What Is MVCC Multi‑Version Concurrency Control, and How Does It Enable Concurrent Reads and Writes
Multi-Version Concurrency Control (MVCC) is a database concurrency technique that maintains multiple versions of each data record to allow simultaneous reads and writes without conflicts, giving each transaction a consistent snapshot of the data.
In simple terms, reads do not block writes, and writes do not block reads under MVCC, because each user or transaction works on its own snapshot of data.
This approach is widely used in modern databases to improve performance and avoid locking conflicts, enabling fast, concurrent transactions even under heavy multi-user workloads.
Why Concurrency Control Matters (The Problem MVCC Solves)
When many users access a database at the same time, some form of concurrency control is needed to keep data consistent.
Without it, a reader could see half-written (inconsistent) data if another user is in the middle of an update.
For example, imagine a bank transfer: if one transaction debits an account and another credits a different account, a concurrent reader might catch the system between those steps and see money “disappear” or partial results.
The database isolation property (the “I” in ACID) is meant to prevent such anomalies by controlling concurrent access.
A traditional solution is to use locks, for instance, making readers wait until a writer finishes (a read-write lock).
While locking does ensure consistency, it introduces contention: long-running reads block writes, and writes block reads, leading to waiting transactions and reduced throughput.
In a high-traffic application, this can become a bottleneck, causing slow performance and even deadlocks (two transactions waiting on each other indefinitely).
MVCC was created to solve this concurrency bottleneck.
Instead of forcing every transaction to line up and take turns, the database keeps multiple copies (versions) of data. This way, each user sees a snapshot of the database at a particular point in time, and writers don’t overwrite existing data until they finish their changes.
Any updates occur on a new version, so other transactions can continue reading the old version without waiting.
Once a writer commits (completes) the changes, the new version becomes the one that future readers will see, while older versions may eventually be cleaned up.
By doing this, MVCC provides isolation and keeps data consistent without relying on coarse locking.
Check out Top Concurrency and Multithreading Considerations for System Design Interviews.
How MVCC Works: Enabling Concurrent Reads and Writes
MVCC works on the principle of versioned data and snapshot isolation.
Instead of a single “current value” for each database item, there can be several versions of that item, each tagged with a timestamp or transaction ID indicating when it was created.
Here’s a simplified look at how MVCC enables concurrent reads/writes:
-
Versioned Records: Each data record in the database carries a version identifier (e.g. a version number or timestamp). New transactions see the latest committed version of a record as of their start time.
-
Readers Use Snapshots: A read operation always accesses the record version that was the latest and committed when the transaction began. This means the reader sees a consistent snapshot of the database as of its start—no matter what writes occur afterward.
-
Writers Create New Versions: When a transaction wants to write (update some data), it doesn’t modify the record in place. Instead, it works on a copy of the record (an independent new version). The original version is left untouched so that active readers can still access it.
-
Non-Blocking Updates: While the writer is updating the copy, other users can continue reading the older version concurrently. There’s no interference: the writer is isolated with its new version, and readers are unaffected by the in-progress change.
-
Commit and Version Switch: When the write transaction successfully commits, the record’s version is incremented/updated to mark the new data as the latest version. Future transactions or reads will now see this new version (with the updated data).
-
Continuous Version Cycle: If another update comes along later, the database will again create a new version of the record, leaving the now-previous version as a historical one. In this way, the cycle continues with each update creating a new version while old versions persist for any transactions that still need them.
Under this mechanism, readers and writers don’t block each other.
A reader simply picks the appropriate version (the one valid for its start time) for each data item, and a writer creates a new version for its changes.
In effect, reads never have to wait for writes, and writes don’t have to wait for reads.
Multiple transactions can query or update the same data simultaneously with minimal contention because each one is working with its own versioned view.
The only time transactions need to synchronize is if two writers try to update the exact same item. In that case, the system will allow one to commit and typically abort or retry the other to prevent conflicting changes (this happens at commit time in MVCC).
However, reads never conflict with writes under MVCC’s design, which is the key to its high concurrency.
Example Scenario: MVCC in Action
To make MVCC more concrete, consider a simple scenario with two users (transactions) interacting with a product price in an e-commerce database:
-
Initially, the product’s price is $100 (version 1 of the record).
-
Transaction A (Alice) starts and reads the price. Alice’s transaction sees price = $100 (it’s reading version 1).
-
Transaction B (Bob) starts a moment later and wants to update the price to $120. Bob’s transaction will create a new version of the product record (let’s call this version 2) with price = $120. Importantly, Bob’s change is happening on the new version in isolation. The original version ($100) is still available.
-
While Bob is editing (before he commits), Alice’s Transaction A continues to see the price as $100 (because her reads come from the snapshot as of when she started, which was version 1). Alice is unaffected by Bob’s in-progress update.
-
Bob finishes his update and commits the transaction. At that moment, version 2 (price $120) is marked as committed/current. New transactions that start afterward will see the price as $120.
-
Alice’s long-running Transaction A, however, will continue to see the old price $100 for its duration, since it began before Bob’s commit. If Alice tries to make a change that conflicts with Bob’s, the system will detect the conflict at commit time. But if she’s just reading, she never saw an inconsistent or half-updated state. It’s as if Bob’s update “happened later” from her viewpoint.
In this example, Bob’s write never blocked Alice’s read, and Alice didn’t have to wait for Bob to finish.
Each operated on their own version of the data.
Alice saw a consistent snapshot ($100 the whole time), and Bob was able to apply an update concurrently.
Once Bob’s update was done, the new price became visible to others.
This demonstrates how MVCC enables concurrent reads and writes: by versioning data, readers get a stable view while writers proceed with updates on newer versions.
Benefits of MVCC for Database Concurrency
MVCC is popular because it greatly improves the concurrency and user experience in database systems.
Key benefits include:
-
No Read Locks Needed (Non-blocking Reads): Under MVCC, reading transactions do not need to lock data, so reads never wait on writes. This leads to faster read performance under heavy load, since queries aren’t stuck behind updates. It also means long-running analytical queries can run without freezing out other updates.
-
High Concurrency & Throughput: Because reads and writes can happen in parallel, overall throughput increases. Many users can use the system at once with minimal interference, which is ideal for read-heavy or mixed read-write workloads (e.g. web applications, real-time dashboards). The database can handle more transactions per second as it avoids many locking delays.
-
Reduced Contention and Deadlocks: MVCC diminishes the need for strict locks, thereby cutting down on contention issues where transactions fight over the same data. Fewer locks also mean fewer deadlocks. Scenarios where two transactions each hold a lock the other needs (since reads don’t lock at all in MVCC, the lock wait graph is much simpler). This makes the system more robust under concurrent access.
-
Consistent Snapshots (Isolation): Every transaction sees a point-in-time consistent snapshot of the data, which avoids problems like dirty reads (seeing uncommitted data) or half-done updates. MVCC provides strong isolation guarantees (often snapshot isolation level), meaning a transaction’s view doesn’t change mid-stream. This improves data integrity without sacrificing concurrency.
-
Better Read Performance Under Load: For workloads that involve heavy reading (reporting, analytics) alongside writes, MVCC shines. Readers are not blocked by writers, so read performance remains predictable and stable even as updates occur in the background. This is a big advantage for systems that must serve many simultaneous queries.
Overall, MVCC’s optimistic concurrency approach (let transactions proceed without waiting unless there’s a true conflict) provides a smoother experience in multi-user environments than traditional locking.
It lets databases scale to more users and operations with less performance degradation.
Challenges and Trade-offs of MVCC
While MVCC offers significant advantages, it also comes with a few trade-offs and overheads to be aware of:
-
Storage Overhead (Multiple Versions): Maintaining several versions of data means the database will use more storage. Every update creates a new copy of a row (or equivalent in an undo log), so a database can grow in size (bloat) due to old versions hanging around. In write-heavy systems or with long transactions, these old versions can accumulate and consume disk space.
-
Cleanup/Garbage Collection: The system must eventually remove obsolete versions that are no longer needed. MVCC databases require background processes to clean up old records. For example, PostgreSQL uses a VACUUM routine to purge outdated row versions. Managing this cleanup adds complexity and can consume resources. If cleanup doesn’t keep up, performance can suffer from all the extra versions.
-
Implementation Complexity: MVCC is more complex to implement inside the database engine compared to simple locking. The database must track transaction timestamps, manage version visibility logic, and handle the above-mentioned garbage collection. All of this is hidden from the end user (the DBMS does it behind the scenes), but it’s a complexity cost for the database system. However, this complexity is usually justified by the performance gain.
-
Write Conflict Handling: Although reads don’t block writes, simultaneous writes to the same data still need to be managed. MVCC typically uses an optimistic approach where conflicts are detected at commit time. This can result in a transaction failing to commit if another committed first on the same record (requiring a retry). Thus, MVCC doesn’t eliminate write-write conflicts; it just handles them differently (often by aborting one transaction), which developers need to be aware of in high-contention scenarios.
Despite these issues, most databases mitigate them with tuning and design (e.g., frequent vacuuming, using indexes to reduce scans of old versions, etc.).
In practice, the benefits outweigh the drawbacks for the majority of applications that need high concurrency.
MVCC vs. Traditional Locking Concurrency Control
It’s helpful to compare MVCC with the classic locking approach to understand how it enables concurrency.
Traditional locking (often using two-phase locking, 2PL) ensures isolation by making transactions wait for each other.
For example, if one transaction is writing to a row, it places an exclusive lock and any other transaction trying to read or write that row must wait until the lock is released.
This is like forcing every user to queue up and use the same ledger one at a time, which guarantees order but can be slow.
MVCC takes a different approach: it provides isolation by versioning rather than exclusion. Each transaction gets its own versioned view of the data, so they don’t have to queue.
In our analogy, MVCC is like handing every user their own copy of the ledger (snapshot) with a timestamp. Everyone can read/write their copy concurrently, and changes are merged by the system when transactions commit.
Updates don't block reads, and reads don't block updates in MVCC because every transaction operates on a snapshot of data.
Lock-based systems, by contrast, achieve isolation by preventing concurrent access (transactions must wait for locks), which leads to contention and idle time.
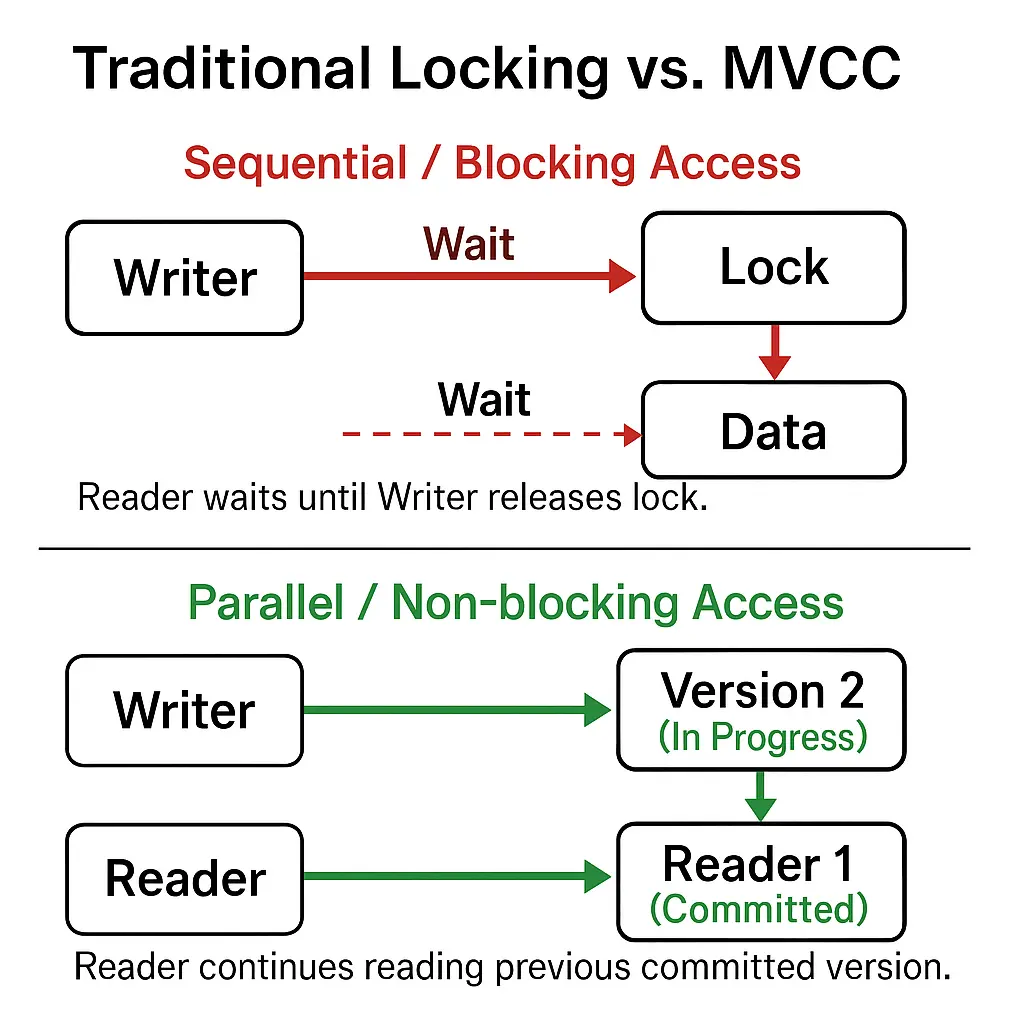
In a locking system, a writer must hold a lock on the data, and other transactions (e.g. readers) wait until that lock is released.
With MVCC, the writer instead creates a new version of the data while readers continue to access the older version, so both operations proceed in parallel.
This eliminates the need for read/write locks, avoiding the contention and deadlock issues that come with lock-based schemes.
The net result is higher concurrency: many transactions can work simultaneously on the same dataset without stepping on each other.
In summary, locking enforces isolation by serializing access (one-at-a-time access to data), whereas MVCC enforces isolation by isolating data versions for each transaction.
The latter is much more efficient for modern workloads where reads are frequent and real-time responsiveness is important.
That said, locking might still be preferable in some scenarios requiring strict serial ordering or simpler systems with low concurrency, but MVCC has become the standard for general-purpose databases because it balances consistency and performance so well.
Use Cases and Platforms Using MVCC
Because of its advantages for concurrency, MVCC is employed in many database systems today.
Some notable examples:
-
Relational Databases: Almost all major RDBMSs use MVCC or a variant of it. PostgreSQL is a well-known MVCC database – it keeps a version history for each row and uses a VACUUM process to clean up old versions. MySQL’s InnoDB engine also uses MVCC, maintaining a single copy of each row plus an undo log of changes to reconstruct older versions when needed. Oracle has used an MVCC-like mechanism for decades (with rollback segments for old data). These systems rely on MVCC to achieve high throughput for mixed read/write workloads.
-
Microsoft SQL Server: SQL Server historically used strict locking by default, but newer versions support an optional MVCC mode known as Snapshot Isolation (enabled via read-committed snapshot settings). This shows even platforms originally built on locking have adopted MVCC techniques to offer better concurrency to users.
-
NoSQL / NewSQL Databases: MVCC isn’t limited to traditional SQL databases. Some NoSQL and NewSQL systems also utilize multi-versioning for performance. For example, KeyDB (an enhanced Redis variant) introduced MVCC to allow concurrent operations without locks in an in-memory database. Many distributed databases and ledger systems use MVCC or similar timestamp-ordering methods to handle concurrent updates across nodes. The concept is broadly useful wherever you need high concurrency and consistent reads.
-
Transactional Memory Systems: In programming language design, the concept of MVCC appears in transactional memory and other concurrency control in-memory (though this is more niche). The general idea of keeping multiple versions in memory to let threads work in parallel on shared data is analogous to MVCC in databases.
In general, MVCC is favored in any scenario where read performance and concurrency are top priorities.
Systems with lots of simultaneous reads and writes (financial systems, large web applications, analytics platforms, etc.) benefit greatly from MVCC’s ability to isolate transactions without making them wait on each other.
🤖 Don't fully get this? Learn it with Claude
Stuck on What Is MVCC Multi‑Version Concurrency Control, and How Does It Enable Concurrent Reads and Writes? Open Claude, copy a block below, and it'll teach you this exact concept — visually and interactively.
Build the mental picture, not memorization.
I just read a lesson on **What Is MVCC Multi‑Version Concurrency Control, and How Does It Enable Concurrent Reads and Writes** (System Design) and want to truly understand it. Explain What Is MVCC Multi‑Version Concurrency Control, and How Does It Enable Concurrent Reads and Writes from first principles using ONE vivid real-world analogy and a visual mental model — draw it as ASCII art or a clear step-by-step diagram — with a concrete example using real numbers. Then ask me one question to check I got the mental picture, and wait for my reply. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Socratic — adapts to where you're stuck.
Teach me **What Is MVCC Multi‑Version Concurrency Control, and How Does It Enable Concurrent Reads and Writes** interactively. Ask me ONE guiding question at a time, wait for my answer, and adapt to my confusion — build the idea with me step by step instead of explaining it all at once. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Active recall exposes what you missed.
Quiz me on **What Is MVCC Multi‑Version Concurrency Control, and How Does It Enable Concurrent Reads and Writes** with 5 questions, easy to tricky, ONE at a time. Tell me if each answer is right; at the end, explain clearly what I got wrong and why. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Intuition + hook + flashcards for long-term memory.
Help me remember **What Is MVCC Multi‑Version Concurrency Control, and How Does It Enable Concurrent Reads and Writes** for the long term: give the one-sentence intuition, a memorable hook/mnemonic, a tiny worked example, and 3 active-recall flashcards (Q -> A). If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.