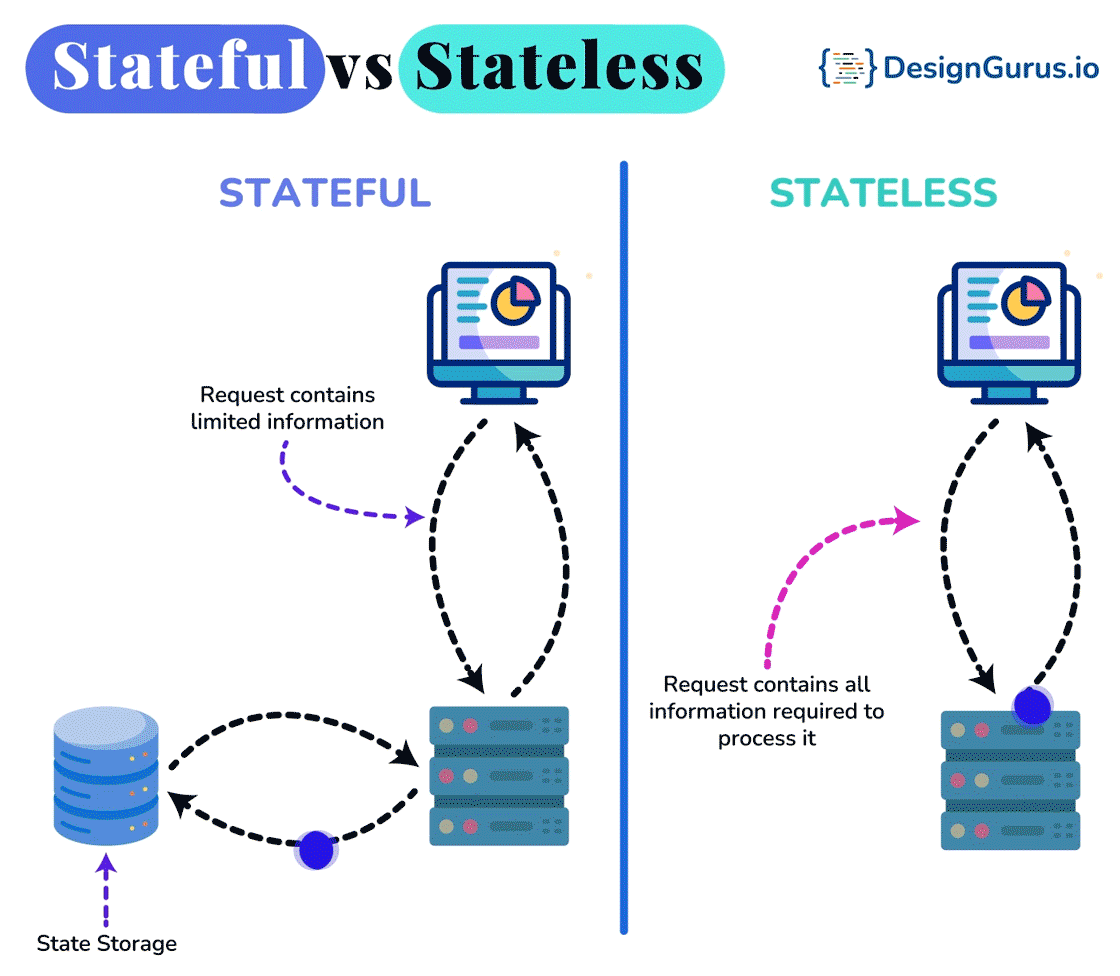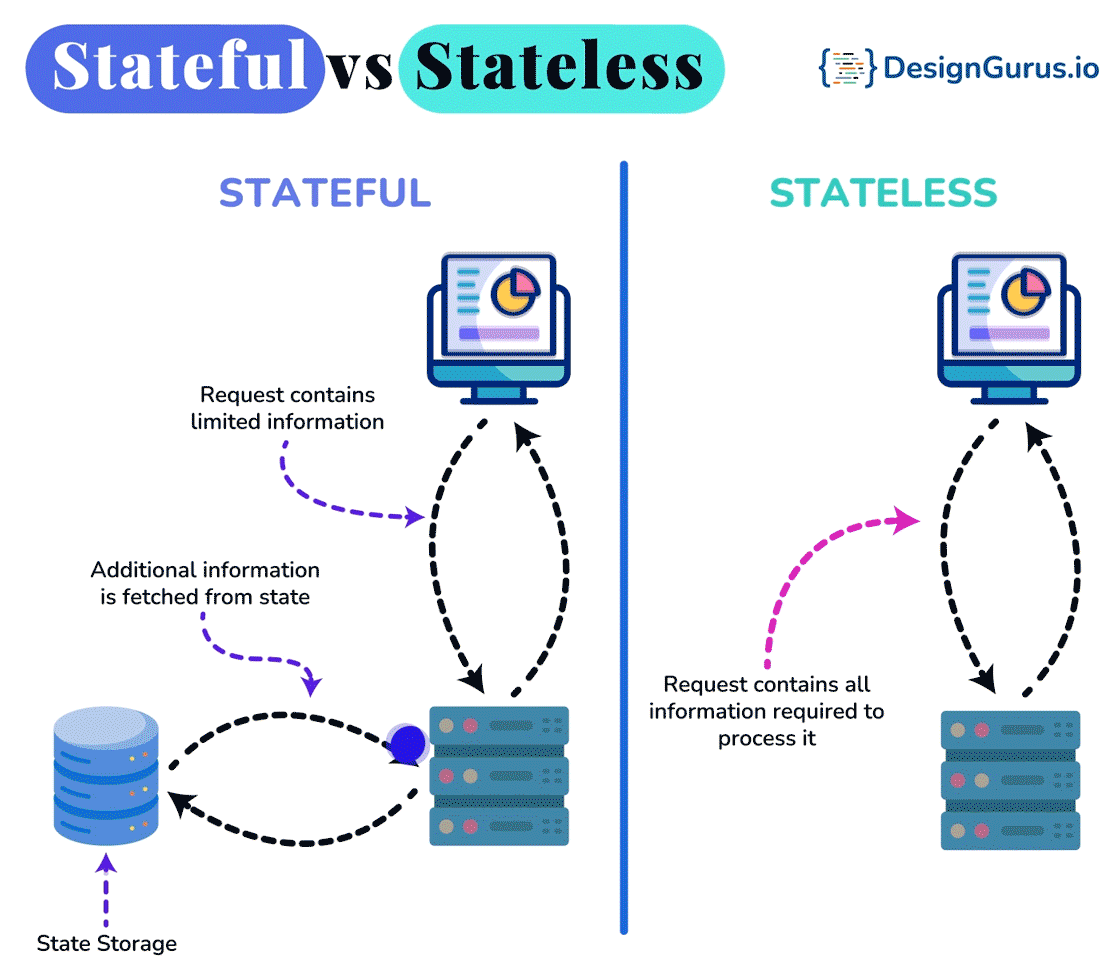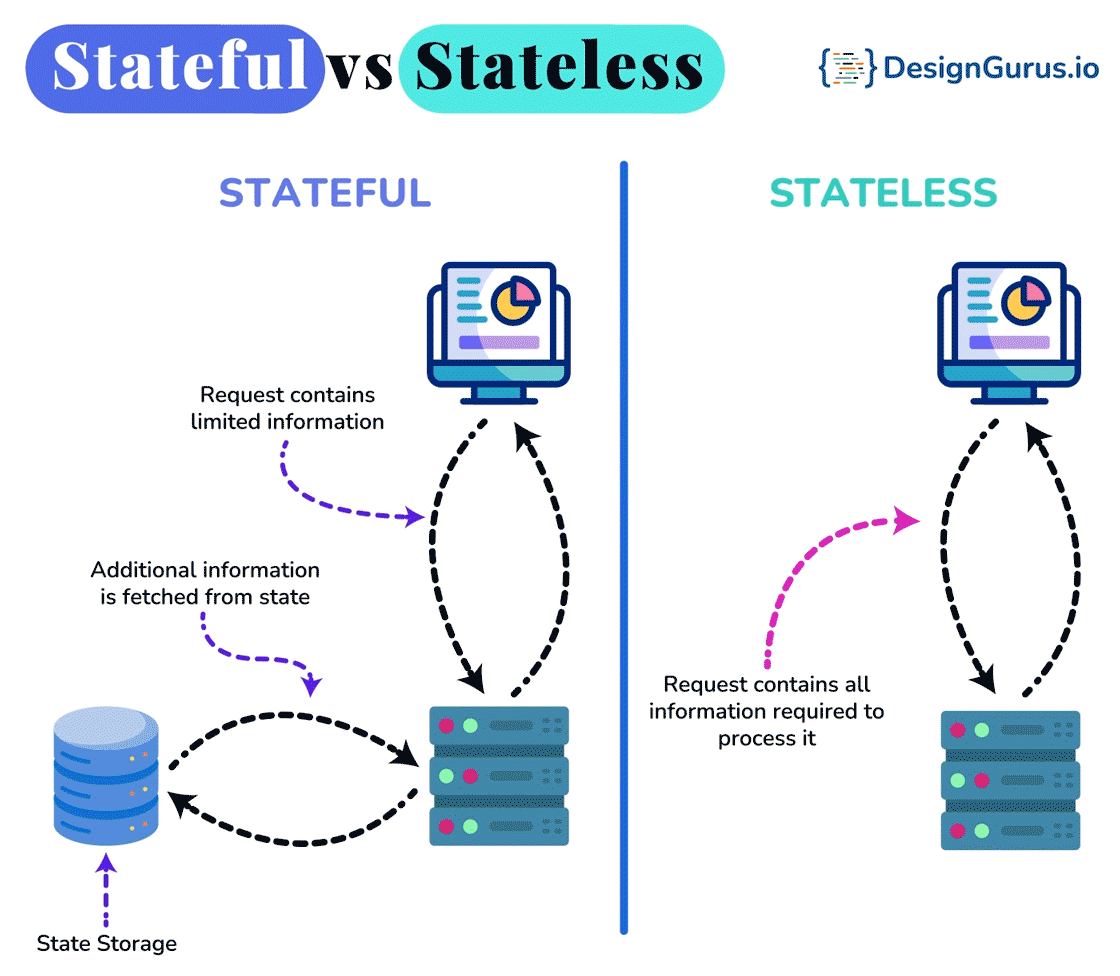
- ○Stateful vs Stateless Architecture
- ○EventDriven vs Polling Architecture
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 You need to store a 10 GB log file, but your biggest disk is 4 TB and a single machine maxes out at ~125 MB/s read. Why not just store the whole file on one node — what does splitting it into 128 MB chunks actually buy you?
Reveal the reasoning
Chain: a single-node file caps you on both capacity and throughput → split the 10 GB file into ~80 chunks of 128 MB each → scatter chunks across many machines → a client reading the file now pulls from many disks in parallel.
- Throughput: 1 disk at 125 MB/s reads 10 GB in ~82s; 80 disks reading their chunk in parallel finish in ~1s. Throughput scales with the number of disks you can spread the file across.
- Capacity: a 50 TB file no longer needs to fit on one 4 TB disk — it spreads across the cluster.
- Recovery: if a disk dies, you re-replicate the lost 128 MB chunks, not a whole monolithic 10 GB file, and the re-copies fan out across many source/target nodes in parallel.
Cost/trade-off: why 128 MB and not 4 KB like a normal OS block? Each chunk needs a metadata entry in the master's RAM. At 4 KB blocks, 10 GB = ~2.6M entries; at 128 MB, ~80 entries. Large chunks keep metadata tiny and cut the master's lookup load — but a 1 KB file still consumes a full metadata entry (though only ~1 KB of disk, since chunks aren't pre-padded), so the master's RAM, not disk, is what makes DFS terrible for billions of tiny files.
🤔 At 1,000 disks with a ~2% annual failure rate, you'd expect ~20 disk failures a year — a disk dying every couple of weeks, and far more often once you scale to tens of thousands. If each chunk lived on exactly one disk, what happens — and how does keeping 3 copies fix it without you noticing the failure?
Reveal the reasoning
Chain: 1 copy per chunk → any disk death = permanent data loss + a read that returns an error. Instead, write each chunk to 3 machines (the GFS/HDFS default), placed on at least two different racks.
- Disk dies → master notices the chunk is now under-replicated (2 copies) → it schedules a copy of the chunk onto a fresh node, restoring 3 → zero data loss, reads keep working from the surviving 2.
- The danger window is the minutes between a disk dying and re-replication finishing. For data loss you'd need all 3 copies to fail inside that same window. Treating failures as independent, that's ~(0.02)³ ≈ 8 in a million — and rack-aware placement makes a correlated event (a rack/switch/power failure taking out copies together) far less likely than the independent estimate.
Cost/trade-off: 3x replication means 3x raw storage — store 1 PB of data, buy 3 PB of disk — and every write must land on 3 disks. This is why cold/archival data often switches to erasure coding (e.g. Reed–Solomon 6+3: 6 data + 3 parity shards), which also tolerates 3 simultaneous shard losses but at only ~1.5x overhead instead of 3x. The catch: reconstructing a lost shard requires reading 6 other shards and doing CPU-heavy math, so recovery and degraded reads are much more expensive than replication's plain copy.
🤔 The cluster has 1,000 machines holding chunks. When a client wants /logs/april.txt, who tells it which machines hold its ~80 chunks? Why route that lookup through one dedicated master node instead of letting clients ask the data nodes directly?
Reveal the reasoning
Chain: split responsibilities → one master/NameNode holds only the metadata (the file→chunk→location map) → many chunkservers/DataNodes hold only the bytes.
- Client asks master: "where is
/logs/april.txt?" → master replies with the chunk IDs and the 3 locations of each → client then streams bytes directly from the data nodes. - Crucially, the master is out of the data path — the multi-gigabyte transfer never flows through it. The master only serves the tiny lookup, then steps aside.
- All hot metadata (file tree, chunk map) lives in master RAM → lookups are memory-speed, not disk seeks, so one master can serve a large cluster.
Cost/trade-off: the master becomes a single point of failure and a scaling ceiling — the namespace must fit in one machine's RAM. As a concrete rule of thumb, an HDFS NameNode uses on the order of ~150 bytes of RAM per object (file or block), so tens of GB of heap holds a few hundred million objects, no more. It's defended with a hot standby plus an operation log that the standby replays, but namespace size is hard-capped by RAM. (HDFS Federation later partitioned the namespace across multiple NameNodes to push that ceiling higher.)
🤔 A client writes a chunk that must land on all 3 replicas. If the client sent the data to all 3 in parallel and each applied it the instant it arrived, what could go wrong — and how does a designated primary replica fix the ordering?
Reveal the reasoning
Chain: concurrent writers + independent replicas → replicas could apply mutations in different orders → the 3 copies diverge and are no longer byte-identical. Fix: the master grants one replica a time-limited lease, making it the primary that defines the order.
- Data flow (push): the client pushes the bytes to the nearest replica, which pipelines them to the next, then the next — bytes stream along the chain so every link's bandwidth is used and the data is buffered on all 3 before any commit.
- Control flow (order): once all 3 have the bytes buffered, the client sends the write request to the primary. The primary assigns a serial order, applies it locally, and forwards that same order to the 2 secondaries to apply.
- The write succeeds only after all 3 secondaries+primary ack → all copies converge on identical state.
Cost/trade-off: the write is only as fast as the slowest of the 3 replicas (tail latency drags the whole write), and if a replica fails mid-commit the client retries, which can leave duplicate or padded records in the chunk. GFS deliberately exposes only at-least-once record-append semantics, pushing dedup/idempotency up to the application rather than paying for stronger guarantees in the storage layer.
🤔 The master must know which of 1,000 data nodes are alive. Why have each node push a small "I'm alive" heartbeat every few seconds, instead of the master actively polling all 1,000 nodes on a timer?
Reveal the reasoning
Chain: master polling 1,000 nodes on a tight loop → 1,000 outbound RPCs every cycle → the master burns its scarce CPU/network on liveness checks instead of serving lookups, and the cost grows O(N) on the one bottleneck node. Invert it: each node pushes a heartbeat (every ~3s in HDFS) carrying its status, and periodically a full block report of the chunks it holds.
- Master just receives heartbeats and resets a per-node timer → tracking liveness is near-free for the bottleneck node.
- No heartbeat for ~10 missed intervals (~30s in HDFS's default) → master marks the node dead → it schedules re-replication of every chunk that node held.
- This is the push/event-driven vs pull/polling trade applied to failure detection: the work scales onto the 1,000 nodes (each does a trivial amount), while the bottleneck (master) only reacts to events.
Cost/trade-off: detection is not instant — a node can be dead for ~30s before the master reacts, and reads aimed at it during that window must fail over to its other replicas. Shorten the timeout and you risk declaring a node dead during a long GC pause or a transient network blip, triggering a needless re-replication storm that floods the network copying chunks that were never actually lost.
🤔 Why are DFS clients deliberately near-stateless (they cache a chunk location, then can throw it away), while the master is the one authoritative stateful brain? What breaks if you tried to make every node stateless?
Reveal the reasoning
Chain: someone must remember the file→chunk→location mapping — that's irreducible state. Concentrate the authoritative copy in one stateful master and keep everyone else effectively stateless, so failures of the many are cheap.
- Near-stateless clients hold no authoritative state — they cache a chunk's location for a short TTL, and if it's stale (the chunk moved or its node died) the read fails, the client simply re-asks the master and retries. A crashed client loses nothing the system needs.
- Stateful master must durably persist its metadata: it appends every namespace change to an operation log on disk and replicates that log, and periodically writes a checkpoint of the in-RAM state. On restart it loads the latest checkpoint and replays the tail of the log to rebuild RAM state.
- Chunk locations are deliberately not persisted in the log — the master rebuilds the location map from the block reports nodes send when they (re)join. Less to persist, and the rebuilt map can't go stale relative to reality.
Cost/trade-off: the stateful master needs heavyweight machinery the stateless nodes don't — durable log writes (each metadata op pays a disk sync/replication round-trip before it's acknowledged), a hot standby kept in sync, and a leader-election/failover protocol. The lesson: statelessness is cheap to scale and recover, statefulness is expensive — so you minimize it and isolate it to one well-defended place.
🤔 Every node periodically sends a block report listing all its chunk IDs to the master. A node with 50,000 chunks, times 1,000 nodes, repeated continuously — would you encode that report as human-readable JSON/XML, or as a compact binary format like Protobuf? And why might the answer flip for a public-facing API?
Reveal the reasoning
Chain: a node holding 50,000 chunks sends 50,000 IDs; 1,000 nodes do this repeatedly → this is hot internal machine-to-machine traffic on the critical path to the bottleneck master, where bytes-on-the-wire and parse CPU dominate.
- Text (JSON/XML): a 64-bit chunk ID becomes ~19–20 ASCII digits instead of 8 binary bytes, and the parser must scan delimiters and convert ASCII→int for every field. JSON runs roughly 2–3x larger than packed binary here (XML is worse — closing tags and attribute names inflate it further). At 50,000 IDs per node that's the difference between a report of a few hundred KB and ~1 MB, multiplied by every node, every cycle.
- Binary (Protobuf/Thrift/Avro): fixed-width or varint-packed IDs, no field-name repetition, near-zero parse cost. The master spends its CPU on real work instead of string parsing. This is why GFS/HDFS use compact RPC encodings internally.
Cost/trade-off: binary buys size and speed but costs human-debuggability and loose coupling — you can't curl it and eyeball it, and both sides must share a schema and stay version-compatible. That's exactly why the answer flips for a public API: there, the consumers are external and unknown, developer ergonomics and easy debugging beat raw efficiency, so human-readable JSON usually wins. The rule of thumb: binary for hot internal paths you control both ends of; text for public, low-volume, human-facing interfaces.
📐 Architecture diagrams (2)

🎯 Guided practice
- Easy — Sizing the metadata. A DFS stores 10 million files split into 128MB blocks; total data is 5 PB at replication factor 3. Roughly how many block replicas exist, and where does the master's memory pressure come from?
Step 1: Logical blocks = 5 PB / 128 MB = (5 x 2^50) / (128 x 2^20) = 5 x 2^23 ≈ 42M logical blocks.
Step 2: With replication 3, physical replicas ≈ 42M x 3 ≈ 126M block replicas, and physical storage ≈ 15 PB (3x overhead).
Step 3: The master keeps in RAM: per-file metadata (name, permissions, block list) plus the file->block map; block->location is also in RAM but rebuilt from DataNode reports, not persisted. Memory scales with number of files + number of blocks, NOT with total bytes — each costs a fixed-size record (~150 bytes in HDFS) regardless of file size. So 10M tiny files hurt the master far more than a few huge files: the textbook small-file problem. Pattern learned: metadata count is the scaling axis; data volume is not.
- Medium — Choosing the durability scheme. Your cold archive is 100 PB, rarely read, and must survive any 2 simultaneous failures while minimizing storage cost. Compare 3x replication vs erasure coding.
Step 1 (replication): 3 copies survive 2 failures, but storage = 3 x 100 PB = 300 PB (200% overhead). Fast reads, cheap repair (copy one surviving replica), but expensive to store.
Step 2 (erasure coding): Reed-Solomon RS(k,m) splits data into k data + m parity fragments and tolerates any m losses. To survive 2 failures pick m=2, e.g. RS(6,2): overhead = (6+2)/6 ≈ 1.33x -> only ~133 PB. Same fault tolerance as 3x replication at well under half the storage.
Step 3 (the trade-off): EC is cheaper to store but expensive to repair — reconstructing one lost fragment requires reading k surviving fragments across the network, multiplying rebuild traffic and read latency on degraded reads. Hence the rule: hot / latency-sensitive data -> replication; cold / rarely-read data -> erasure coding. This archive is cold and read rarely, so choose RS erasure coding (real systems do exactly this: HDFS-EC and Facebook's f4 use RS(6,3)/RS(10,4) for warm/cold tiers). Pattern learned: durability is a cost / latency / repair-bandwidth trade matched to the access pattern — that matching is the FAANG-level judgment call, not memorizing one fixed answer.
✨ Added by the guide — work these before the full problem set.