Microservices Patterns
Step 27 in the System Design path · 82 concepts · 9 problems
📘 Learn Microservices Patterns from zero
"Microservices Patterns" is a System Design interview staple: you take a monolith, split it into independently deployable services, and then glue them back together over the network. Interviewers rarely want a memorized list of patterns - they want to see you reason about WHY each pattern exists, what specific failure it prevents, and what new cost it introduces (because every distributed pattern trades local simplicity for some network-induced pain). This is a building-block topic, so we drive it pattern-by-pattern from the mechanism, NOT through the end-to-end product-design framework: each step poses a question, then reveals a concrete cause->effect chain with the trade-off named. Try to answer out loud before you reveal the reasoning - that is exactly how you should think on the whiteboard.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○Introduction
- ○The Problem Legacy Systems
- ○The Architecture of the Strangler Pattern
- ○Strangler Pattern A Detailed Example
- ○Key Insights and Implications
- ○Introduction to the API Gateway Pattern
- ○Advantages of API Gateway Pattern
- ○API Gateway Pattern An Example
- ○Performance Implications
- ○System Design Example
- ○Introduction to BFF
- ○The Problem Traditional Backend Models
- ○The Architecture of the BFF Pattern
- ○BFF Pattern An Example
- ○Performance Implications
- ○System Design Examples
- ○What is Service Discovery Pattern
- ○The Problem Service Coordination in Distributed Systems
- ○The Architecture of the Service Discovery Pattern
- ○The Inner Workings of the Service Discovery Pattern
- ○Service Discovery Pattern An Example
- ○Performance Implications and Special Considerations
- ○System Design Examples
- ○Security Considerations
- ○Introduction
- ○The Problem The Struggles of Distributed Systems and Service Failures
- ○The Circuit Breaker Pattern An Effective Shield Against Cascading Failures
- ○Circuit Breaker Pattern An Example
- ○Performance Implications and Special Considerations
- ○System Design Examples
- ○Summary
- ○Introduction
- ○The Problem Failure Propagation in Distributed Systems
- ○The Architecture
- ○The Inner Workings
- ○Bulkhead Pattern An Example
- ○Performance Implications and Special Considerations
- ○System Design Examples
- ○Conclusion
- ○Introduction
- ○The Architecture of the Retry Pattern
- ○Retry Pattern An Example
- ○Performance Implications
- ○Use Cases and System Design Examples
- ○Conclusion
- ○Introduction to the Sidecar Pattern
- ○The Problem Monolithic Application Management
- ○The Architecture of the Sidecar Pattern
- ○Sidecar Pattern Bringing Theory to Practice with an Example
- ○Performance Implications
- ○System Design Examples Bringing the Sidecar Pattern to Life
- ○Introduction to Saga Pattern
- ○The Problem Traditional Transaction Models
- ○The Architecture of the Saga Pattern
- ○The Inner Workings of the Saga Pattern
- ○Saga Pattern A Example
- ○Performance Implications
- ○System Design Examples
- ○Conclusion
- ○Introduction
- ○The Problem Managing Complex Interactions in Distributed Systems
- ○The Architecture of the Event-Driven Architecture Pattern
- ○The Inner Workings of the Event-Driven Architecture Pattern
- ○Event-Driven Architecture Pattern An Example
- ○Performance Implications and Special Considerations
- ○Use Cases and System Design Examples
- ○Conclusion
- ○Introduction
- ○The Problem Traditional CRUD Operations
- ○The Architecture of the CQRS Pattern
- ○The Inner Workings of the CQRS Pattern
- ○CQRS Pattern An Example
- ○Issues, Special Considerations, and Performance Implications
- ○System Design Examples
- ○Introduction
- ○The Problem Configuration Management in a Microservices Architecture
- ○Unveiling the Architecture How Does Configuration Externalization Work
- ○Delving into Code An Example
- ○Considerations and Implications
- ○Use Cases and Real-world Examples
- ○Conclusion
- ○Embrace the Future of Software Architecture
- ○The Strangler Pattern A Solution
- ○Service Discovery Pattern A Solution
- ○The Bulkhead Pattern A Solution
- ○The Retry Pattern A Solution to Unreliable External Resources
- ○A Solution to the Monolithic Mayhem
- ○The Saga Pattern A Solution
- ○Event-Driven Architecture A Promising Solution
- ○CQRS Pattern A Solution
- ○The Solution Configuration Externalization Pattern
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 A legacy monolith handles 500 req/s today and still works. The interviewer says 'decompose it into microservices.' What concrete pain are we solving, and what should you clarify before drawing a single box?
Reveal the reasoning
The justification is a cause→effect chain, not 'microservices are modern':
- One codebase → one deploy unit: a 1-line fix to the checkout module forces a full redeploy of the whole 2M-line app, so deploy frequency drops to maybe once a week, and an unhandled exception in
reportingshares the same process/heap ascheckoutand can take it down with it. - Shared runtime → no isolated scaling: if
searchneeds 10x CPU, you must scale the entire monolith 10x, wasting compute on the other 9 modules that didn't need it. - Effect of splitting: teams deploy services independently (daily, not weekly) and scale only the hot service.
Clarify first: traffic (req/s, read:write ratio), which modules change most often or have the most divergent scaling needs, team count, and migration risk tolerance — these decide whether splitting even pays off. Cost introduced: you trade in-process function calls for network calls — added latency, partial failures, and the loss of ACID transactions across what used to be one DB (which later forces patterns like Saga). Trade-off in one line: independent deploy + scale, bought with distributed-systems complexity. Don't migrate a healthy small system run by one or two teams; the overhead isn't worth it.
🤔 You decide to extract the Orders module first. At 500 req/s with 20% writes (100 writes/s) and an average order row of 1 KB, roughly how much new write volume and storage does carving it out create — and why does that number argue for the Strangler pattern over a big-bang rewrite?
Reveal the reasoning
- Write storage growth: 100 writes/s × 1 KB × 86,400 s/day ≈ 8.6 GB/day, ~3 TB/year for orders alone (before indexes/replicas) — large enough that you can't just copy the table in one short maintenance window without a sync strategy.
- New network hops: every call that used to be an in-process method now crosses the wire. If each request touched
Orders3 times, that's 500 × 3 = ~1,500 extra cross-service calls/s, each adding ~1–2 ms of network + serialization → effect: p99 latency rises unless you batch or co-locate. - Why this forces Strangler: a big-bang rewrite means dual-maintaining ~3 TB of live, moving data and flipping everything at once → effect: one bad assumption takes down all 500 req/s with no graceful fallback. Strangler routes a small % of traffic to the new service incrementally, so the blast radius at any moment is bounded to that %.
Cost introduced: during migration you run BOTH the monolith path and the new service path, roughly doubling infra for that slice and requiring continuous data sync (CDC or dual-write) between old and new stores until cutover.
🤔 The Strangler Fig pattern wraps the monolith and slowly replaces it. Where do you put the routing decision so you can move from 0% → 100% on the new Orders service without a code freeze, and how do you roll back in seconds if it misbehaves?
Reveal the reasoning
Put a routing facade (proxy/gateway) in front of the monolith. Chain:
- All traffic hits the facade → the facade checks a routing rule (e.g.
/orders/* → new service for 5% of users) → unmatched paths fall through to the monolith unchanged. - Increase the percentage gradually: 5% → 25% → 100%. Effect: if the new service's error rate jumps, you flip the rule back to 0% → traffic instantly returns to the proven monolith, with a config change and no redeploy.
- When 100% is stable and verified, delete the old module from the monolith — the 'fig' has strangled the 'tree'.
Concrete safety net: emit metrics per route so a 5% canary showing a 2% error rate (vs the monolith's 0.1%) trips an alarm before it reaches more users. Data caveat: routing reads is easy; routing writes means both paths may write the same order, so you need a single source of truth for writes (or sync) during the overlap.
Cost introduced: the facade is now a critical hop on the path — it adds latency (~1 ms) and must itself be highly available (it's a new SPOF if you run one), and you carry dual data-write/sync logic until the cutover completes.
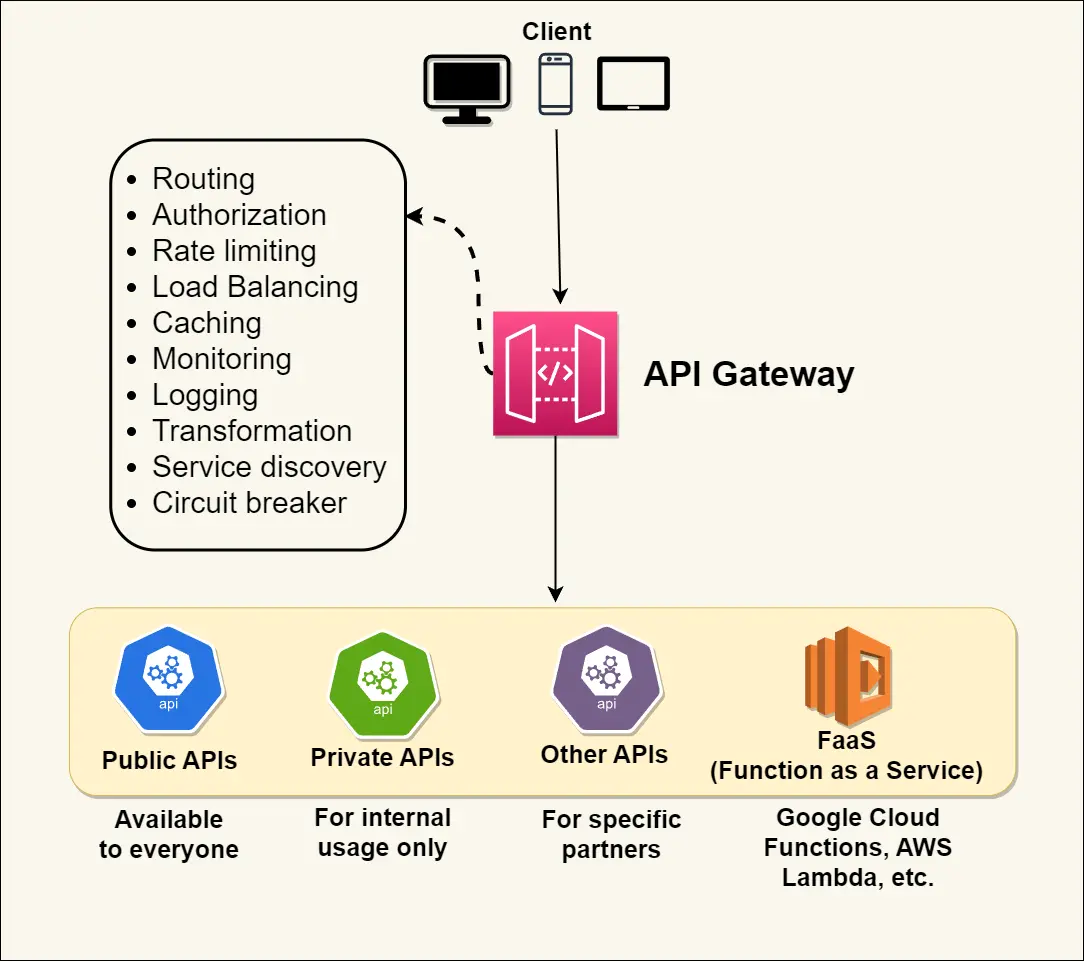
🤔 After extracting 8 services, a single web page now needs data from 5 of them. If the browser calls all 5 directly, what breaks — and what does an API Gateway fix that a plain L4 load balancer cannot?
Reveal the reasoning
Direct client→5-services has compounding problems:
- Chattiness: 5 sequential round trips over mobile (each ~100 ms RTT) → ~500 ms just in network latency; effect: visibly slow page load.
- Coupling: the client hardcodes 5 hostnames; rename/split a service and you must ship a new app version to every user.
- Duplicated cross-cutting logic: auth, rate-limiting, TLS termination, and logging would each be reimplemented 5 times.
The Gateway gives one entry point that authenticates once, rate-limits once, terminates TLS once, and routes (or fans out) to services internally over fast east-west links. A plain L4 load balancer can't do this — it routes on IP/port and doesn't understand auth tokens, request paths, or response aggregation, which all require reading L7 (HTTP) content.
Cost introduced: the Gateway is a single choke point and potential bottleneck/SPOF — it needs its own horizontal scaling and HA, and it can decay into a 'distributed monolith' if every team dumps business logic into it. Keep it thin: routing, auth, rate-limit — not domain logic. Trade-off: one well-protected, well-scaled front door vs. clients coupled to your internal topology.
🤔 The product page needs profile + orders + recommendations. Should the Gateway make 3 sequential internal calls, or something smarter? Put numbers on it.
Reveal the reasoning
- Sequential at the gateway: 40 ms + 30 ms + 80 ms = 150 ms server-side before responding.
- Parallel fan-out (the right move when calls are independent): fire all 3 concurrently → total ≈ max(40, 30, 80) = 80 ms. Effect: ~47% faster ((150−80)/150) with zero new infra. (Only works because none of the three calls depends on another's output.)
- Plus one client round trip instead of three: on a 100 ms-RTT mobile link, collapsing 3 trips into 1 saves the client ~200 ms of round-trip latency it never pays.
Resilience chain: wrap each internal call in a timeout (say 100 ms) and a circuit breaker. If recommendations is down, return profile + orders and an empty recs block → effect: degraded page, not a failed page.
Cost introduced: aggregation logic now lives in the gateway, so a slow downstream can pin gateway threads/connections (head-of-line blocking) — you need bulkheads (per-dependency thread/connection pools) so one slow service can't starve the others, and the gateway needs more memory to hold in-flight fan-out responses. Trade-off: lower latency and fewer client trips, paid for with stateful, failure-prone orchestration in the gateway.
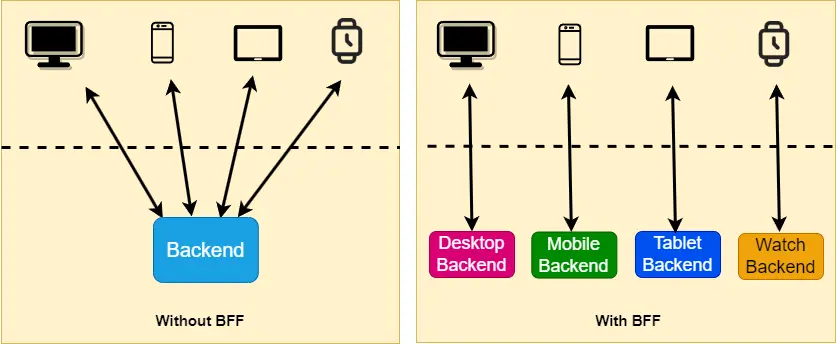
🤔 The mobile app wants tiny, battery-friendly payloads; the desktop web wants rich nested data. A single generic gateway response tries to please both. What pattern resolves this, and what's the trade-off of the obvious 'just send everything' approach?
Reveal the reasoning
'Send everything' means the mobile client downloads a 50 KB payload and renders 8 KB of it → wasted bandwidth and battery (parsing + transfer over a metered radio), plus chronic over-fetching that the team papers over with ad-hoc query params until the API is a mess.
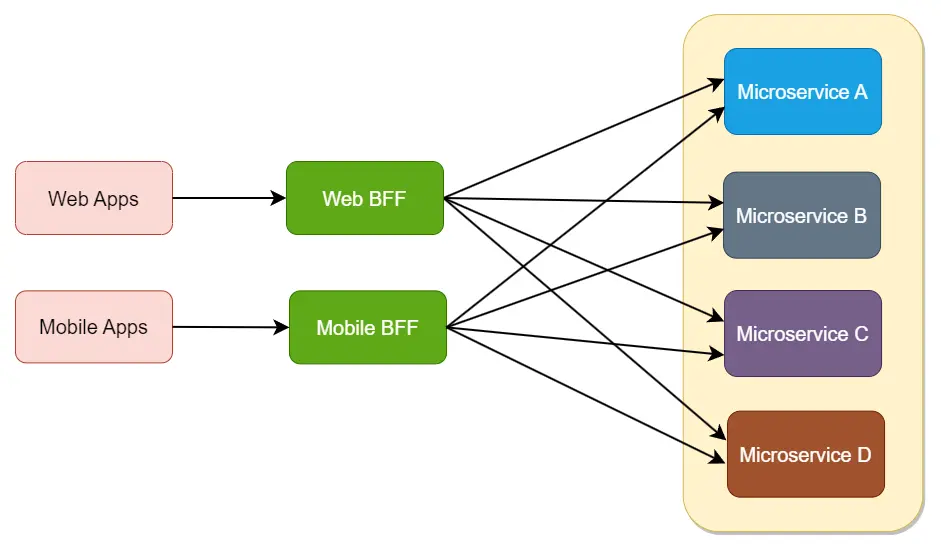
The Backend-for-Frontend (BFF) pattern gives each client type its own thin gateway:
- Mobile BFF: returns a flattened ~8 KB payload with only the fields the phone renders → effect: faster, lighter, fewer client round trips.
- Web BFF: returns the richer nested ~50 KB shape the desktop UI wants.
- Each BFF is owned by the team that owns that frontend → effect: a UI change ships without renegotiating one shared, contested API contract across teams.
Cost introduced: you now run and deploy N gateways instead of 1, and cross-cutting logic (e.g. an auth check or a field rename) can get duplicated across BFFs and drift. Mitigate by keeping shared concerns in the downstream services, not the BFFs. Trade-off: per-client optimization and team autonomy, bought with more deploy units and duplication risk. Use BFF only when client needs genuinely diverge; don't multiply gateways for two near-identical clients.
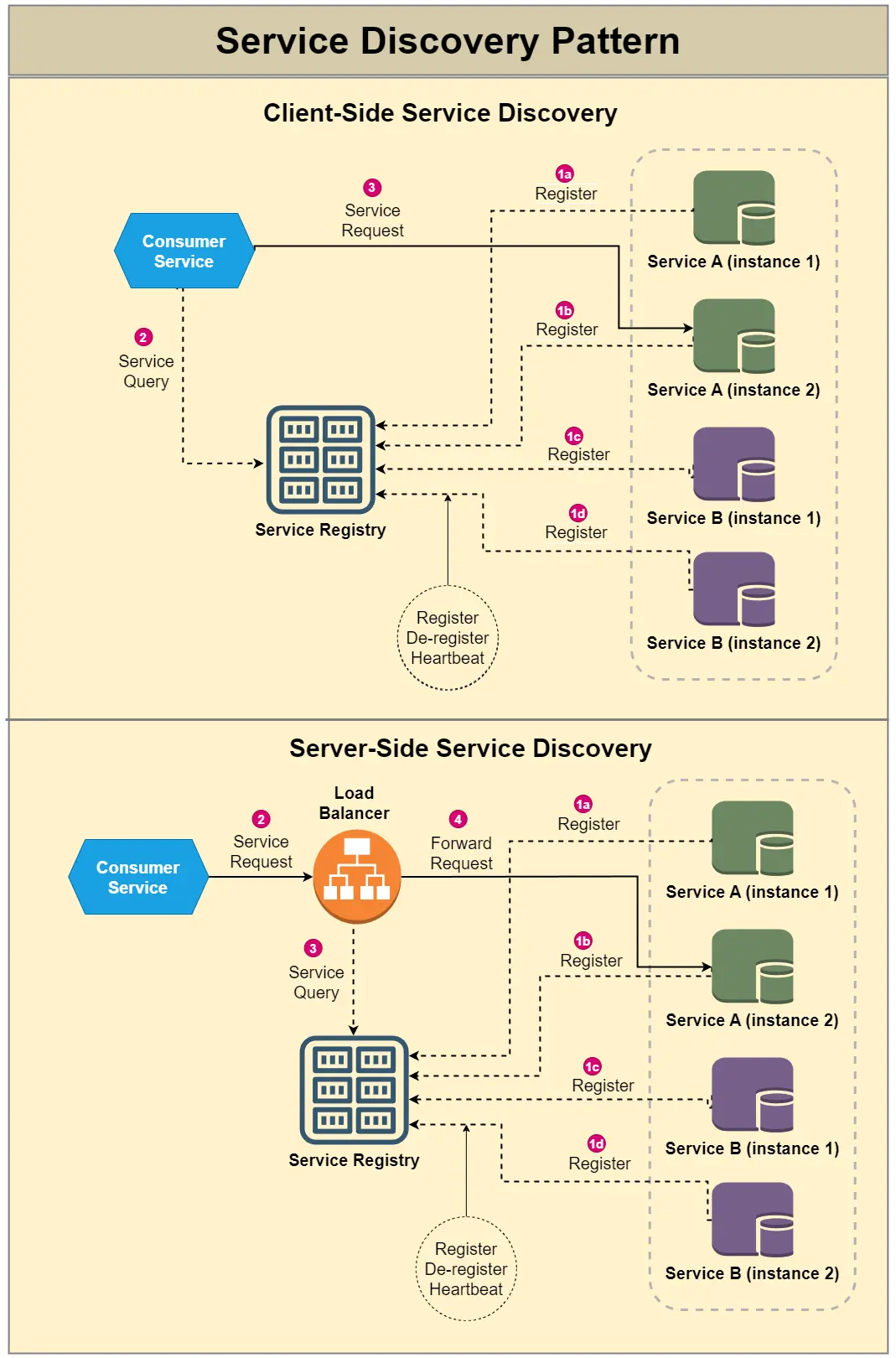
🤔 The Orders service must call the Payments service, but Payments runs 12 instances that autoscale, crash, and get new IPs every few minutes. Hardcoding an IP obviously fails — so how does Orders reliably find a live Payments instance, and what does that machinery cost?
Reveal the reasoning
Hardcoding breaks because instance IPs are ephemeral in a distributed system — autoscaling, redeploys, and node failures churn them constantly. Service Discovery adds a registry as the source of truth for 'who is alive right now':
- Each Payments instance registers itself (IP:port) on startup and sends a heartbeat every ~10 s → effect: the registry always knows the current healthy set.
- Orders queries by logical name (
payments.svc) and gets back live instances, then load-balances across them. - A instance that misses ~3 heartbeats is evicted from the registry → effect: new requests stop being routed to a dead instance within ~30 s, bounding how long callers hit a black hole.
Client-side vs server-side discovery: client-side (caller queries the registry and picks an instance) saves a network hop but puts load-balancing logic in every service; server-side (caller hits a stable LB/router that does the lookup) keeps callers dumb but adds a hop. Kubernetes hides this behind a stable Service VIP + DNS so app code just uses the name.
Cost introduced: the registry is itself a critical, must-be-HA component (run it as a cluster, or it becomes a SPOF), and there's an eviction window — between a crash and the ~3 missed heartbeats, the registry can still hand out a dead instance, so callers still need retries + circuit breakers. Trade-off: dynamic, self-healing routing, paid for with another HA system and eventual (not instant) health consistency.
🤔 Placing an order now spans 3 services with 3 separate databases: Orders, Payment, Inventory. In the monolith this was one ACID transaction. Across services you can't hold a transaction over the network — so if Payment succeeds but Inventory is out of stock, how do you avoid charging a customer for an item you can't ship?
Reveal the reasoning
You can't get atomicity across separate databases without a distributed-transaction coordinator (2PC), and 2PC locks resources across services for the whole transaction → effect: it doesn't scale and blocks everything if the coordinator stalls. The standard answer is the Saga pattern: model the workflow as a sequence of local transactions, each with a compensating action that undoes it:
- Create Order (pending) → Charge Payment → Reserve Inventory → Confirm Order.
- If Reserve Inventory fails → run compensations in reverse: Refund Payment → mark Order cancelled. Effect: no money kept for an unshippable order; the system reaches a consistent end state without ever holding a cross-service lock.
- Orchestration vs choreography: an orchestrator service explicitly drives the steps (easier to reason about / debug, but a central brain), or services react to each other's events (choreography: looser coupling, but the flow is implicit and harder to trace).
Cost introduced: you give up isolation — there's a window where the order is charged but not yet confirmed, so other reads can see intermediate states (no rollback-of-the-whole-world). You must design idempotent steps (a retried 'charge' must not double-charge) and idempotent compensations, and 'refund' is not always a true inverse of 'charge' (fees, time). Trade-off: scalable, lock-free cross-service consistency, bought with eventual consistency and significant workflow/compensation complexity.
🤔 You've drawn gateway → services → per-service DBs, with discovery and sagas. The interviewer asks: 'It's Black Friday, traffic 10x's. What falls over first, and how does a slow Payments service avoid taking down the whole order flow?'
Reveal the reasoning
Walk the request path and name the choke points in order:
- Gateway saturation: single front door = first bottleneck. Defense: it's stateless, so scale it horizontally behind a load balancer; rate-limit/shed load at the edge so excess traffic is rejected cheaply instead of crashing downstream.
- Cascading failure via synchronous calls: if Payments slows to 5 s, every Orders thread waiting on it blocks → Orders' thread pool exhausts → Orders stops serving even requests that don't need Payments. This is the core distributed-systems failure mode. Defense chain: timeout (fail at 100 ms, don't wait 5 s) → circuit breaker (after N failures, stop calling Payments for a cooldown and fail fast) → bulkhead (isolate Payments calls in their own thread pool so they can't starve the rest).
- The hot database: per-service DBs help, but the write-heavy Orders DB (~100 writes/s baseline, ~1,000/s at 10x) is the next limit. Defense: read replicas for reads, caching for hot reads, and async writes via a queue to absorb spikes (the queue buffers bursts so the DB sees a smoother rate).
The honest trade-off summary: microservices removed the 'one deploy, one scaling unit' pain of the monolith and replaced it with network failure modes — partial failure, cascading failure, and eventual consistency. Every pattern here (gateway, discovery, circuit breaker, saga) is a tax you pay to manage failures that simply didn't exist in-process. State that out loud: it shows you understand microservices are a trade, not a free upgrade.
📐 Architecture diagrams (4)
🎯 Guided practice
- Easy — choose the pattern. A team runs a 10-year-old monolithic billing app. Leadership wants microservices but forbids a full freeze-and-rewrite because the system processes live payments. Which pattern, and why?
Step 1: Identify the constraint — no downtime, no big-bang risk. Step 2: Recall that the Strangler Fig pattern (Richardson's "Strangler application") places a facade/proxy in front of the monolith. Step 3: Migrate incrementally — peel off one capability (e.g., "invoice generation") into a new service and route only that traffic to it; the monolith still serves everything else. Step 4: Repeat capability-by-capability until the monolith is "strangled" and can be deleted. Answer: Strangler application, because it allows safe, incremental migration with the old and new systems coexisting behind a routing layer.
- Medium — design a resilience layer. Your Gateway calls a
recommendationsservice that intermittently takes 8 seconds to respond, exhausting the Gateway's threads and dragging down unrelated requests. Design the fix and trace the states.Step 1 — diagnose: A slow dependency holds threads open → resource exhaustion → cascading failure. Retries alone make it worse (more load on a sick service). Step 2 — pick the pattern: wrap the call in a Circuit Breaker. Step 3 — define the states:
CLOSED= calls pass through, failures counted; if failures exceed a threshold (e.g., 50% over a rolling window) the breaker trips toOPEN.OPEN= calls fail fast immediately (no thread held) and return a fallback (e.g., cached or empty recommendations) for a cooldown period. After cooldown →HALF-OPEN= allow a few trial probes; if they succeed, go back toCLOSED; if any fail, return toOPEN. Step 4 — add a timeout (e.g., 1s) so a slow call counts as a failure, and a fallback so the page still renders. Step 5 — combine with retries + exponential backoff and jitter only for transient errors, not for an already-open breaker. Result: the failing dependency is isolated, threads are protected, and the user gets a degraded-but-fast response instead of a stalled page.
✨ Added by the guide — work these before the full problem set.