Caching
Step 7 in the System Design path · 9 concepts · 0 problems
📘 Learn Caching from zero
A cache is a small, fast store (usually in-memory like Redis) that sits in front of a slow source (database, disk, network) and serves a copy of frequently-requested data. In an interview, "add a cache" is the single most common lever for cutting latency and offloading a database — but the interviewer is really testing whether you understand the cost: every cache introduces a consistency problem. Reasoning out loud about hit ratio, invalidation, eviction, and stampede is what separates "I'd add Redis" from a real design.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○Introduction to Caching
- ○Why is Caching Important
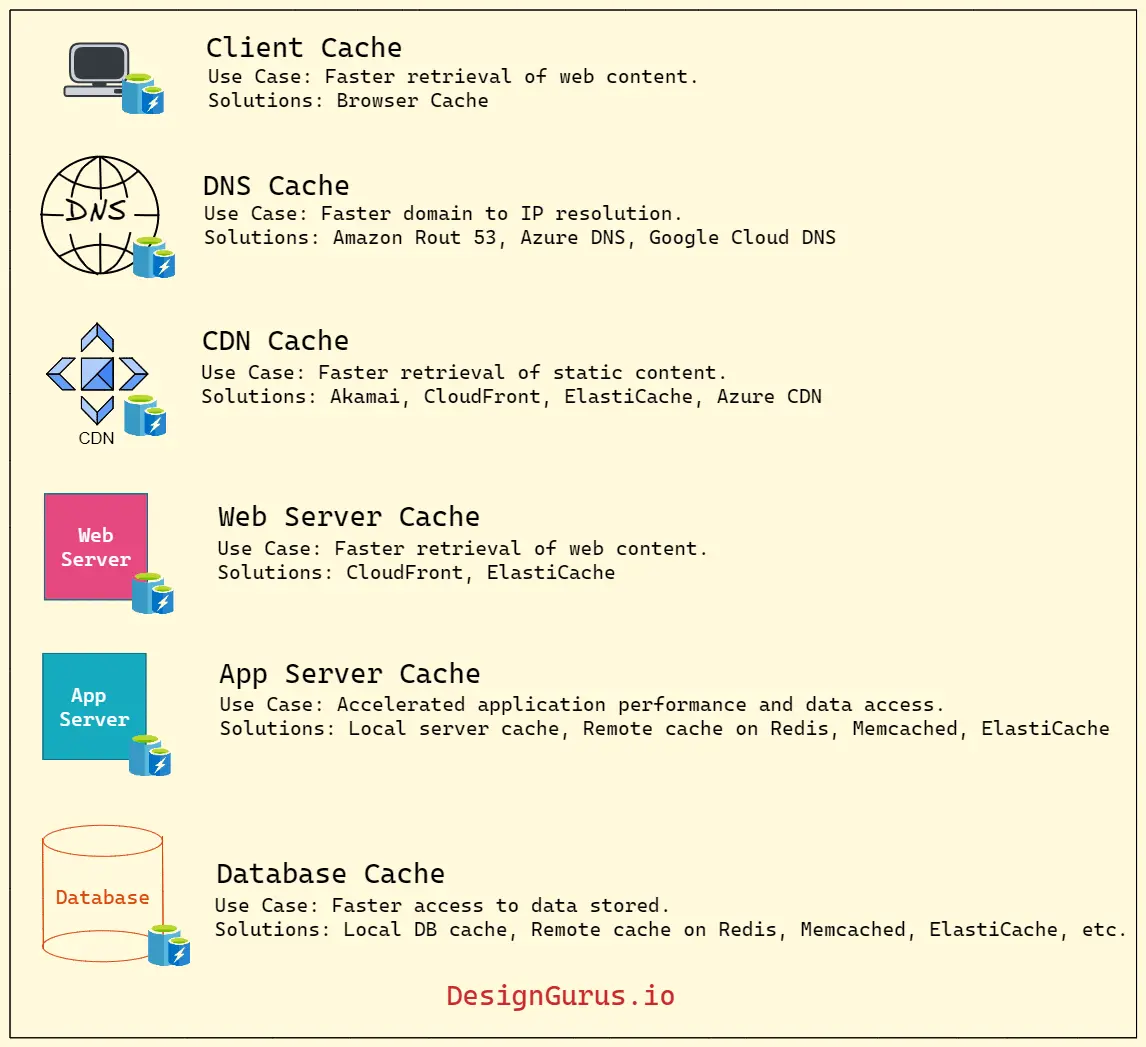
- ○Types of Caching
- ○Cache Replacement Policies
- ○Cache Invalidation
- ○Cache Read Strategies
- ○Cache Coherence and Consistency Models
- ○Caching Challenges
- ○Cache Performance Metrics
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 A read hits a disk-backed DB at ~10 ms. The same query runs 10,000 times/sec. What does putting a copy in RAM actually buy you, in numbers?
Reveal the reasoning
RAM access is ~100 ns vs disk/DB ~10 ms — roughly a 100,000× speed gap. Chain: read goes to RAM instead of disk → per-read latency drops from 10 ms to ~0.5 ms (including the network hop to Redis) → at 10k req/s you also remove most of those queries from the DB → the DB now only sees the small fraction that miss.
Concretely, if 95% of reads hit the cache (95% hit ratio), the DB load drops 20× (from 10k to 500 q/s), and average latency becomes 0.95 × 0.5ms + 0.05 × 10ms ≈ 0.97 ms instead of 10 ms.
Cost it introduces: you now store data in two places, so you own a consistency/staleness problem forever, plus extra infra (the cache cluster) to run and pay for.
🤔 Why does a cache with a 90% hit ratio sometimes still leave your p99 latency at the full 10 ms — even though the average looks great?
Reveal the reasoning
Averages hide the tail. With 90% hits, 1 in 10 requests still misses and pays the full DB cost. The hits are fast (~0.5 ms), so the bulk of the distribution looks great — but the slowest 10% of requests are exactly the misses, so the p99 lands inside the miss path and sits near 10 ms.
Chain: lower hit ratio → more requests fall through to the slow path → the tail (p99/p999) is set by the miss path, not the hit path. Pushing hit ratio from 90% → 99% is what actually pulls the tail down, because now only 1 in 100 pays full price, so the 99th percentile finally falls on a fast hit instead of a miss.
Key metric: hit ratio = hits / (hits + misses). Cost: chasing a higher hit ratio usually means caching more data → more memory → more money, with diminishing returns once you're caching cold, rarely-reused keys.
🤔 With cache-aside (lazy loading), your app checks the cache, and on a miss reads the DB and writes the value back. What happens to the very first request for any key — and how is that different from read-through?
Reveal the reasoning
Cache-aside: the app is in control. On a miss: app reads DB → writes the result into the cache → returns it. So the first request for each key always misses and pays full DB cost (a 'cold cache'); subsequent reads are fast. Pros: only requested data is cached (memory-efficient), and a cache outage degrades to slow reads rather than broken reads. Con: the app repeats the miss-handling logic everywhere, and there's a window where stale data can be served.
Read-through: the cache layer itself fetches from the DB on a miss, so the app only ever talks to the cache. Cleaner app code, but you depend on the cache layer for correctness and availability.
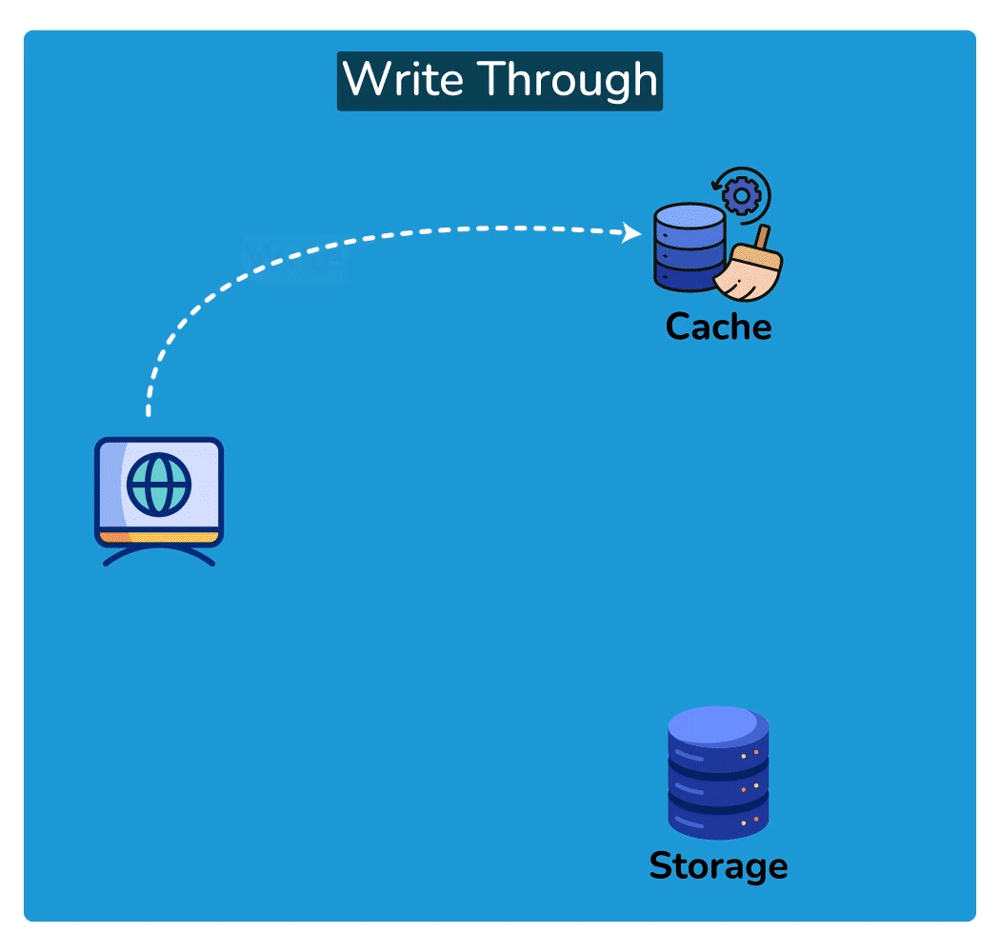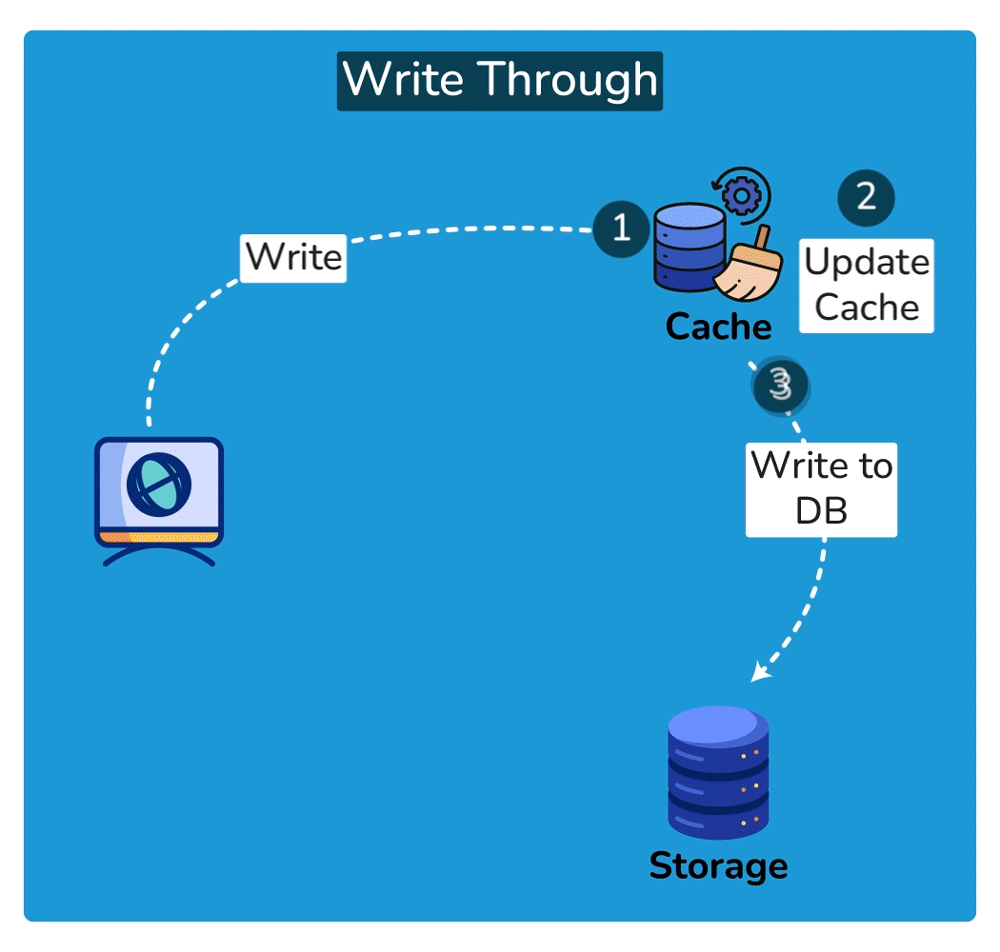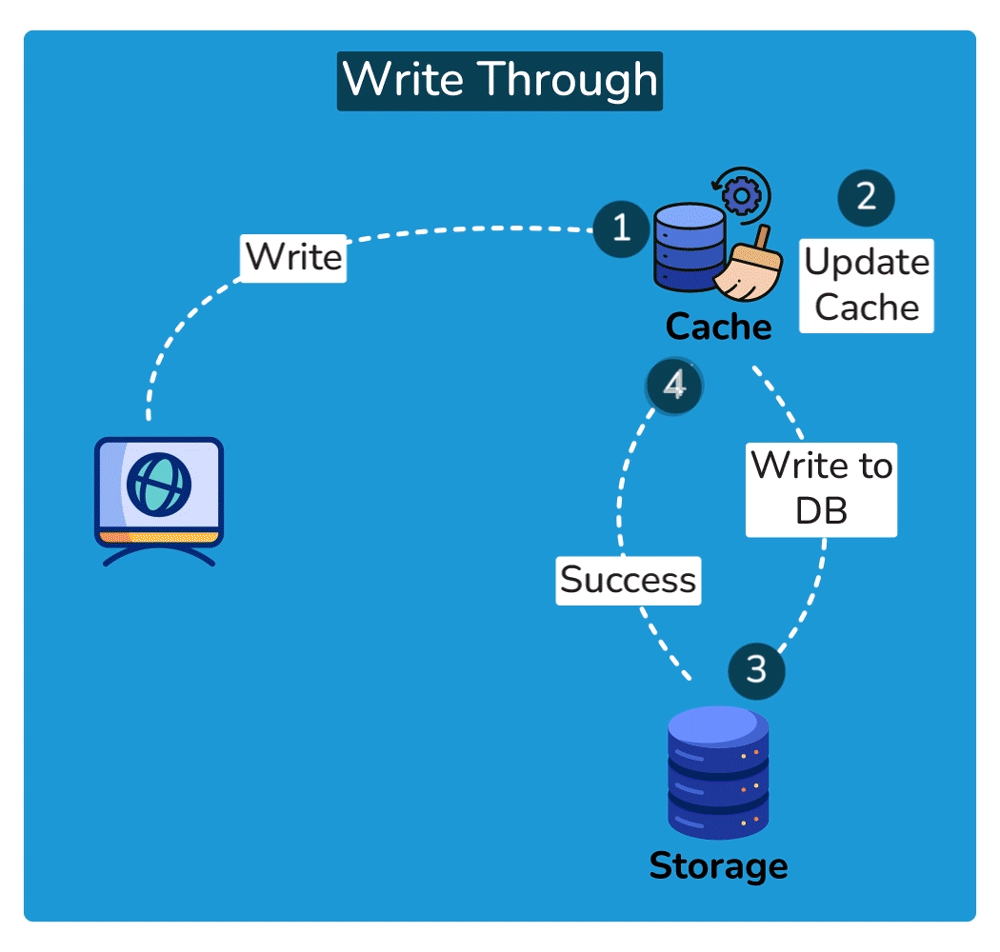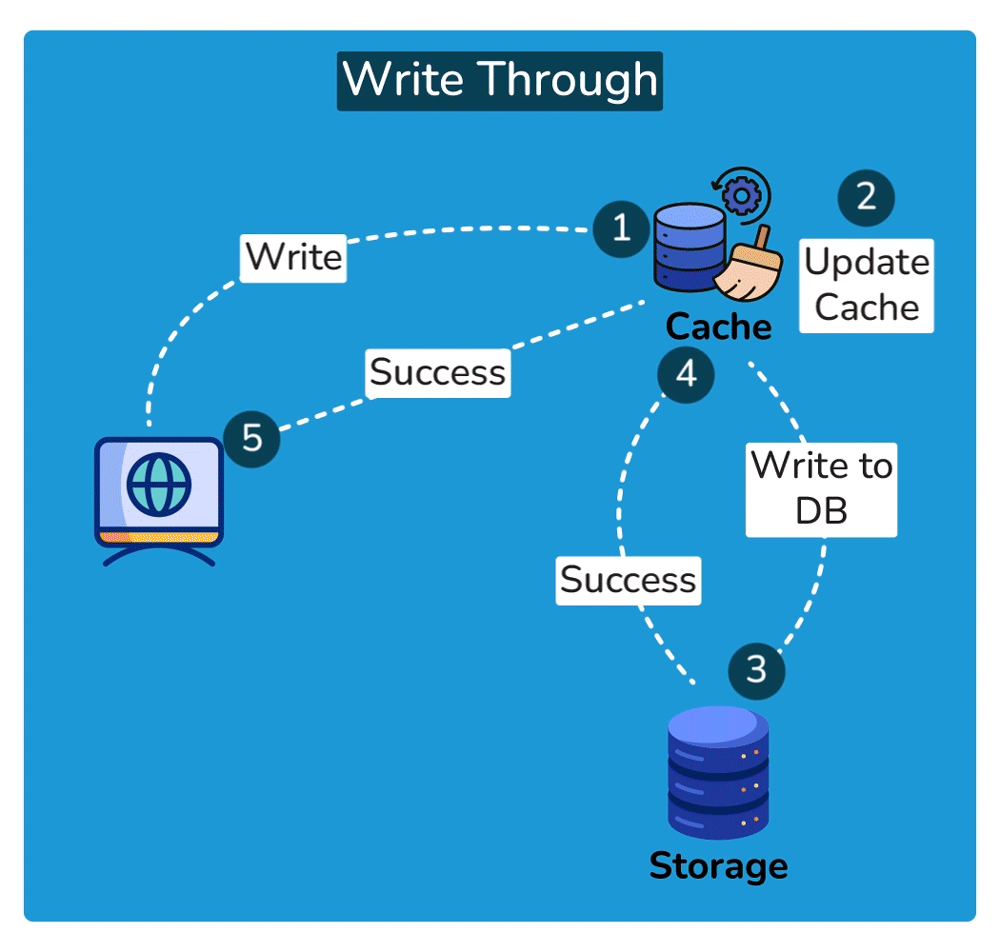
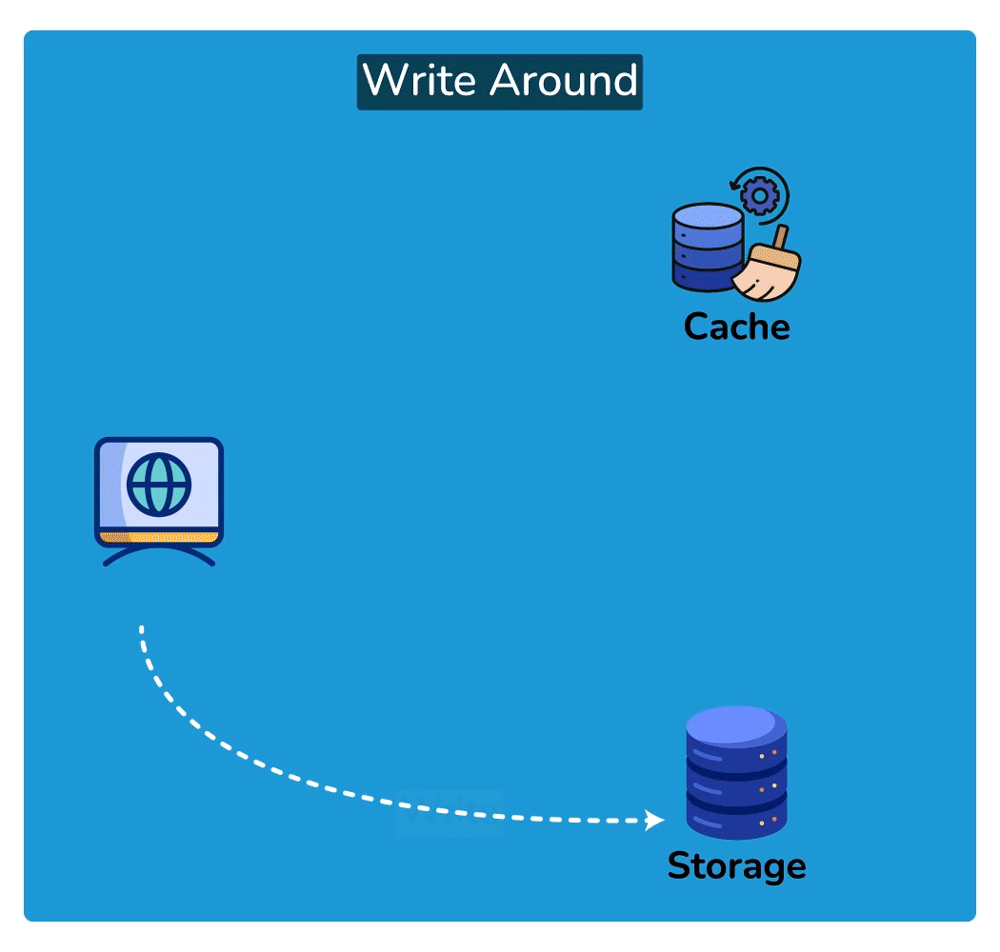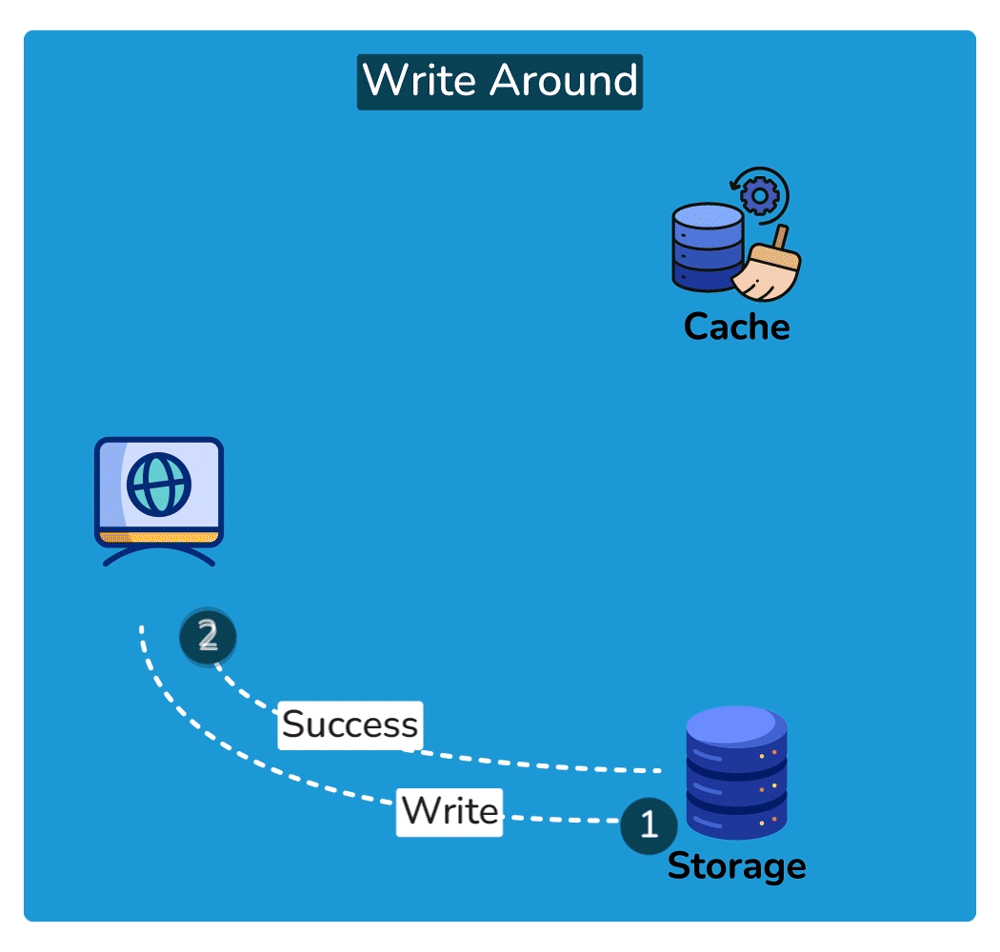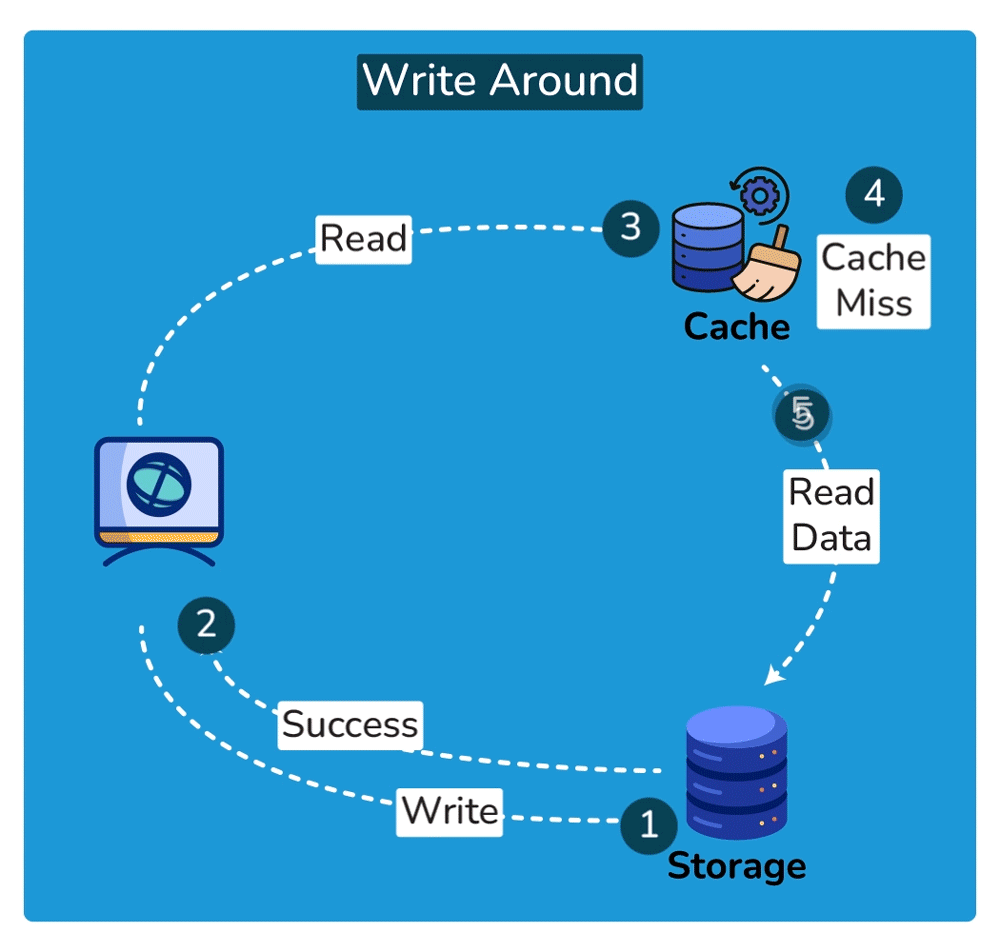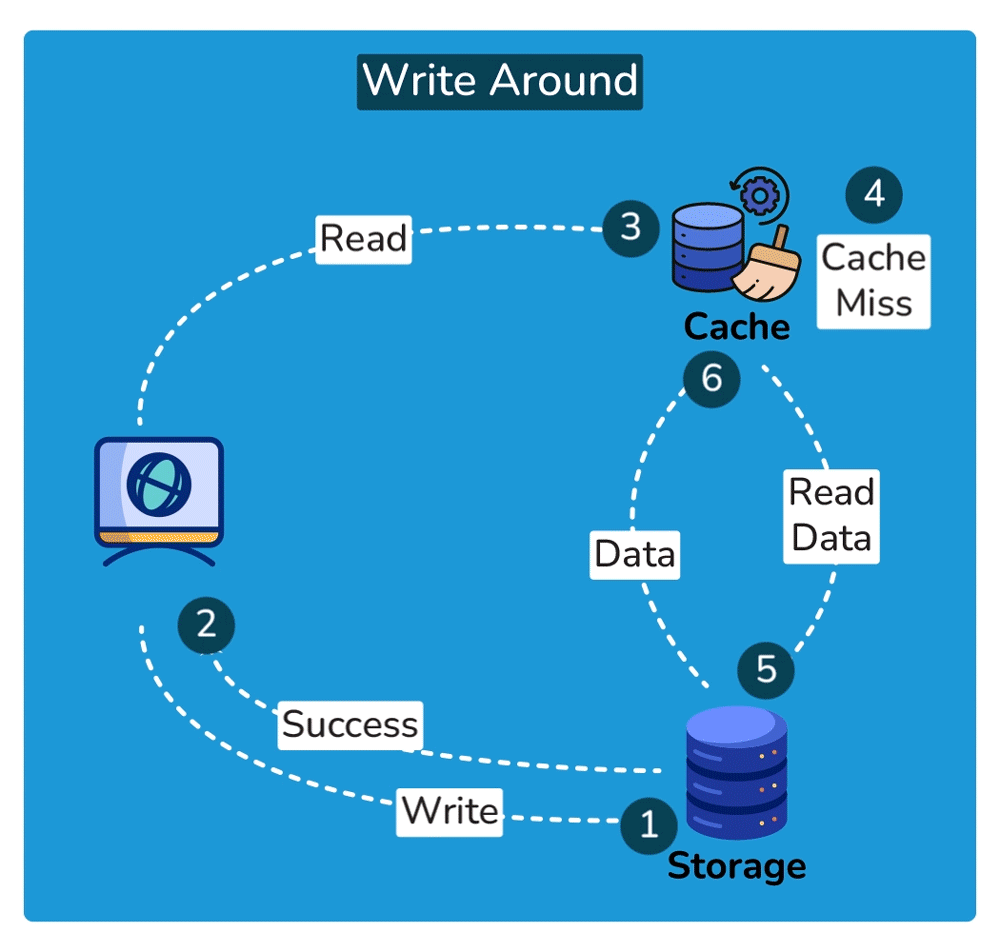
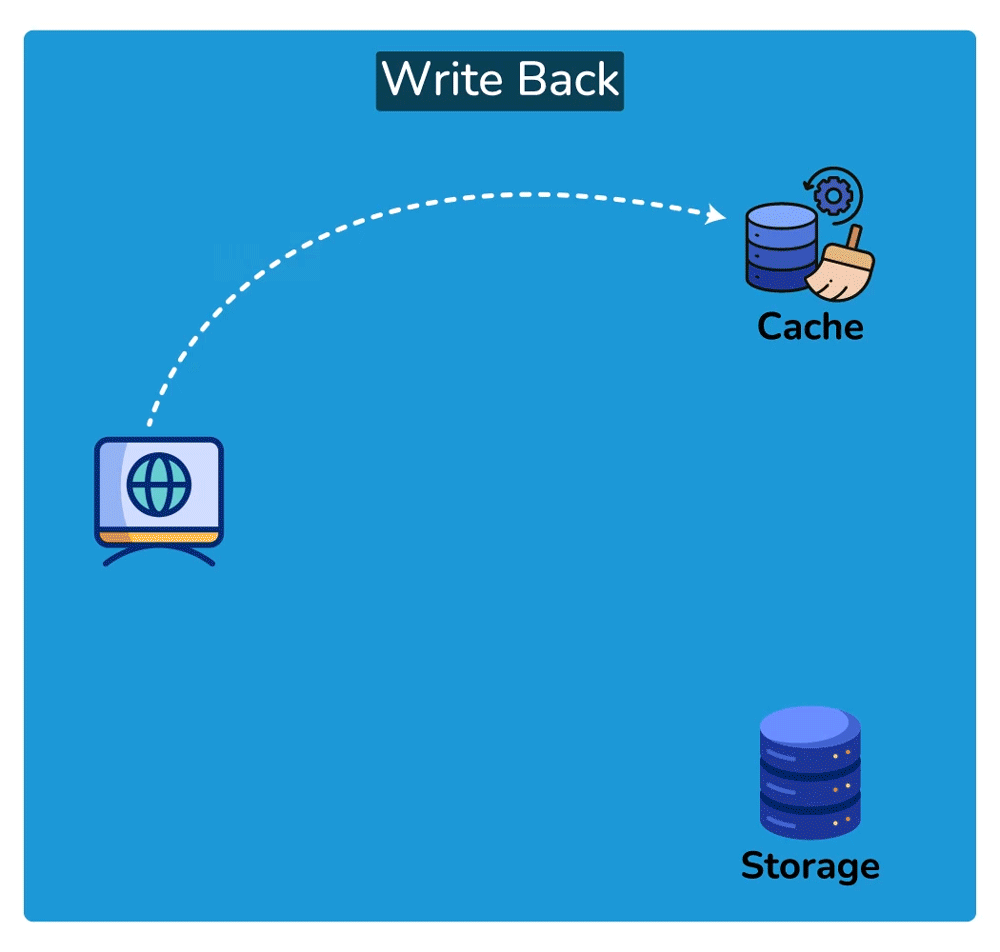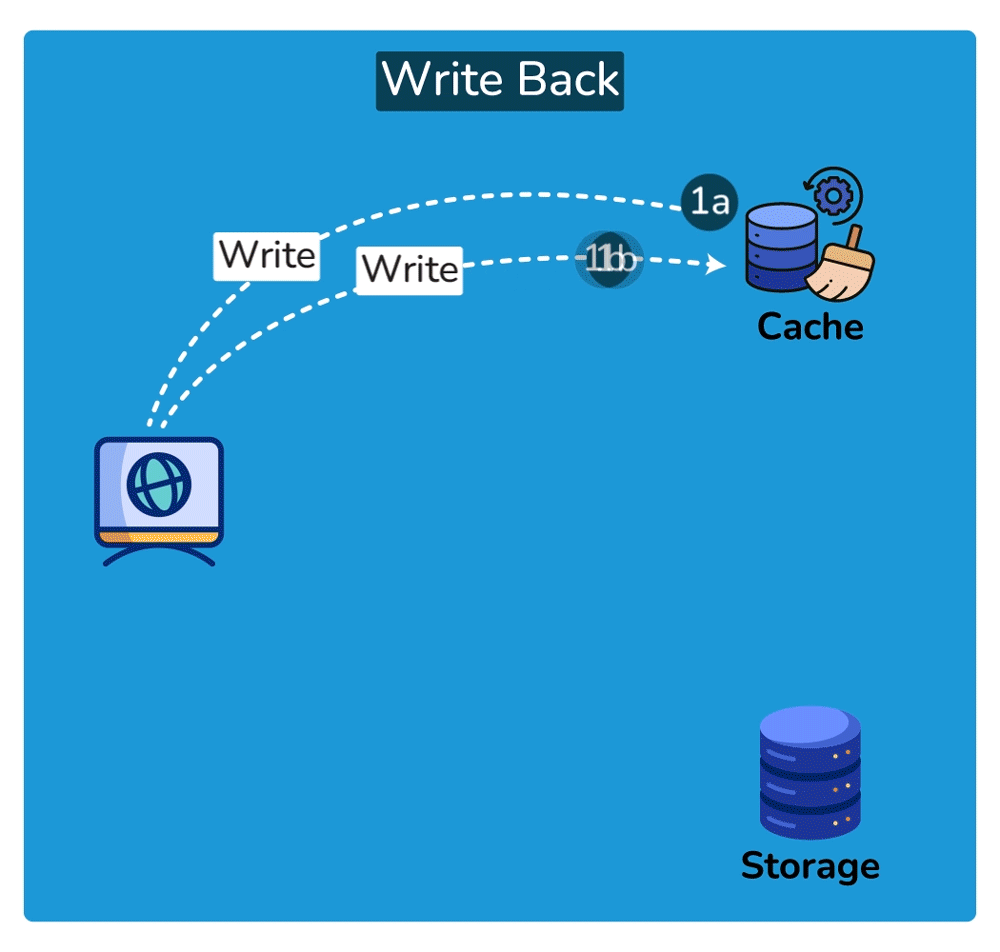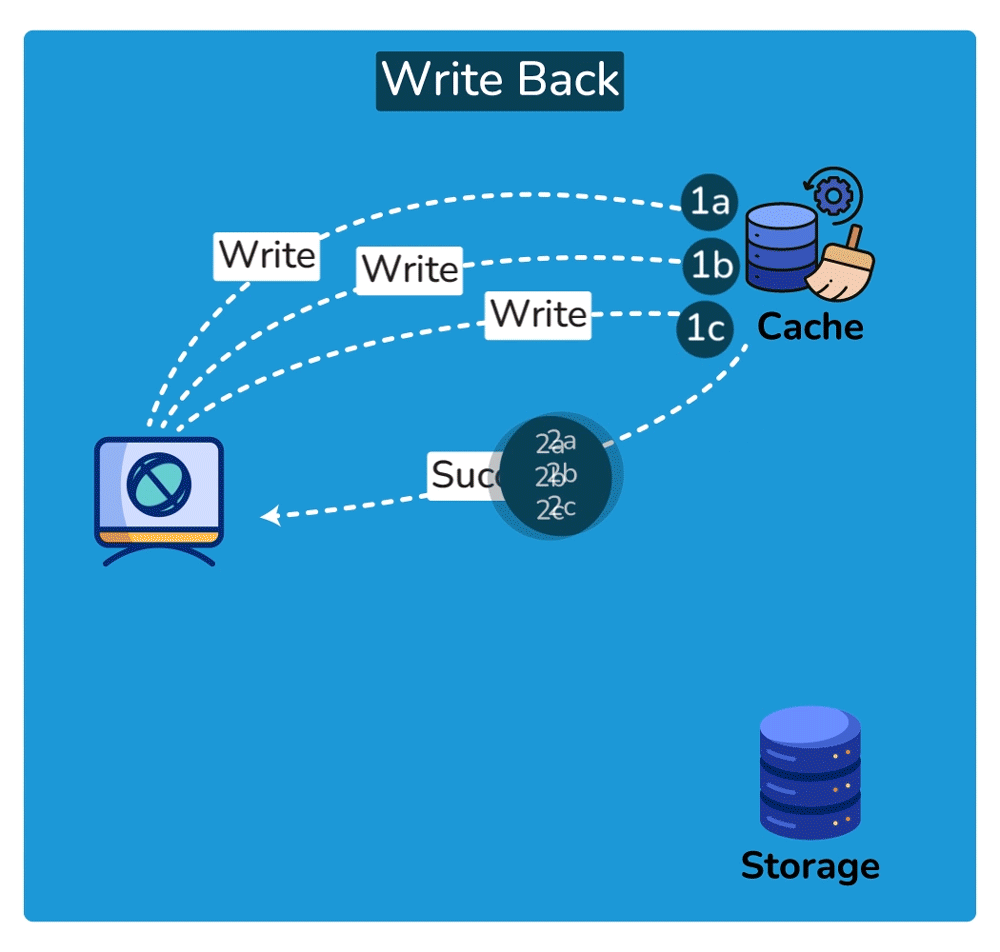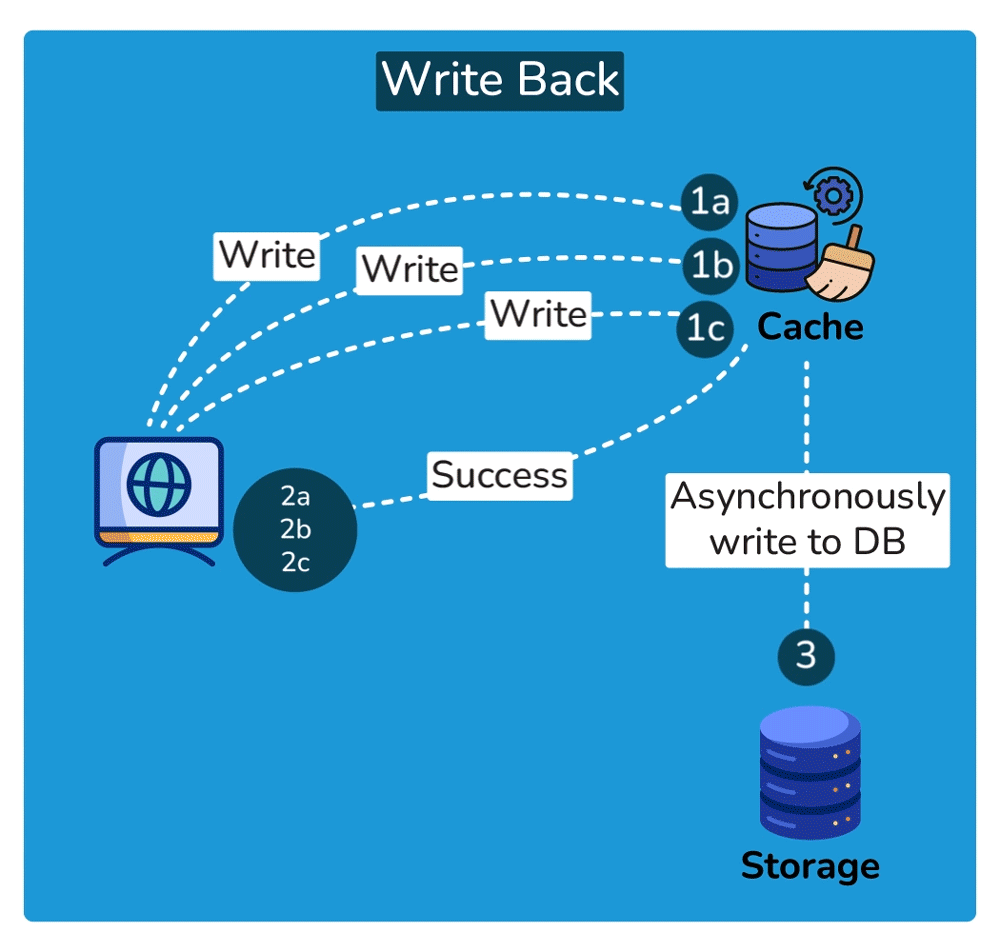
Write strategies pair with these (trade-offs): write-through writes to cache + DB synchronously — consistent, but slower writes; write-back writes to cache and flushes to the DB later — fast writes, but risk of data loss if the cache dies before the flush.
🤔 Your cache holds 10 GB but the working set is 50 GB. When it fills up, why does LRU usually beat FIFO for hit ratio — and when does LRU fail badly?
Reveal the reasoning
LRU (Least Recently Used) evicts whatever hasn't been touched longest. Chain: real traffic is skewed (a hot 10% of keys gets ~90% of reads) → recently-used keys are likely to be used again soon → keeping them maximizes future hits. FIFO evicts the oldest-inserted item regardless of usage, so it can throw out a red-hot key just because it was loaded early — tanking hit ratio.
Where LRU fails: a large sequential scan (e.g. a batch job reading 50 GB once) floods the cache with one-time keys → those recent-but-useless keys push out your hot set. This is cache pollution. LFU (Least Frequently Used) resists it by keeping high-count items, but it reacts slowly when popularity shifts (a formerly-hot key lingers).
Cost: LRU must track recency (a linked list / timestamps) → extra memory and per-access bookkeeping. No policy is free — you trade metadata overhead plus a workload assumption for hit ratio.
🤔 Phil Karlton quipped that cache invalidation is one of the two hard problems in CS. Concretely: a user updates their profile, you write the DB but forget the cache. What goes wrong, and what are your two main tools to bound it?
Reveal the reasoning
Chain: the DB now holds the new value, the cache still holds the old one → every read keeps hitting the cache → users see stale data until that key is evicted, which could be never. The cache and the source-of-truth have diverged with no automatic reconciliation.
Tool 1 — TTL (time-to-live): set e.g. TTL = 60s so the key auto-expires. This bounds staleness to at most 60s with zero explicit invalidation logic. Cost: a tuning knob — short TTL → fresher data but lower hit ratio (more misses); long TTL → higher hit ratio but staler data.
Tool 2 — explicit invalidation: on write, delete or update the cache key. Fresher, but you must reliably reach every place the key is cached, and a write-then-read interleaving can re-populate the cache with the old value (a stale-set race). Many systems combine both: explicit delete on write plus a TTL as a safety net.
🤔 Why do almost all real caches choose eventual consistency over strong consistency — and what's one concrete anomaly a user can observe because of that choice?
Reveal the reasoning
Strong consistency would require every write to synchronously update or invalidate the cache before returning — and across a multi-node cache, coordinate every replica first. Chain: that coordination adds round-trips and locking on the write path → writes get slower and the cache stops being 'fast' → you've defeated its purpose. So caches accept eventual consistency: the cache converges to the truth after a short delay (the TTL window or replication lag).
Observable anomaly: a read-your-own-writes violation — a user updates their bio, the write lands in the DB, but their next read hits a cache entry (or replica) that still has the old value, so for a few seconds they see their old bio and think the save failed.
Cost: you accept a bounded window of stale/divergent reads in exchange for low latency and high throughput. Fixing the specific anomaly (e.g. routing a user's reads so they reflect their own recent writes) adds complexity to the read path.
🤔 A super-popular key with TTL=60s expires at exactly noon. 50,000 requests/sec are reading it. What happens in the millisecond after it expires, and why can it take down your DB?
Reveal the reasoning
This is a cache stampede (a.k.a. thundering herd / dogpile). Chain: the key expires → the next request misses → but so do all the concurrent requests in that instant, because none of them find the key → they all hit the DB simultaneously for the same value → the DB that normally sees ~500 q/s suddenly takes a 50,000-query spike (100×) → it saturates, latency explodes, and because the recompute is now slow the cache stays empty, so the herd keeps arriving.
Fixes (each with a cost): request coalescing / locking — only one request recomputes while the rest wait for its result (adds a lock plus wait latency); early / probabilistic recompute — refresh the key slightly before it expires so it never goes fully cold (occasional wasted recomputes); jittered TTLs — randomize expiry so many keys don't expire at the same instant (freshness becomes slightly less predictable).
🤔 You're told 'just add a cache to make it faster.' Name a case where a cache hurts — where you'd push back in the interview.
Reveal the reasoning
Caching pays off only when reads repeat and data is read-heavy and reasonably stable. When those don't hold, it actively hurts:
- Low / zero reuse (unique keys, one-off analytics scans): hit ratio is near 0% → you pay the cache lookup + memory but still hit the DB every time → net slower and more expensive than no cache.
- Write-heavy, rapidly-changing data: you invalidate keys faster than you read them → constant churn, near-zero hit ratio, plus you've added a consistency risk for no latency win.
- Strong-consistency requirements (account balances, inventory at checkout): any staleness window is unacceptable → reading a stale value can cause double-spend or oversell, so the safe answer is don't cache (or cache only with synchronous write-through and accept the slower writes).
The interview move: before adding a cache, state the access pattern you're assuming — high reuse, read-heavy, staleness-tolerant. If you can't justify all three, say so. 'A cache is a bet that the same data gets read again before it changes; if that bet is wrong, it's pure overhead.'
📐 Architecture diagrams (8)




🎯 Guided practice
- (Easy) Compute the hit ratio and average latency. A cache serves 8,000 requests as hits and 2,000 as misses. A hit costs 2 ms; a miss costs 40 ms (lookup + origin fetch).
Reasoning: First,
hit ratio = hits / (hits + misses) = 8000 / 10000 = 0.8(80%), so miss ratio = 0.2. Average latency is the weighted average:0.8 × 2 ms + 0.2 × 40 ms = 1.6 + 8.0 = 9.6 ms. The takeaway: even at 80% hits, the 20% of misses dominate the average because the miss penalty is 20× the hit cost. The lesson FAANG interviewers probe: raising the hit ratio matters most when the miss penalty is large — that is exactly when a cache is worth building, and why you optimize for the hot keys. - (Medium) Trace an LRU cache of capacity 2 and explain the eviction. Operations on a key→value LRU cache (capacity 2):
put(1,A),put(2,B),get(1),put(3,C),get(2). What does the finalget(2)return, and why?Reasoning — track recency, most-recent on the right:
1)put(1,A)→ order[1].
2)put(2,B)→ order[1, 2](now full).
3)get(1)returns A and marks 1 as most-recently-used → order[2, 1]. This is the step people forget: a read counts as a use and reorders recency.
4)put(3,C)→ cache is full, so evict the least-recently-used, which is now 2, not 1. Order becomes[1, 3].
5)get(2)→ key 2 was evicted, so this is a miss (returns null / not found).
Why it matters: the answer hinges onget(1)rescuing key 1 from eviction. To do every operation in O(1), back the cache with a hash map (key → node) plus a doubly linked list ordering nodes by recency: the map gives O(1) lookup, and the list lets you move-to-front and pop-the-tail in O(1). Contrast with FIFO, which evicts by insertion order and ignores reads entirely:get(1)changes nothing, so onput(3,C)FIFO evicts 1 (the oldest insert), leaving[2, 3]— and the laterget(2)would be a hit. Same trace, opposite outcome, purely because of how each policy treats a read.
✨ Added by the guide — work these before the full problem set.