What Is the Difference Between Synchronous and Asynchronous Replication, and When Should I Use Read Replicas
Synchronous vs asynchronous replication differ in when data changes are copied to replicas.
Synchronous replication waits for a replica to confirm each write before finalizing a transaction (ensuring up-to-date copies), whereas asynchronous replication allows the primary system to commit writes immediately and updates replicas afterward, resulting in a delay (replication lag) in data consistency.
Understanding Data Replication and Consistency
Data replication in databases means copying data from a primary (leader) database to one or more secondary (follower) databases to improve reliability, availability, or scalability.
The timing of these copies defines whether replication is synchronous or asynchronous.
This timing impacts data consistency (whether replicas are immediately up-to-date or slightly behind) and system performance (how much latency is added per write). Below we explain each approach and when to use them.
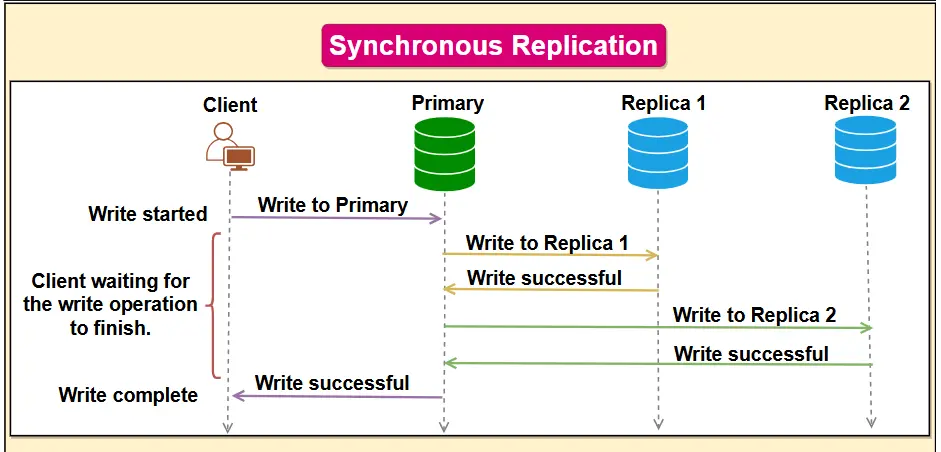
Synchronous Replication (Strong, Real-Time Consistency)
Synchronous replication is a method where each write operation is instantly replicated to a secondary node (replica) and confirmed before the primary considers the transaction.
In other words, the primary database waits for acknowledgment from a replica that the data was written successfully. This ensures the primary and replicas are always in sync with the same data.
-
How it Works: When a transaction occurs, the data is written to the primary and simultaneously sent to the replica(s). The primary will not finalize (commit) the transaction until it receives a confirmation from at least one replica. Only after the replica applies the change and responds does the primary acknowledge success to the user.
-
Consistency & Reliability: Because changes are applied to a replica before confirming the commit, all confirmed transactions exist on both primary and replica. This provides strong consistency and data durability, meaning minimal risk of data loss. If the primary fails immediately after a commit, the replica already has the data. For example, a banking application might use synchronous replication so that every transaction (like a fund transfer) is mirrored on a secondary database in real-time for data integrity and disaster recovery.
-
Performance Impact: The trade-off is latency. Synchronous replication adds network overhead because the primary must wait for the replica’s response on every transaction. This can slow down write performance, especially if replicas are in different locations or networks. It generally requires a high-speed, low-latency network (often within the same data center or Availability Zone) to keep delays minimal. If network latency is high, it directly slows down the application’s writes.
-
Use Cases: Use synchronous replication for critical data that cannot be lost and where strong consistency is paramount. Scenarios include financial systems, inventory or booking systems, and high-availability clusters where an up-to-date standby can take over instantly on failure. It’s commonly used for primary–standby (failover) setups where downtime or data divergence is unacceptable. For instance, many relational databases support a synchronous standby mode to ensure zero data loss failover. Keep in mind the distance between servers. Synchronous replication is typically limited to short distances or same-region deployments to keep latency low.
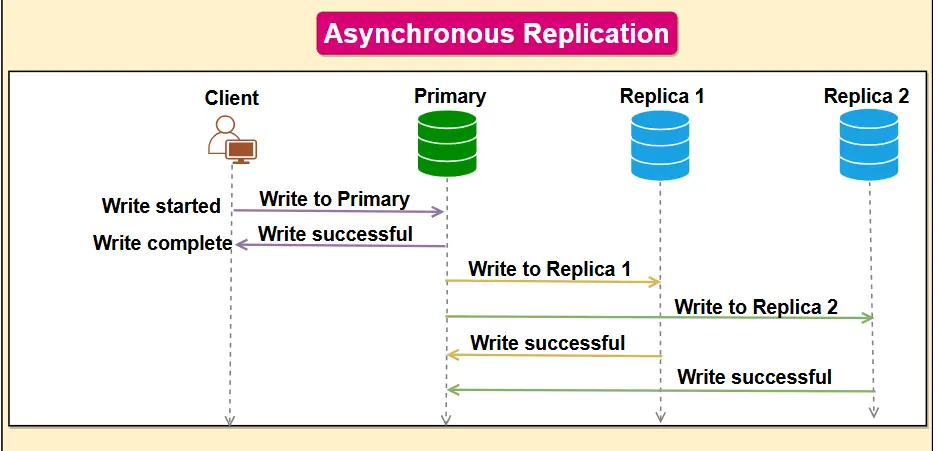
Asynchronous Replication (Eventual Consistency for Performance)
Asynchronous replication is a method where the primary database does not wait for the replica to acknowledge writes.
The primary commits changes immediately and sends the update to replicas after the fact (often nearly real-time or on a schedule).
This means replicas apply changes with some delay, resulting in eventual consistency (they’ll catch up, but not instantly).
-
How it Works: When a transaction is committed on the primary, it is queued for replication but the primary immediately considers it successful without waiting for any replica response. The updates are delivered to replicas asynchronously, e.g. via a log shipping or messaging process and replicas apply them as they arrive. There’s no guarantee the replica has the latest transaction at any given moment right after a write. For example, an e-commerce site might use asynchronous replication to copy product inventory data to a reporting database; the replica might be a few seconds behind, which is acceptable for analytics.
-
Performance Benefits: Asynchronous replication minimizes write latency on the primary, because the application isn’t waiting for another server over the network. This allows faster transaction throughput on the primary database. It’s also more tolerant of network latency and outages, even a slower or distant network link is fine because writes don’t block on it. In fact, asynchronous methods can work over long distances or Internet links (WAN), making it suitable for cross-region replication and backups.
-
Consistency Trade-off: The downside is replication lag. Replicas might be seconds or even minutes behind the primary, especially under heavy load or network delays. This means reads from a replica might be stale (not reflect the very latest writes). If the primary fails suddenly, any transactions not yet replicated to the secondary could be lost. The risk of data loss in a failover event is the main drawback. The system’s Recovery Point Objective (RPO) isn’t zero (some recent data might not be replicated). Many systems accept this risk for the sake of performance, especially if the lag is typically small.
-
Use Cases: Use asynchronous replication when performance and scalability are top priority and slight data staleness is acceptable. Common scenarios include geographically distributed databases (where network latency makes synchronous impractical), reporting/analytics databases, and any situation where the primary handles heavy write load and you want to offload reads or backups to secondaries. For instance, content websites and social networks often replicate data asynchronously to multiple read copies worldwide. Each user’s local reads may be slightly behind, but the system scales better. Asynchronous replication is also typical for disaster recovery backups where you can tolerate minor data loss in a worst-case failure.
Side-by-Side Differences
In summary, the primary difference between synchronous and asynchronous replication is when confirmation happens during a transaction commit:
-
Timing of Data Copy: Synchronous writes data to primary and replica at the same time (in one atomic operation), whereas asynchronous writes to the primary first and replicates to others afterward.
-
Confirmation/Acknowledgment: Synchronous requires an acknowledgment from a replica before considering the write successful. Asynchronous does not wait for acknowledgment, so the primary confirms instantly.
-
Consistency: Synchronous keeps replicas fully up-to-date with the primary (strong consistency). Asynchronous leads to eventual consistency, where replicas might lag behind.
-
Performance Impact: Synchronous adds latency to writes (each write incurs network round-trip to a replica), potentially impacting throughput. Asynchronous has minimal impact on write latency. It’s faster for the primary since it doesn’t wait.
-
Failure Recovery: With synchronous replication, failover to a replica incurs zero or near-zero data loss, because the latest data was on the replica. With asynchronous, failover might lose the most recent writes that hadn’t replicated yet (some data loss).
-
Network Requirements: Synchronous typically needs a reliable, high-bandwidth, low-latency network (often LAN or same cloud zone) between nodes. Asynchronous can work over slower or long-distance links and tolerate brief outages since it can catch up later.
-
Use Case Focus: Synchronous is chosen for high availability and data integrity (e.g. mirroring critical transactional data). Asynchronous is chosen for scalability and flexibility, like distributing data to many replicas or across regions where perfect immediacy isn’t critical.
In practice, some systems even use a hybrid approach (semi-synchronous replication) to balance these trade-offs. For example, requiring one replica to acknowledge (to secure one safe copy) and letting other replicas update asynchronously.
The choice depends on the application’s consistency requirements, performance needs, and network infrastructure.
What Are Read Replicas?
Read replicas are a specific use of asynchronous replication: they are read-only copies of a database that receive updates from the primary asynchronously and serve read queries to distribute load.
The primary database handles all writes, while read replicas can answer SELECT queries, reports, or other read-heavy operations. This pattern is common in scaling databases for high read throughput.
When you create a read replica from a source database, the source becomes the primary (writer) and continues to handle all data modifications.
Updates from the primary are then copied to the replica asynchronously, meaning the replica might apply them moments later.
Clients or application servers can be directed to send read-only requests to the replicas while writes go to the primary.
This way, expensive queries (e.g. analytical queries or frequent reads of popular data) are offloaded from the primary, improving overall performance and allowing the system to scale out beyond what a single server could handle.
-
Benefits of Read Replicas:
-
Improved Scalability: By distributing read traffic to multiple replicas, you can handle much higher read throughput. This is ideal for read-heavy workloads. For example, large web applications or content systems where many users are reading data (product catalogs, user profiles, posts) but writes are relatively infrequent. The primary can focus on writes, and replicas can collectively serve far more read queries than one server could.
-
Reduced Load on Primary: The primary database experiences less read stress, which can reduce contention and potentially improve write performance. It can also help with maintaining snappy performance as user count grows, since reads no longer bottleneck the primary.
-
High Availability for Reads: If the primary becomes temporarily unavailable (e.g. for maintenance or backup), the read replicas can still serve read requests in the interim. However, note that the data on replicas could be slightly outdated if the primary is down (since replication is asynchronous). Read replicas are not a full high-availability replacement for the primary, but they provide some continuity for read operations.
-
Geographical Distribution: You can place read replicas in different data centers or regions closer to users, so read queries have lower latency. Each replica asynchronously pulls updates from the primary and serves local users with faster response times.
-
Reporting and Analytics: Heavy reporting or analytics queries can be directed to a replica (or a dedicated reporting replica) instead of the production primary. This prevents long-running queries from impacting the primary’s performance. For instance, a sales dashboard or data warehouse can use a replica of the production database to run complex joins or generate reports without slowing down live transactions.
-
Disaster Recovery (DR) Option: In an emergency, a read replica can often be promoted to become a standalone primary if the original primary fails. This makes replicas a part of a DR strategy (though any unreplicated writes just before the failure could be lost). Promotion is usually a manual or separate process; read replicas don’t automatically fail over by themselves because they are intended mainly for scaling reads.
-
-
Considerations: Because read replicas rely on asynchronous replication, they exhibit replication lag. The delay is typically small (seconds) but can grow if the primary is under heavy load or network is slow. Thus, read-your-writes consistency is not guaranteed on a replica. If a user just wrote data and then reads from a replica immediately, their data might not appear yet. For this reason, certain applications route critical read-after-write queries to the primary to ensure up-to-date data, and use replicas for less time-sensitive reads. Also, each replica is an additional database instance to maintain and monitor, and while they scale reads, they do not help with write scaling (writes still funnel through the single primary).
When to Use Read Replicas
Use them when your application is read-intensive and the database is becoming a bottleneck for reads.
They are well-suited for scaling out read-heavy systems, such as news sites, social media feeds, e-commerce product displays, etc., especially under cloud architectures.
For example, Amazon RDS (a managed database service) allows creating multiple read replicas of a primary database to handle read traffic; these replicas are updated asynchronously with the primary’s latest changes.
Amazon’s documentation notes scenarios like scaling beyond a single DB’s capacity for reads, serving reads during primary downtime, offloading reporting queries, and improving disaster recovery readiness as key use cases.
If your database’s CPU is high due to read queries or users experience slow read performance, adding read replicas can help distribute the load.
On the other hand, if you require strong consistency on reads or automatic failover with zero data loss, a different approach like synchronous replication (e.g., a standby replica in a primary-backup setup) would be used.
In fact, many systems use both: one or two synchronous standby nodes for high availability, and additional asynchronous read replicas for scaling.
For instance, in AWS RDS you might configure a Multi-AZ deployment where a standby replica is kept in sync (synchronous) for failover, and also have separate read replicas (asynchronous) in other zones or regions to serve read traffic.
The standby is not accessible to applications (only for failover), while the read replicas are queryable but slightly behind. This design gives the best of both worlds: immediate failover capability and horizontal read scaling.
Choosing the Right Approach
Synchronous vs Asynchronous
The choice between synchronous and asynchronous replication comes down to a consistency vs performance trade-off and your application’s needs.
If losing even a tiny bit of data on a crash is unacceptable and you can tolerate some write latency, synchronous replication is the safer choice (ensuring strong consistency and easy failover).
If your system needs to handle very high write volume or long distances and can accept eventual consistency, asynchronous replication will give better throughput and flexibility.
Often, critical transactional systems use synchronous replication for durability, whereas high-scale web services and content delivery use asynchronous replication for speed and geographic distribution.
When to Use Read Replicas
You should use read replicas when you need to scale read operations or isolate certain queries from the primary.
They are especially useful in cloud and distributed architectures where traffic can spike and you want to ensure read-heavy parts of your application remain responsive.
Read replicas are not typically used for write scaling or immediate consistency needs. They shine when you have many more reads than writes (a common scenario in social apps, SaaS products, etc.) and you’re aiming for better read performance and horizontal scaling.
Keep in mind that a load balancer or application logic is needed to direct read queries to the replicas and write queries to the primary.
Also, plan for monitoring the replication lag and having a strategy to promote or replace replicas if needed.
In summary, synchronous replication vs asynchronous replication is about immediate consistency versus performance and flexibility, and read replicas are a practical application of asynchronous replication to improve read throughput.
By understanding these concepts, you can design a database system that balances data integrity with scalability. For example, using synchronous methods for critical data protection and asynchronous read replicas to serve a growing user base efficiently.
🤖 Don't fully get this? Learn it with Claude
Stuck on What Is the Difference Between Synchronous and Asynchronous Replication, and When Should I Use Read Replicas? Open Claude, copy a block below, and it'll teach you this exact concept — visually and interactively.
Build the mental picture, not memorization.
I just read a lesson on **What Is the Difference Between Synchronous and Asynchronous Replication, and When Should I Use Read Replicas** (System Design) and want to truly understand it. Explain What Is the Difference Between Synchronous and Asynchronous Replication, and When Should I Use Read Replicas from first principles using ONE vivid real-world analogy and a visual mental model — draw it as ASCII art or a clear step-by-step diagram — with a concrete example using real numbers. Then ask me one question to check I got the mental picture, and wait for my reply. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Socratic — adapts to where you're stuck.
Teach me **What Is the Difference Between Synchronous and Asynchronous Replication, and When Should I Use Read Replicas** interactively. Ask me ONE guiding question at a time, wait for my answer, and adapt to my confusion — build the idea with me step by step instead of explaining it all at once. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Active recall exposes what you missed.
Quiz me on **What Is the Difference Between Synchronous and Asynchronous Replication, and When Should I Use Read Replicas** with 5 questions, easy to tricky, ONE at a time. Tell me if each answer is right; at the end, explain clearly what I got wrong and why. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Intuition + hook + flashcards for long-term memory.
Help me remember **What Is the Difference Between Synchronous and Asynchronous Replication, and When Should I Use Read Replicas** for the long term: give the one-sentence intuition, a memorable hook/mnemonic, a tiny worked example, and 3 active-recall flashcards (Q -> A). If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.