Scalable Systems (Advanced Topics)
Step 28 in the System Design path · 48 concepts · 3 problems
📘 Learn Scalable Systems (Advanced Topics) from zero
System design interviews aren't about reciting facts — they're about reasoning under constraints out loud. The interviewer wants to see you start from requirements and scale, derive estimates, then make justified trade-offs at each layer (caching, load balancing, data model, replication). For each decision below, force yourself to answer the question BEFORE revealing the reasoning. The goal is to internalize the cause→effect→cost chain so that in the room you can say "I'd add X because Y, but it costs me Z" — which is exactly what separates a hire from a no-hire.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○What Is Negative Caching and When Should You Cache 404 or Empty Results
- ○How Can a Bloom Filter Reduce Cache or Database Load
- ○What Is Distributed Locking for Cache Rebuilds, and How Does It Prevent Cache Stampedes
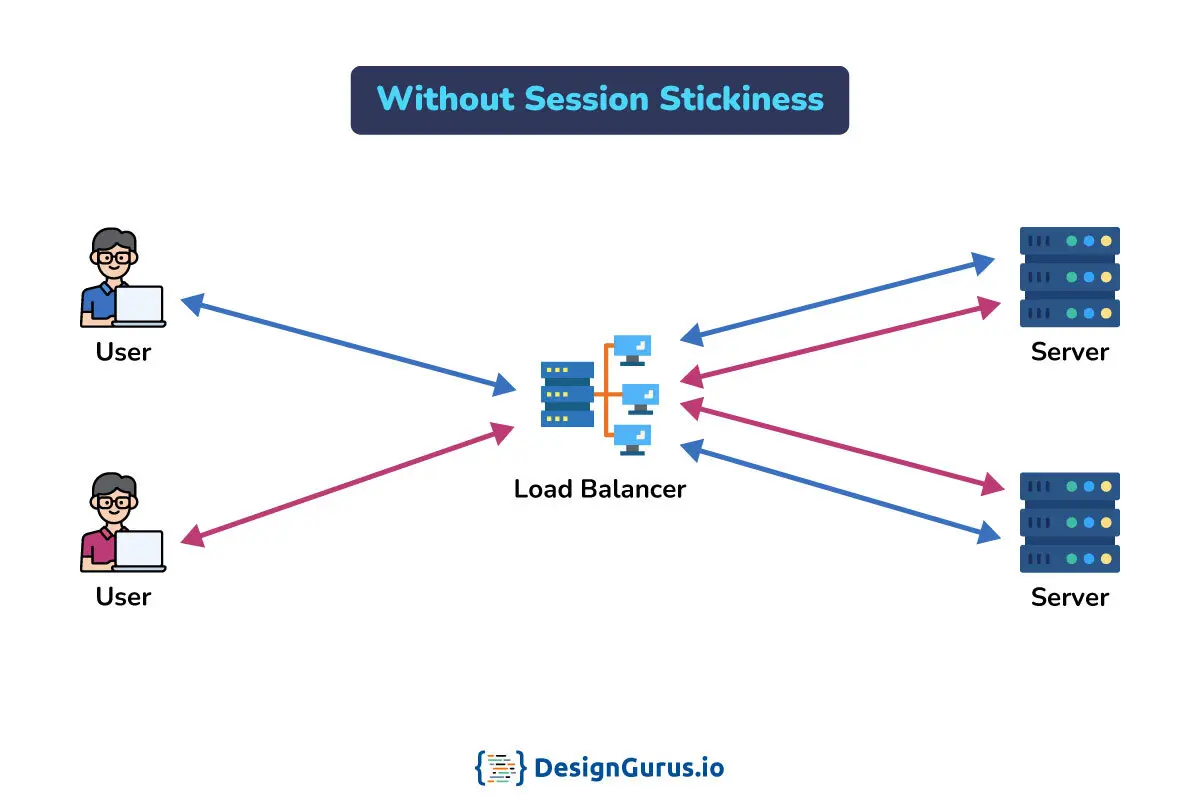
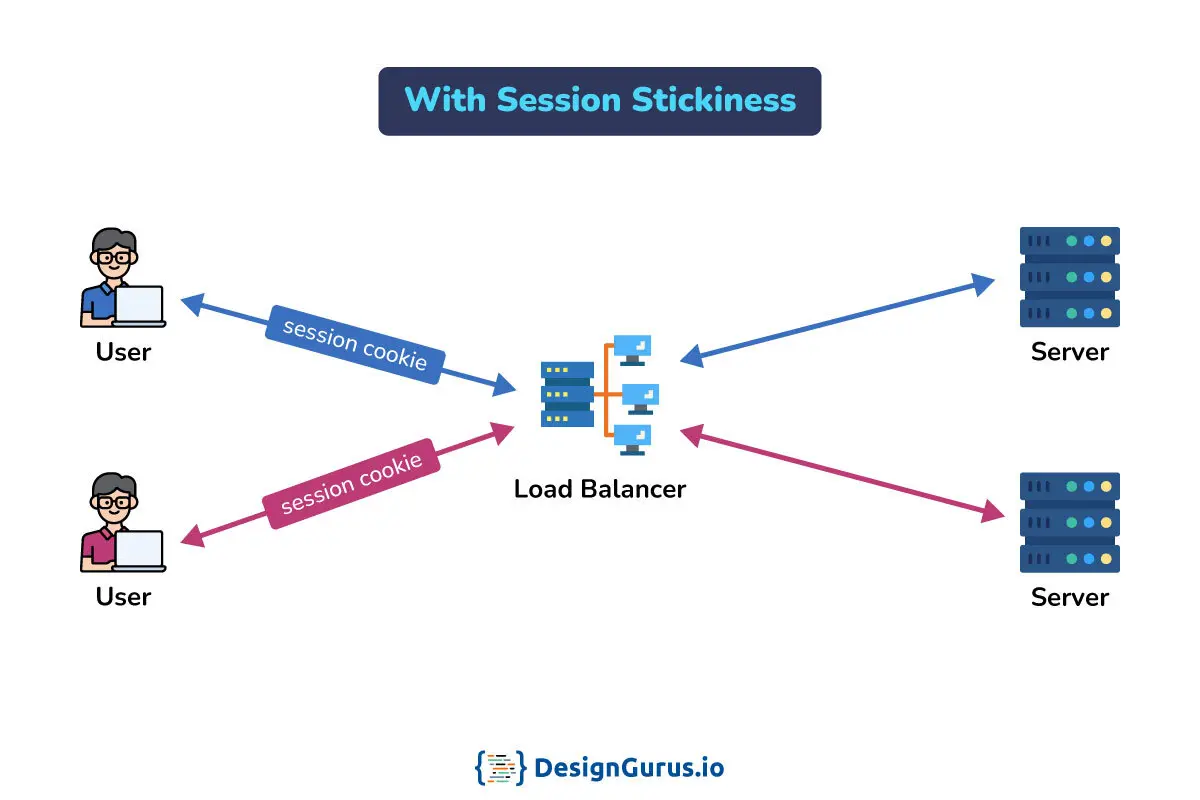
- ○What Are Sticky Sessions Session Affinity and When Should I Avoid Them
- ○What Is the Difference between Liveness Checks and Readiness Checks in Load Balancers
- ○What is Global Server Load Balancing GSLB and How GeoDNS and Anycast Work
- ○What are the Main API Pagination Strategies offset, cursor, keyset, and When Should I Use Each
- ○What are HTTP Conditional Requests ETag, If‑None‑Match, Last‑Modified and How They Reduce Load
- ○What Is the Difference between Rate Limiting and Throttling and Quotas
- ○What Are Idempotency Keys and How to Implement Them Safely for Payments
- ○What are SQL Isolation Levels Read Committed, Repeatable Read, Serializable, and What Anomalies Do They Prevent
- ○What Is a Write‑Ahead Log WAL, and How Does It Ensure Durability
- ○What Is the Difference Between Synchronous and Asynchronous Replication, and When Should I Use Read Replicas
- ○What Is MVCC Multi‑Version Concurrency Control, and How Does It Enable Concurrent Reads and Writes
- ○What Are Safe Patterns for Online Schema Changes vs
- ○What is Little’s Law and How to Use It for Quick Capacity Estimates in System Design
- ○How Can I do Back-of-the-Envelope Sizing for QPS, Bandwidth, Storage, and Peak vs
- ○What are Cold Starts and Warm Starts, and Why Do They Matter for Performance
- ○How Do I Choose a Good Shard Key and Avoid Hotspots Bucketing and Key Randomization
- ○What Are Range Sharding, Directory‑Based Sharding, and Geo‑Sharding, and What Are the Common Use Cases
- ○What Is the Difference Between Rendezvous Hashing and Consistent Hashing, and When Should I Use Each
- ○What Do At‑most‑once, At‑least‑once, And Exactly‑once Delivery Semantics Mean
- ○What Are Idempotent Producers And Consumers, And How Do De‑duplication Keys Work
- ○What Is Message Ordering, How Do Partition Keys Affect It, And When Can Ordering Break
- ○What Are Windowing And Watermarking In Streaming Systems, In Simple Terms
- ○What Is Quorum N, R, W, And Why Does R W N Give Strongly Consistent Reads
- ○What Are Read Repair, Hinted Handoff, And Anti‑entropy Merkle Trees In Eventually Consistent Systems
- ○What Is The Difference Between SLI, SLO, And SLA, And Can You Give Simple Examples
- ○What Is Opentelemetry, And How Do Traces, Spans, Metrics, And Logs Fit Together
- ○What Is An Error Budget, And How Should It Guide Release Decisions
- ○What Are The Trade‑offs Between Server‑stored Sessions And JWTs for Authentication
- ○What Is The Difference Between TLS And MTLS, And When Is MTLS Appropriate For Service‑to‑service Auth
- ○What Is Secrets Management, And How Do Environment Variables, KMS, And Vault Compare
- ○What Is A Replay Attack, And How Is It Different from Idempotency Issues
- ○What Are The Differences Between TCP, UDP, And QUIC, And When Should I Use Each
- ○What Is The Difference Between A Forward Proxy, A Reverse Proxy, And NAT
- ○What Changed From HTTP1.1 To HTTP2 To HTTP3, And What Are Head‑of‑line Blocking And Multiplexing
- ○What Is the Difference Between Content‑Addressable Storage and Location‑Based Addressing
- ○What Are Checksums and Etags, and How Do MD5SHA Compare to CRC for Integrity
- ○What Are Hot, Warm, Cold, and Archive Storage Tiers, and When Should I Use Each
- ○What Is the Outbox Pattern, and How Does Change Data Capture CDC Work at a High Level
- ○What Is CQRS Command Query Responsibility Segregation, and When Should I Consider It
- ○What Are the Differences Between a Circuit Breaker, Retry With Backoff, and Rate Limiting
- ○What Are RPO and RTO, and How Do They Differ in Disaster Recovery Planning
- ○What Is the Difference Between Active‑Active and Active‑Passive Architectures
- ○What Is Graceful Degradation, and How Do Feature Flags Help Availability
- ○What Are the Differences Between UUID, ULID, KSUID, and Snowflake IDs, and How Do I Choose
- ○How Do Snowflake‑Style IDs Work Timestamp, Worker, Sequence, and What Problems Do They Solve
- ○hard What Is the Difference Between Soft TTL and Hard TTL, and Why Does It Matter
- ○hard What Is the Difference Between Wall‑Clock Time and Monotonic Time, and Why Is Clock Skew
- ○What Are Common Conflict Resolution Strategies Last‑write‑wins, Vector Clocks, Logical Clocks
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 Before drawing a single box, what's the FIRST thing you ask? Design a product-catalog read API: how do you turn "build it" into a sized problem?
Reveal the reasoning
Functional vs non-functional split, then numbers. Pin down:
- Functional: read product by ID, list with pagination, search.
- Non-functional: read-heavy (say
100:1read:write), p99 latency target<100ms, availability99.9%(= ~43 min/month downtime budget). - Scale: 100M products, 50M DAU, each user does ~20 reads/day.
Chain: stating read-heavy → justifies caching + read replicas later → which justifies eventual-consistency trade-offs. Cost of skipping this: if you don't fix the read:write ratio now, every later decision (cache, replication mode) is unanchored and the interviewer can't tell if your design fits. The trade-off you're implicitly accepting: optimizing for reads means writes get slower/more complex.
🤔 50M DAU × 20 reads/day. What's your average QPS, your PEAK QPS, and roughly how much egress bandwidth — and how many app servers does that imply via Little's Law?
Reveal the reasoning
QPS chain: 50M × 20 = 1B reads/day. ÷ 86,400s ≈ ~11,600 QPS average. Apply a peak factor of ~3× (traffic isn't uniform; daytime spikes) → ~35,000 QPS peak. Always size for peak, not average.
Bandwidth: if each response is ~2 KB, 35,000 × 2 KB ≈ 70 MB/s ≈ 560 Mbps egress at peak — well within a single load balancer's capacity, but worth stating.
Little's Law (L = λ × W): concurrency = arrival rate × service time. At 35,000 QPS with 20ms service time → L = 35,000 × 0.02 = ~700 in-flight requests. If one server handles ~200 concurrent requests comfortably, you need ~4 servers for compute, then round UP to 6–8 for failure tolerance + headroom. Cost: these are order-of-magnitude, not exact — the trade-off is speed of estimation over precision, which is correct for an interview but means you must validate with load tests in reality.
🤔 The "list products" endpoint returns 100M rows over time. A junior reaches for OFFSET 50000 LIMIT 20. Why is that a trap at scale, and which pagination strategy do you pick — offset, cursor, or keyset?
Reveal the reasoning
Why offset fails: OFFSET 50000 forces the DB to scan and discard 50,000 rows before returning 20 → cost grows linearly with page depth (O(offset)). Deep pages get unusably slow. It also double-shows or skips rows when items are inserted/deleted mid-pagination, because the offset shifts.
The strategies:
- Offset: simple, allows jump-to-page-N, but slow on deep pages and unstable under writes. Fine for small/admin tables.
- Keyset (seek):
WHERE id > :last_id ORDER BY id LIMIT 20— uses the index to seek directly, so each page isO(log n)to locate regardless of depth. Stable under inserts. Trade-off: no random jump-to-page, only next/prev. - Cursor: keyset wrapped in an opaque encoded token (e.g. base64 of the sort key) so the client can't tamper with it and you're free to change the underlying ordering. Trade-off: slightly more server-side complexity.
Pick: cursor/keyset for the public infinite-scroll feed. Cost: you give up arbitrary page jumps — acceptable because users scroll, they don't jump to page 2,500.
🤔 Two requests read stock=1 and both try to buy. At which SQL isolation level does this oversell, and what actually prevents it? Separately — when the DB says "committed," what on-disk mechanism guarantees the write survives a crash?
Reveal the reasoning
Isolation chain:
- Read Committed (Postgres default): blocks dirty reads, but allows non-repeatable reads. Two transactions each
SELECT stock=1, each then decrement → a classic lost update → oversell. - Repeatable Read: in Postgres this is snapshot isolation. It catches a concurrent UPDATE of the same row (one txn aborts with a serialization failure). But the read-then-write pattern above — separate SELECT, then UPDATE — is NOT fully protected unless you take an explicit lock; that's the subtle gap candidates miss.
- Serializable: behaves as if txns ran one-at-a-time and catches read-write conflicts (incl. phantoms) via SSI. Cost: more serialization-failure aborts/retries and lower throughput under contention.
SELECT ... FOR UPDATE (explicit row lock) or run the txn at Serializable. Trade-off: correctness bought with reduced concurrency on hot rows.MVCC is why readers don't block writers: each row keeps multiple versions, so a reader sees a consistent snapshot while a writer creates a new version. Cost: dead versions accumulate → you must VACUUM/garbage-collect them.
Durability (WAL): before the data page is flushed, the change is appended to the Write-Ahead Log and fsync'd to disk. "Committed" means "the commit record is in the WAL on disk." On crash, the DB replays the WAL to recover. Cost: the fsync adds latency per commit — mitigated by group commit / battery-backed write cache, but you can't escape the durability-vs-latency trade-off.
🤔 At 35,000 QPS, hitting the DB directly is suicidal. You add Redis in front. Two follow-ups: a popular item's cache entry expires and 10,000 requests hit at once — what happens? And what do you cache for a product ID that DOESN'T exist?
Reveal the reasoning
Cache stampede chain: entry expires → all 10,000 concurrent requests miss → all 10,000 hammer the DB to rebuild the SAME key → DB overload / cascading failure. Fix: lock on rebuild — the first request acquires a lock (e.g. Redis SET key val NX EX with a short TTL), rebuilds, and repopulates; the other 9,999 either wait briefly or serve slightly-stale data. Cost: added lock complexity + you must handle the lock-holder crashing mid-rebuild (that's exactly why the lock has a TTL).
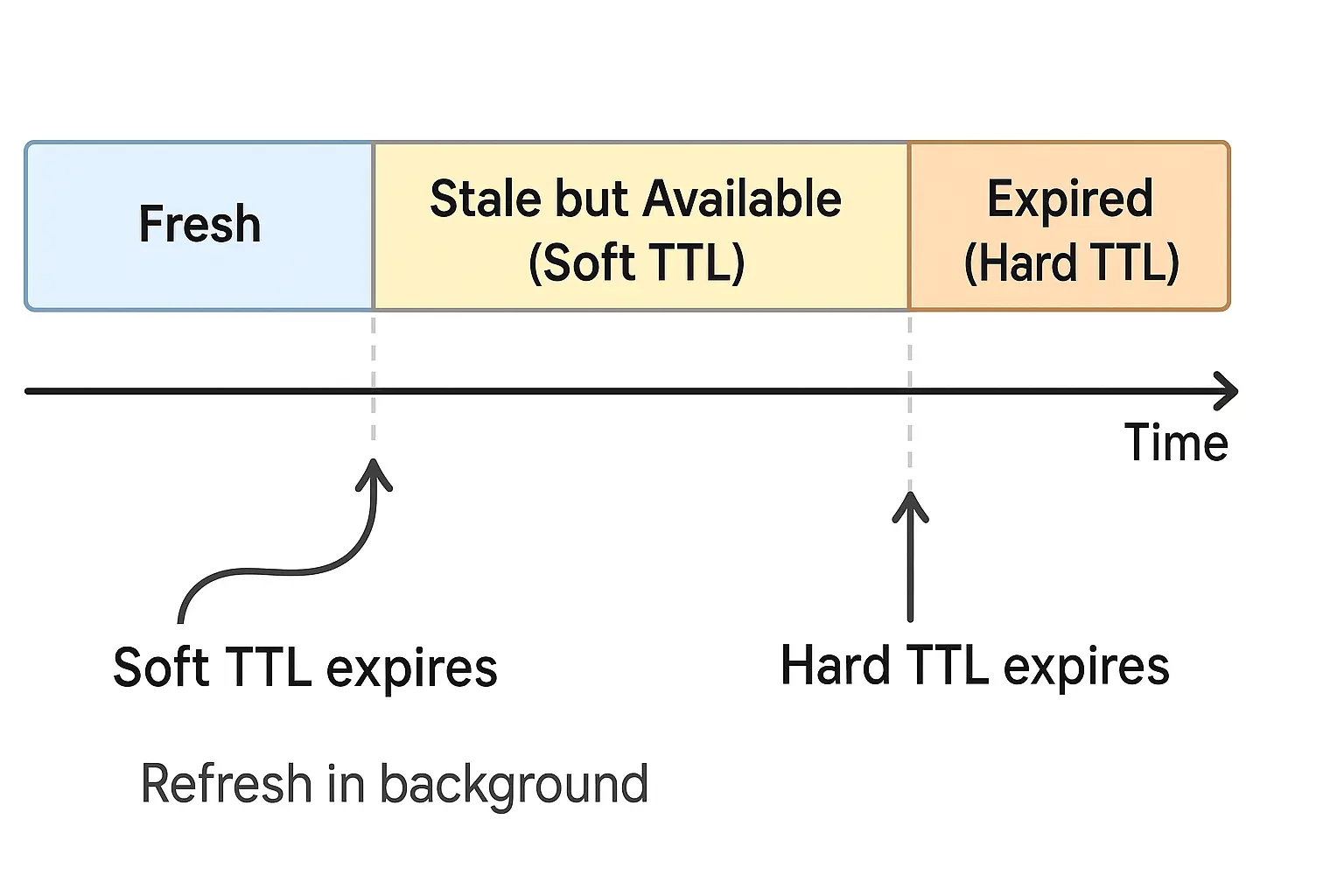
Soft TTL vs hard TTL: at the soft TTL the value is "stale but still served" — one request triggers an async background refresh while everyone keeps getting the slightly-old value; only past the hard TTL do you block and force a synchronous rebuild. This smooths stampedes by removing the hard expiry cliff. Cost: users may briefly see data that's seconds stale.
Negative caching: for a non-existent product ID, cache the 404/empty result with a SHORT TTL (e.g. 30s). Otherwise clients (or attackers) requesting missing IDs miss the cache every time and pound the DB. Cost: if that item is created right after, it stays invisible for up to the negative TTL — so keep the TTL short.
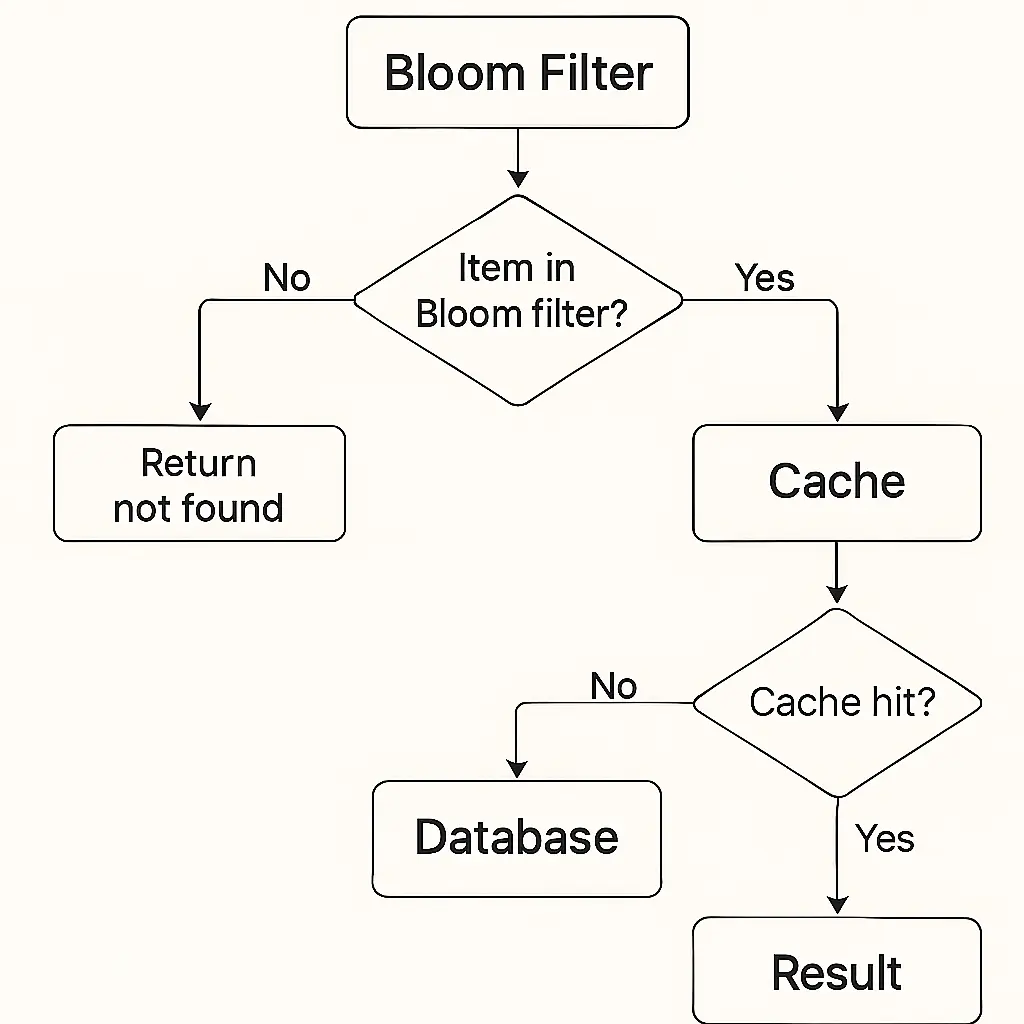
🤔 Even with negative caching, a flood of random non-existent IDs still costs a cache lookup each. How can a tiny probabilistic structure reject most of them BEFORE the cache? And separately — repeat clients re-download the same 2 KB product they already have; how do you avoid re-sending the body?
Reveal the reasoning
Bloom filter chain: keep an in-memory bitset built from all 100M existing product IDs. On lookup, check the filter first → if it says "definitely not present," you skip BOTH cache and DB. A Bloom filter has zero false negatives (it never says "no" for an item that exists) and a tunable false-positive rate (~10 bits/element gives ~1% FP and needs ~125 MB for 100M IDs). So ~99% of bogus IDs are rejected in microseconds. Cost: you can't delete from a standard Bloom filter (you'd need a counting or cuckoo variant), and the ~1% false positives still fall through to the normal cache/DB path — safe, just not free.
HTTP conditional requests: respond with an ETag (content hash) and/or Last-Modified. The client re-requests with If-None-Match: <etag> → if unchanged, the server returns 304 Not Modified with an EMPTY body. Chain: a 2 KB body collapses to a ~tens-of-bytes 304 → big egress savings on hot, rarely-changing items. Cost: you still pay the network round-trip plus a cheap hash/compare, so the ETag must be cheap and stable to compute.
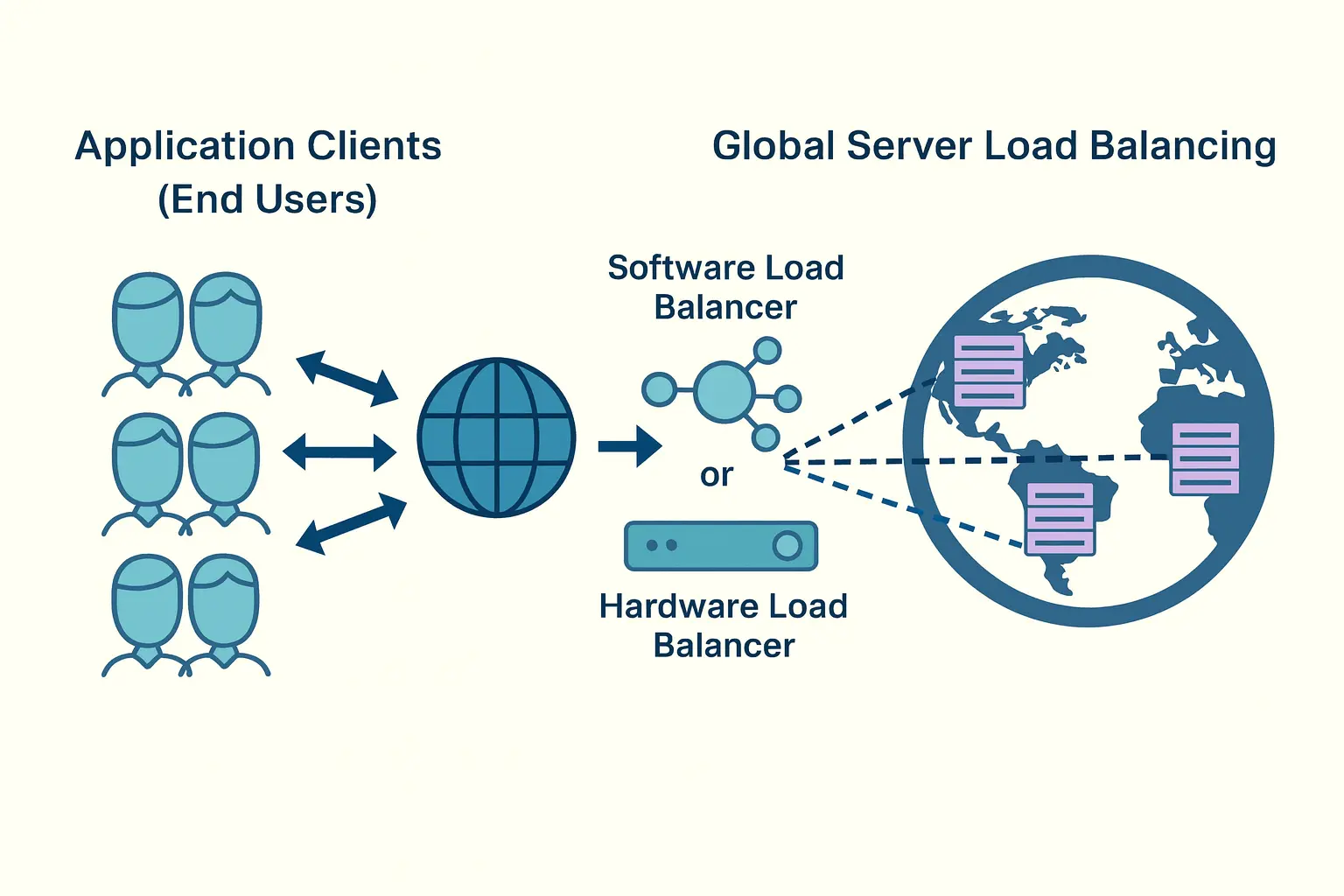
🤔 You're now global with servers in US + EU. Two questions: how does a user in Berlin automatically hit the EU region? And why must your load balancer distinguish "is the process alive?" from "is it ready for traffic?"
Reveal the reasoning
GSLB / GeoDNS chain: the same hostname resolves to different IPs based on the resolver's location (or via anycast) → a Berlin user is steered to the EU IP, cutting RTT (e.g. ~120ms cross-Atlantic down to ~20ms in-region). The regional LB then spreads load across healthy app servers. Cost: DNS-based routing is coarse and slow to fail over because resolvers cache answers for the record's TTL, so a dead region can keep receiving traffic until caches expire — you mitigate with low TTLs (which raises DNS query volume) or health-aware anycast.
Liveness vs readiness: liveness = "is the process running?" — if it fails, the orchestrator RESTARTS the pod. Readiness = "can it serve traffic right now?" — if it fails, the LB just stops ROUTING to it without killing it. Why both: a server that's alive but still warming caches, replaying WAL, or draining connections is live-but-not-ready; routing to it would serve errors or slow responses, while restarting it would be wasteful and reset its warm-up. Cost: two probe types plus tuning intervals/thresholds — too aggressive and you flap healthy nodes out; too lax and you keep routing to broken ones.
🤔 One DB can't serve 35,000 QPS of reads, and 100M products won't fit/perform on one node forever. You add read replicas and then shards. What new bug does a read replica introduce, and what breaks the moment you shard?
Reveal the reasoning
Read replicas chain: route reads to async followers, writes to the leader → read throughput scales horizontally and the leader is offloaded. The bug — replication lag: a user writes to the leader, immediately reads from a lagging replica, and sees stale/old data ("read-your-own-writes" violation). Fixes: route a user's reads to the leader for a short window after their write, or use a replica that has caught up to the write's log position. Cost: you've traded strong consistency for read scalability — this is the eventual-consistency bill the read-heavy decision in step 1 set up.
Sharding chain: partition by a key (e.g. hash of product_id) across N nodes → each node holds 1/N of the 100M rows and 1/N of the write load, so storage and write throughput scale. What breaks: queries that span shards. A simple by-ID lookup hits one shard, but a global list/search or any cross-shard JOIN must scatter-gather across all shards and merge — and global ordering/pagination gets hard. Trade-off: pick the shard key to match your dominant access pattern (by-ID), and push search to a separate system (e.g. an inverted index) rather than fighting the relational shards. Cost: a bad shard key creates hot shards and is painful to change later, since it forces a re-shard / data migration.
📐 Architecture diagrams (8)



🎯 Guided practice
- Easy — Little's Law capacity check. A payment service handles
λ = 200requests/second, and each request holds a worker thread for an average ofW = 0.25s(250ms). How many threads are busy on average, and how many should you provision for peak?Step 1 — apply Little's Law:
L = λ × W = 200 × 0.25 = 50requests in flight at once, so ~50 threads busy on average.Step 2 — headroom for variance: averages hide bursts, and queueing latency blows up as utilization approaches 100% (M/M/1 wait scales like 1/(1−ρ)). So provision for peak (commonly 2–3× average) and keep target utilization ≤~70%:
50 × 3 / 0.7 ≈ 214threads. Pattern: L = λ × W turns a throughput target plus a latency budget into a concurrency (thread / connection-pool) size — then multiply by a peak factor and divide by target utilization. - Medium — quorum reads with R + W > N. You run a Dynamo-style store with
N = 3replicas and want reads that reliably see the most recent completed write while keeping writes reasonably fast. Pick R and W, and explain the trade-off.Step 1 — the rule: a read quorum is guaranteed to overlap the latest write quorum iff
R + W > N. With N=3 that meansR + W ≥ 4.Step 2 — why overlap forces freshness: if a write was acknowledged by W replicas and a read polls R replicas with R + W > N, then by pigeonhole the two sets share at least one node — so the read set includes at least one replica holding the newest value, and the client picks the highest version (timestamp / vector clock) among the R responses.
Step 3 — choose for a read-heavy workload:
W = 3, R = 1(3 + 1 = 4 > 3) makes reads hit one node (fast, cheap) but requires every replica up to write (any one down blocks writes). For write-heavy, flip toW = 1, R = 3. The canonical balanced default isW = 2, R = 2: it tolerates one node down for both reads and writes while preserving the overlap, which is why Dynamo-style systems default to it.Pitfall: R + W > N gives quorum-overlap consistency, not linearizability. It does not, by itself, resolve concurrent conflicting writes (you still need version vectors or last-write-wins to decide the winner), and edge cases — a partially-completed write, or sloppy quorums with hinted handoff — can still surface a stale read (this is the explicit DDIA caveat). Pattern: tune the (N, R, W) triple to slide along the consistency–availability–latency curve, but reach for stronger coordination (e.g. consensus) when you need true linearizability.
✨ Added by the guide — work these before the full problem set.