How Can a Bloom Filter Reduce Cache or Database Load
A Bloom filter is a space-efficient probabilistic data structure that quickly tests whether an element is in a set, allowing fast membership checks with a tiny chance of false positives.
In simpler terms, a Bloom filter can tell you if an item is definitely not in a set or probably in the set. It uses a clever bit array and multiple hash functions instead of storing full data, which makes it extremely memory-efficient and fast for lookups.
However, because it’s probabilistic, it may occasionally erroneously indicate an element is present (a false positive), though it will never miss an element that was actually added (no false negatives).
This trade-off of accuracy for efficiency is what gives Bloom filters their power in large-scale systems.
How Bloom Filters Work (Overview)
A Bloom filter works by hashing each item multiple times and marking bits in an array, creating a unique “fingerprint” for set membership:
-
Bit Array & Hash Functions: It maintains a fixed-size bit array (e.g. thousands or millions of bits, all initially 0) and a set of k independent hash functions. When you add an element, you feed it to each hash function and set the bits at those hash indices to 1. To query an element, you hash it with the same functions and check those bit positions: if any bit is 0, the item is definitely not in the set; if all bits are 1, then the item is possibly in the set (with some probability of a false positive).
-
No False Negatives: If an element was added, all its corresponding bits were set to 1, so later queries will always find those bits and report “might exist.” Thus, Bloom filters never falsely reject a present item.
-
Possible False Positives: Different items can overlap in the bits they set. If a queried item’s hash bits were all set by other items, the filter could incorrectly report “might exist” even if that item was never added. This false positive rate can be made arbitrarily low by tuning the filter size and number of hashes (more bits and hashes reduce collisions). For example, with optimal settings a Bloom filter needs only about 9.6 bits per element for a 1% false positive probability, which is far smaller than storing full keys.
-
Fast and Scalable: Checking membership is very fast on the order of O(k) operations (where k is small, e.g. 7 hash checks) which is effectively O(1) in practice. Bloom filter inserts and lookups don’t grow slower as the set grows, making them ideal for large-scale or streaming data. They use fixed memory and do not require dynamic resizing for inserts (though you must plan for an expected number of elements to keep the false positive rate low).
In summary, a Bloom filter acts like a super-compact checklist of items, one that might occasionally say “I think I’ve seen this” when it hasn’t, but never misses an item that is in the set.
This makes it a great tool when you need to quickly test membership and can tolerate a rare false alarm.
Common characteristics include being space-efficient, fast, and probabilistic, with the caveat that standard Bloom filters do not support removing items once added (unless using advanced variants like counting Bloom filters).
Advantages and Trade-offs
-
Memory Efficiency: Bloom filters use much less memory than storing the actual data or a full hash set. They only store a bit-pattern. For instance, systems like web browsers or databases can compress millions of entries into a Bloom filter of only a few megabytes.
-
Speed: Lookup time is constant and very fast due to simple hashing and bit checks (often implemented with efficient bit operations). This makes Bloom filters suitable for high-throughput scenarios (like query filtering, network routers, etc.).
-
Scalable for Big Data: Because of fixed-size bit arrays and no need to iterate over all elements, Bloom filters handle large n (number of elements) gracefully. You just need to choose an appropriate size to maintain the desired false positive rate.
-
False Positives: The main cost of a Bloom filter’s efficiency is the chance of false positives. If the filter says “item may exist,” you often need a secondary check (e.g. querying a database or cache) to confirm. The false positive probability increases as more elements are added or if the filter is undersized, but it can be kept very low with proper tuning. In practice, a well-designed Bloom filter can make false positives so rare that the performance gains far outweigh this inconvenience.
-
No Deletion: Standard Bloom filters can’t easily remove an element (since bits are shared among multiple items’ hashes). Specialized versions like Counting Bloom Filters add this capability at the cost of extra space. In many use cases (like caches or streaming data) deletion isn’t needed, or the filter is simply rebuilt periodically if needed.
Given these properties, Bloom filters are often used as front-line filters in systems. They quickly rule out items that definitely aren’t in a dataset, thereby avoiding expensive work, while letting through only those that have a chance of being present.
This behavior is exactly how Bloom filters help reduce load on caches and databases, as we’ll explore next.
How Bloom Filters Reduce Database Load
One of the most impactful uses of Bloom filters is to protect databases from unnecessary lookups.
In many applications, a surge of requests for data that doesn’t exist (or isn’t cached) can put heavy load on the database.
Bloom filters mitigate this by acting as a preliminary check before any database query is made:
-
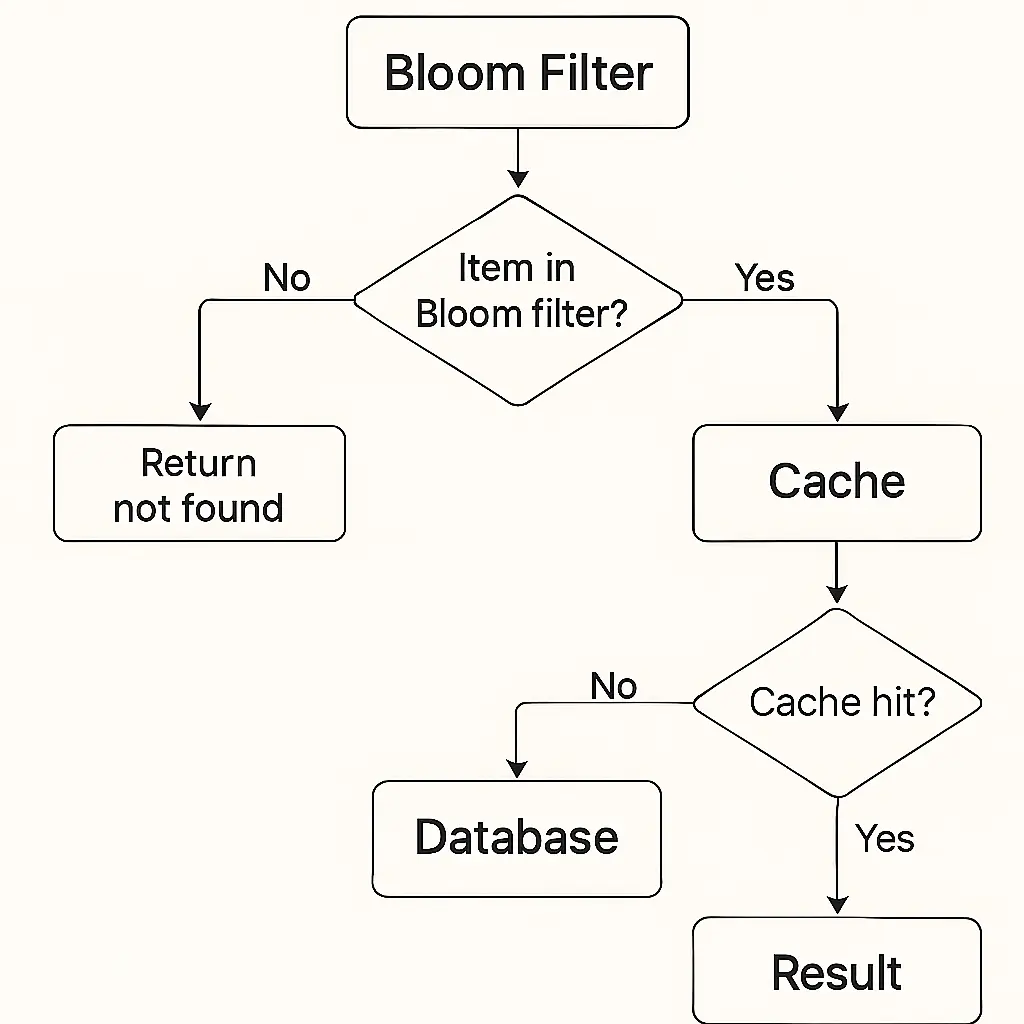
Preventing “Cache Miss” Storms: Consider a typical cache-aside design with a cache (like Redis or Memcached) in front of a database. Normally, when a user requests item X: the system checks the cache, and if it’s a miss, then queries the database. If X isn’t in the database either, the DB returns “not found.” This is fine for occasional misses, but if many requests come in for non-existent items, every request falls through to the database. The cache offers no relief (nothing was cached), and the database wastes time handling repeated “not found” queries. This scenario, which is often called cache penetration or a cache miss attack, can overload the database.
-
Bloom Filter as a Gatekeeper: To fix this, we introduce a Bloom filter containing all keys that actually exist in the database (or that have been seen before). Now the flow becomes: when a request for item X comes in, check the Bloom filter first. If the Bloom filter says “item X is definitely not present,” the system can immediately return a “not found” to the user without hitting the database at all. This filters out invalid or malicious queries up front. Only if the Bloom filter returns “X might exist” will the application proceed to check the cache and then the database.
-
Reduced Unnecessary Queries: Because the Bloom filter catches the majority of truly nonexistent keys, the database only sees queries for keys that have some chance of existing. This dramatically cuts down the volume of futile DB queries. In other words, the database is no longer burdened by every cache miss. It services far fewer requests, mainly legitimate ones.
Example: Imagine an e-commerce service where users occasionally request order IDs that don’t exist (typos or malicious guesses). Without a filter, each bad ID causes a database lookup (which returns nothing).
With a Bloom filter of all valid order IDs, the application can intercept invalid IDs.
If a user asks for order “99999999” and it’s not in the Bloom filter, the system skips any cache/DB lookup and returns “not found” immediately.
This saves the database from doing work. If another user (or a script) starts bombarding the system with random IDs, the Bloom filter will keep blocking those, preventing a DB overload.
Bloom filters are so effective in this role that many high-scale databases and distributed storage systems build them in.
For instance, Google Bigtable, Apache HBase, Cassandra, ScyllaDB, and PostgreSQL all use Bloom filters internally to avoid disk lookups for keys that don’t exist.
By skipping these costly disk reads for absent rows/columns, they greatly improve query performance and reduce load on the storage subsystem.
In summary, the Bloom filter acts like a query bouncer for the database: trivial “no such item” cases never reach the DB, and only plausible queries go through.
In practice, this strategy has been shown to significantly reduce database workload under heavy load or attack.
Even if the Bloom filter isn’t 100% accurate (false positives mean a few non-existent items might slip through), it stops the vast majority of invalid requests.
In summary, Bloom filters serve as an inexpensive upfront check that keeps databases from doing needless work, which translates to lower latency and better throughput.
How Bloom Filters Reduce Cache Load
Bloom filters can also be used to optimize caching systems themselves, by ensuring caches store only useful data and avoiding wasted capacity or I/O.
Two common scenarios illustrate this:
-
Avoiding “One-Hit-Wonders” in Web Caches: In content delivery networks (CDNs) or web proxy caches, a large fraction of cached items may be accessed only once and never again. These are known as one-hit-wonders, and storing them is wasteful. They consume disk space and bandwidth to cache data that no user will request again. A Bloom filter offers a clever solution: don’t cache an item on its first request. Instead, record that URL in a Bloom filter. Only if it’s requested a second time (the Bloom filter will then say “seen before”) do you actually cache the content. This way, one-hit items bypass the cache entirely on first access, and only popular items (those with repeat requests) get cached.
This approach was famously used by Akamai. They found that nearly 75% of objects in a typical web cache were one-hit-wonders. By using a Bloom filter to track seen URLs and cache objects only on repeat access, Akamai reduced disk write operations by almost half, greatly easing the load on cache storage and improving overall cache efficiency. Fewer disk writes mean less wear and higher throughput, and skipping never-reused items frees up cache space for content that will actually be reused, thus boosting the cache hit ratio. In short, the Bloom filter helped the cache focus on the data that matters, reducing resource usage.
-
Reducing Distributed Cache Lookups: In distributed caching systems (with multiple cache servers or shards), Bloom filters can direct lookups and avoid unnecessary network hops. For example, suppose user data is sharded across 10 cache servers. A naive approach to a cache miss might query each server or follow a chain until the item is found or all caches miss. Using Bloom filters, each cache server can publish a Bloom filter of keys it holds. On a lookup, the client or a coordinator can consult these filters first: if none of the cache’s Bloom filters indicate the item, you can skip querying caches entirely and go straight to the database. If one filter returns a “maybe”, you direct the request to that specific server. In the common case where an item isn’t in any cache, you’ve replaced many cache-checking network calls with a few fast Bloom filter checks, thereby reducing latency and load on the cache cluster. This technique ensures that cache servers don’t get peppered with needless lookups for data they never had, and network overhead is minimized.
Bottom line: Bloom filters make caches more efficient by filtering what goes in and what gets queried. They prevent cache pollution from one-off data and reduce work spent on fruitless lookups.
The result is lower I/O load, better utilization of cache space, and faster responses.
Higher cache hit rates and fewer writes/reads ultimately mean the caching layer can handle more load with the same resources.
Real-World Example and Impact
To tie it all together, let’s consider a concrete scenario combining these ideas: Suppose we have an API that fetches user profiles.
We use a Redis cache to store recently fetched profiles and a database for the master data.
Without any filter, if someone requests a lot of non-existent user IDs, the flow would be: cache miss → DB miss (for each ID) → return not found.
The cache gets bypassed and the DB does all the work, possibly getting overwhelmed by the volume of queries.
Now add a Bloom filter of all valid user IDs in the system (periodically updated as new users sign up).
When an ID request comes in, the Bloom filter is checked:
-
If Bloom filter says “not present,” we immediately return a 404/not found without touching cache or DB. The DB avoids a read, and the cache isn’t cluttered with an empty entry (or hammered with repeated misses).
-
If Bloom filter says “might be present,” then we proceed to check the cache and DB normally. In this case, either the data is found (cache hit or DB hit) or not; if not found and it was a false positive, we might choose to cache that “not found” result for a short time or simply let it go.
Over time, this Bloom filter front layer drastically cuts down the number of calls hitting our cache and database for bogus IDs.
The database load drops, since it only sees queries for IDs that at least existed at some point.
The cache load also drops, since we don’t even query it for IDs that we know have never been in the system (and we don’t waste space storing null results except perhaps briefly for false positives).
This design is resilient even under malicious attacks; an attacker trying random IDs will be mostly stopped by the Bloom filter.
As one report notes, leveraging Bloom filters in this way “significantly reduce[s] the load on your cache and database servers when facing cache penetration attacks”.
When to Use (and Not Use) Bloom Filters
Bloom filters shine when you need speed and memory savings and can tolerate a bit of uncertainty.
They are widely used in systems design: from web caching and databases to networking (e.g., routing, intrusion detection) and even blockchain and big-data processing, because they solve the fundamental problem of “Tell me quickly if I should even bother looking for this item.”
By answering that question fast, they save higher layers a lot of work.
However, Bloom filters aren’t always the right choice. If false positives would cause big problems or complexity (for example, security-critical checks), you might need a different approach or a secondary verification step.
Also, if your data set is small or memory is plentiful, a simple hash set or direct cache might be easier with zero ambiguity.
The overhead of managing the Bloom filter (especially if the data changes frequently or you need deletions) is worth it primarily in large-scale scenarios.
Conclusion
A Bloom filter is a powerful probabilistic filter that acts as a traffic cop in front of caches and databases.
It quickly checks “Do we possibly have this item?” and stops a lot of needless work by answering “No” most of the time for missing items.
By doing so, it reduces cache misses hitting the database, lowers disk I/O, and improves response times, all with minimal memory use.
This makes Bloom filters an invaluable tool for software engineers dealing with high-performance caching, databases, or any system where you ask “have we seen this before?”
There are many variations (Counting Bloom filters, Cuckoo filters, etc.) and use-cases, but the core idea remains simple and elegant: sometimes, knowing when to not even try is the key to scaling efficiently.
With Bloom filters, you get a fast, memory-light way to know just that, keeping your caches and databases happy under load.
🤖 Don't fully get this? Learn it with Claude
Stuck on How Can a Bloom Filter Reduce Cache or Database Load? Open Claude, copy a block below, and it'll teach you this exact concept — visually and interactively.
Build the mental picture, not memorization.
I just read a lesson on **How Can a Bloom Filter Reduce Cache or Database Load** (System Design) and want to truly understand it. Explain How Can a Bloom Filter Reduce Cache or Database Load from first principles using ONE vivid real-world analogy and a visual mental model — draw it as ASCII art or a clear step-by-step diagram — with a concrete example using real numbers. Then ask me one question to check I got the mental picture, and wait for my reply. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Socratic — adapts to where you're stuck.
Teach me **How Can a Bloom Filter Reduce Cache or Database Load** interactively. Ask me ONE guiding question at a time, wait for my answer, and adapt to my confusion — build the idea with me step by step instead of explaining it all at once. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Active recall exposes what you missed.
Quiz me on **How Can a Bloom Filter Reduce Cache or Database Load** with 5 questions, easy to tricky, ONE at a time. Tell me if each answer is right; at the end, explain clearly what I got wrong and why. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Intuition + hook + flashcards for long-term memory.
Help me remember **How Can a Bloom Filter Reduce Cache or Database Load** for the long term: give the one-sentence intuition, a memorable hook/mnemonic, a tiny worked example, and 3 active-recall flashcards (Q -> A). If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.