System Design Problems
Step 29 in the System Design path · 15 concepts · 12 problems
📘 Learn System Design Problems from zero
System design interviews test how you reason under ambiguity, not whether you memorized an architecture. The interviewer wants to watch you drive a vague prompt ("design Twitter") to a concrete, defensible design by following a repeatable framework: clarify requirements and scale, estimate the numbers, define the API, model the data, sketch a high-level diagram, dive into one hard component, then attack your own bottlenecks. Each step below is a question first. Force yourself to answer out loud before you reveal the reasoning, because in the real interview talking through the trade-off is exactly what earns the signal.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○Designing a URL Shortening Service like TinyURL
- ○Designing Pastebin
- ○Designing Instagram
- ○Designing Dropbox
- ○Designing Facebook Messenger
- ○Designing Twitter
- ○Designing Youtube or Netflix
- ○Designing Typeahead Suggestion
- ○Designing an API Rate Limiter
- ○Designing Twitter Search
- ○Designing a Web Crawler
- ○Designing Facebook Newsfeed
- ○Designing Yelp or Nearby Friends
- ○Designing Uber backend
- ○Designing Ticketmaster
- ○medium Designing Gmail
- ○medium Designing Google News
- ○medium Designing Notification Service
- ○medium Designing Code Judging System
- ○medium Designing YouTube Likes Counter
- ○medium Designing Reddit
- ○medium Design Google Calendar
- ○medium Design a Recommendation System
- ○medium Designing Unique ID Generator
- ○hard Designing Payment System
- ○hard Designing Reminder Alert System
- ○hard Designing Flash Sale System
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 The interviewer says "design Twitter." Before drawing a single box, what is the very first thing you should do, and why is it the highest-leverage move in the whole interview?
Reveal the reasoning
Clarify functional vs non-functional requirements and explicitly cut scope. Cause→effect chain:
- You ask "is this read-heavy or write-heavy? Do we need the timeline, DMs, search, trending — or just post + follow + timeline?" → the interviewer narrows it to post a tweet, follow users, view home timeline.
- That narrowing → you commit to non-functional goals: highly available, eventual consistency is OK (a tweet showing up 1–2s late is fine), timeline latency under ~200ms.
- Defining "eventual consistency is acceptable" up front → unlocks aggressive caching and async fan-out later, which a strongly-consistent design would forbid.
Trade-off / cost: every feature you keep (search, media, trending) multiplies the design surface. Spending 3–5 minutes cutting scope costs you a little time now but prevents the far worse outcome of running out of time with a half-built everything. The risk is cutting too much and looking like you don't understand the product — so name what you're deferring, don't pretend it doesn't exist.
🤔 You're told there are 200M daily active users. Roughly how many tweet-writes per second, and how many timeline-reads per second, should you plan for — and why does that ratio change your design?
Reveal the reasoning
Do the back-of-envelope math out loud. Cause→effect chain:
- 200M DAU, each posts ~2 tweets/day → 400M writes/day ÷ 86,400s ≈ ~4,600 writes/sec (call it ~5K, peak maybe 2–3× → ~12K/s).
- Each user refreshes the timeline ~20 times/day → 4B reads/day ÷ 86,400 ≈ ~46,000 reads/sec (peak ~100K/s).
- Reads outnumber writes ~10:1 → this is a read-heavy system → you should precompute timelines (fan-out on write) and cache hard, rather than building the timeline fresh on every read.
- Storage: 400M tweets/day × ~300 bytes ≈ 120 GB/day → ~44 TB/year of text alone → you'll need sharding and a plan for cold-data archival.
Trade-off / cost: these estimates justify your architecture, but precision is a trap. If you spend 10 minutes computing exact byte counts you've burned your design time. Round aggressively, state assumptions, and move on — the number's job is to point you at "read-heavy, must precompute," not to be audited.
🤔 Before any database or service boxes, why is it worth pinning down the exact API signatures like postTweet(userId, content) and getTimeline(userId, pageToken)?
Reveal the reasoning
The API is the contract that constrains everything downstream. Cause→effect chain:
- Writing
getTimeline(userId, pageToken, count)→ forces you to admit timelines are paginated with a cursor, not an offset → because offset pagination (LIMIT 20 OFFSET 10000) makes the DB scan and discard all 10,000 skipped rows, so cost grows with how deep you scroll, while a cursor (last-seen tweet ID/timestamp) is an index seek whose cost stays roughly constant regardless of scroll depth. - Including an
apiKey/ auth token param → signals you'll rate-limit and authenticate at the gateway, not inside business logic. - Defining the response shape (list of tweet IDs vs hydrated tweet objects) → decides whether the timeline service returns IDs and clients hydrate separately, which keeps the timeline payload tiny and cacheable.
Trade-off / cost: a cursor-based API is harder to implement and can't easily "jump to page 500," but for an infinite-scroll feed nobody jumps to page 500, so you pay almost nothing for a big scalability win. The cost of skipping the API step is that you design services with mismatched assumptions and discover the contract conflict mid-diagram.
🤔 You have users, tweets, and a follow graph. Would you store all three in one relational database, and what specifically breaks if you do at this scale?
Reveal the reasoning
Split by access pattern, not by tidiness. Cause→effect chain:
- Tweets are append-only, huge volume, queried by author and by ID → store in a wide-column / NoSQL store (e.g. Cassandra) sharded by tweet ID → because 44 TB/year won't fit one SQL node and you never need cross-tweet JOINs on the hot path.
- The follow graph (who-follows-whom) is relationship-heavy and read constantly during fan-out → a dedicated followers table indexed by
followeeId → [followerIds]→ because fan-out needs "give me everyone who follows Alice" in one cheap lookup. - User profiles are low-volume, need strong consistency (email, password) → keep in a relational store.
Trade-off / cost: splitting into three stores means no foreign keys and no transactional JOIN across them — you accept eventual consistency and must handle dangling references (a tweet whose author was deleted) in application code. That's the price of each store scaling independently. A single Postgres is simpler and fully consistent but caps you at one machine's write throughput, which ~12K writes/sec will eventually blow past.
🤔 When a tweet is posted, should the system build all the followers' timelines right then (fan-out on write), or build each timeline lazily when a user opens the app (fan-out on read)? What pushes you toward one?
Reveal the reasoning
Pick fan-out based on the read:write ratio you computed earlier. Cause→effect chain:
- Reads are ~10× writes → you'd rather do work once on the rare write than repeatedly on the frequent read → favor fan-out on write: on post, push the tweet ID into every follower's precomputed timeline cache (a Redis list per user).
- Result →
getTimelinebecomes a single cache read of pre-merged IDs → ~200ms target is easily met because there's no merging at read time. - The write goes async through a message queue (Kafka) → the post API returns immediately while a fan-out worker fills timelines in the background.
Trade-off / cost: fan-out on write explodes for celebrities — a user with 100M followers triggers 100M cache writes per tweet, and most of those followers are inactive, so you've burned huge work for nothing. That's the celebrity / hot-key problem, and naming it here is exactly what sets up your deep-dive. Fan-out on read avoids that explosion but makes every timeline load do an expensive merge, missing your latency target for normal users.
🤔 Given that pure fan-out-on-write dies on celebrities and pure fan-out-on-read is too slow for everyone, what hybrid actually ships at Twitter scale?
Reveal the reasoning
Use a hybrid keyed on follower count. Cause→effect chain:
- For normal users (say under ~10K followers) → fan-out on write as before → cheap because the fan-out is bounded and most timelines stay warm.
- For celebrities (millions of followers) → do NOT fan out; their tweets are pulled at read time → because writing to 100M lists per tweet is wasteful when those followers' timelines are read far less often than the celebrity tweets.
- At read time → merge the user's precomputed timeline (from normal follows) with a fresh pull of the handful of celebrities they follow → a small merge of, say, 50 precomputed + 20 celebrity tweets → still well under 200ms.
Trade-off / cost: the hybrid adds real complexity — you now maintain two code paths, a threshold to tune, and a merge step that must dedupe and re-sort by time. You also need to define what "celebrity" means and handle a user crossing the threshold. This is the right level of detail for a deep-dive: you're trading implementation complexity for the only design that survives both the common case and the worst case.
🤔 Your design is drawn and works on paper. The interviewer asks "what falls over first under load?" Where do you point, and how do you defend it?
Reveal the reasoning
Proactively attack your own design — naming failure modes before the interviewer does is high signal. Cause→effect chain:
- The timeline cache (Redis) is the hottest component → if a node dies, thousands of timelines vanish at once → mitigate with replication + sharding by userId, and treat the cache as rebuildable: the source of truth is the tweet store and the follow graph → so a lost cache node degrades to a slower read while it rebuilds, not data loss.
- The fan-out worker queue is the second pressure point → a sudden spike (a celebrity event, a viral moment) backs up Kafka → because workers can't drain fan-out fast enough → mitigate by scaling workers horizontally and letting the queue absorb the burst, so the post API stays fast and timelines just lag a few seconds (acceptable under your eventual-consistency goal from step 1).
- A single celebrity's tweet is a hot key at read time → every follower pulls the same record → mitigate by caching that celebrity's recent tweets in a small, heavily-replicated hot cache so the read load spreads across replicas instead of hammering one shard.
Trade-off / cost: every mitigation buys resilience by spending money and complexity — replicas double your cache footprint, more workers cost compute, and a hot-tweet cache is another layer to keep coherent. The reason it's worth it: each one converts a hard failure (data loss, a stalled write path, a melted shard) into graceful degradation (a slower read, a few seconds of lag). That trade — paying steady infrastructure cost to avoid catastrophic, user-visible outages — is the judgment the interviewer is listening for, and it loops straight back to the consistency and latency targets you committed to in step 1.
📐 Architecture diagrams (8)

🎯 Guided practice
Let's walk through Designing a URL Shortening Service like TinyURL — the canonical warm-up that exercises the whole template.
- Requirements (functional). Confirm: given a long URL, return a short alias; hitting the short URL redirects to the original; optional custom alias and expiration. Signal: it's a near-CRUD service, so the real interest is scale and ID generation, not features.
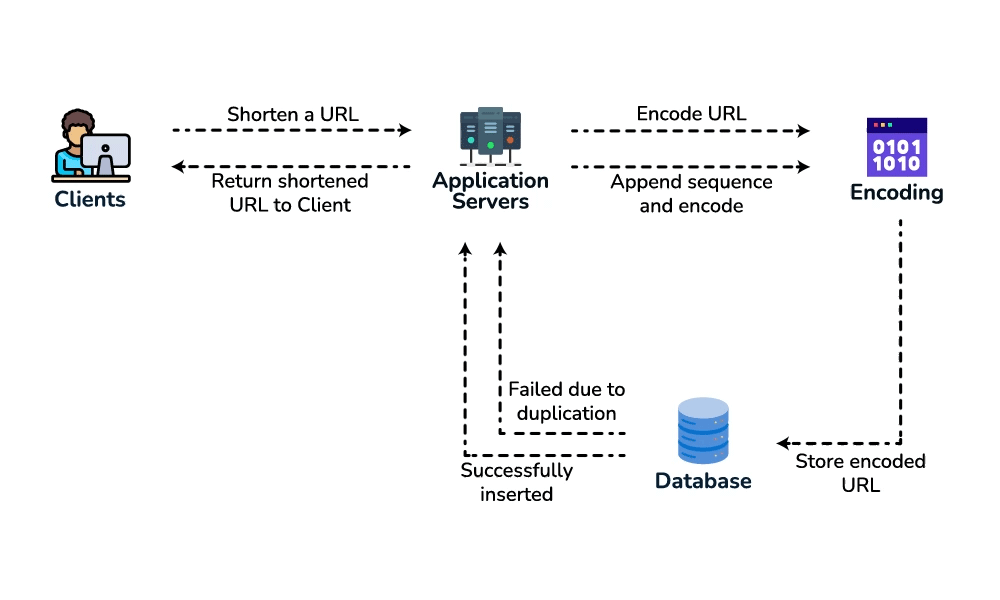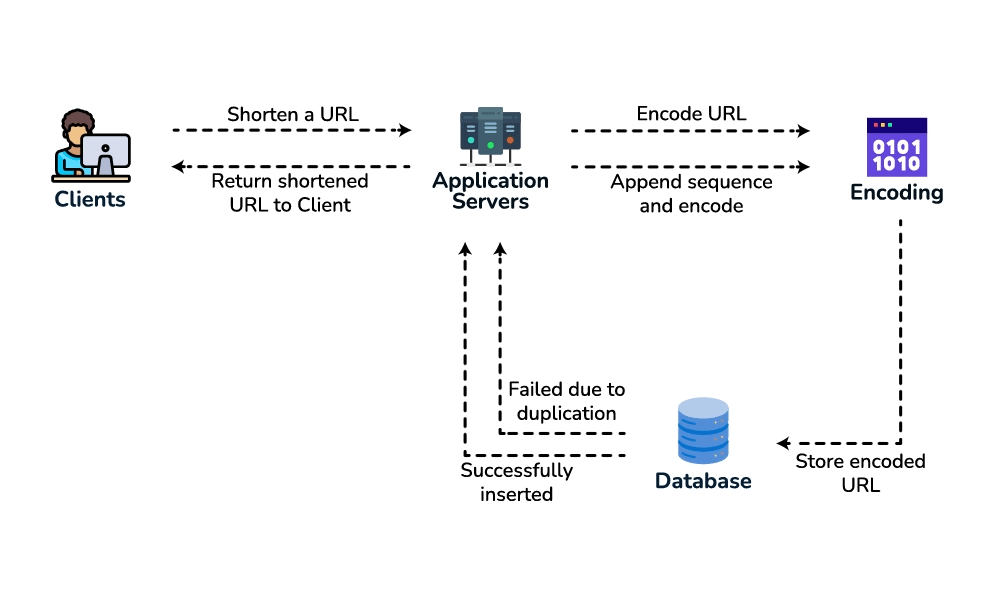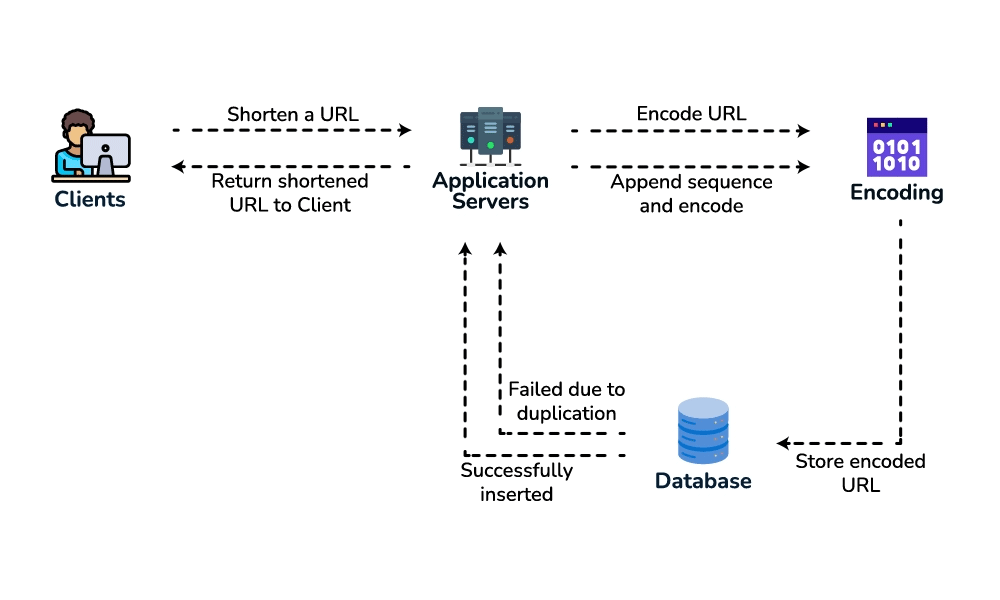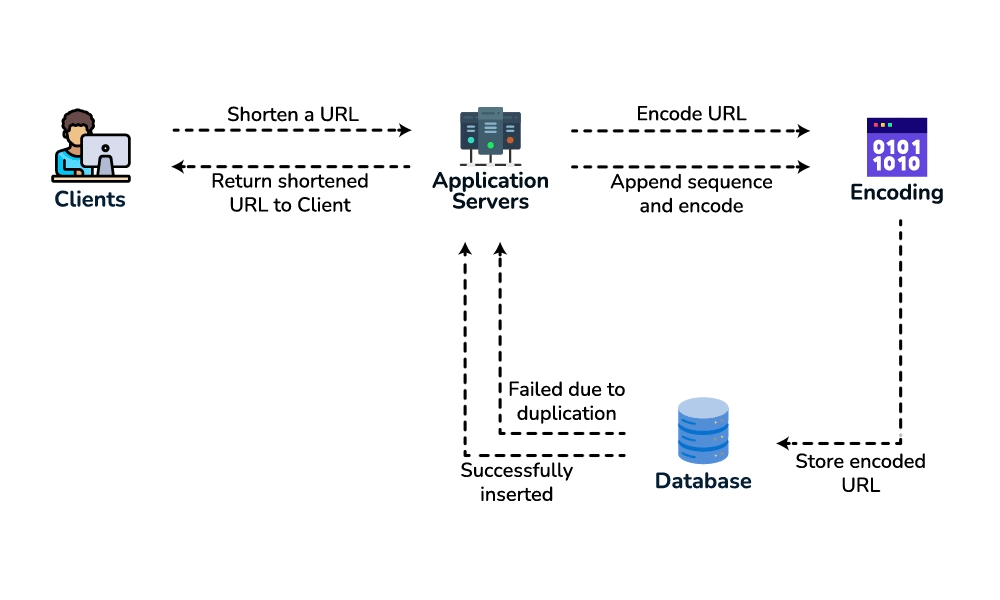
- Non-functional + estimation. Ask the read:write ratio — for URL shorteners it's heavily read-heavy (~100:1). That single fact is the biggest signal: cache the redirects and optimize the read path. Say 100M new URLs/day → ~1,160 writes/sec and ~116K reads/sec. Over 10 years → ~365B URLs. Since base62 gives 62⁷ ≈ 3.5 trillion combinations (and 62⁶ ≈ 56.8B is too few), log₆₂(365B) ≈ 6.45 means a 7-character base62 key is the right length.
- Define the API.
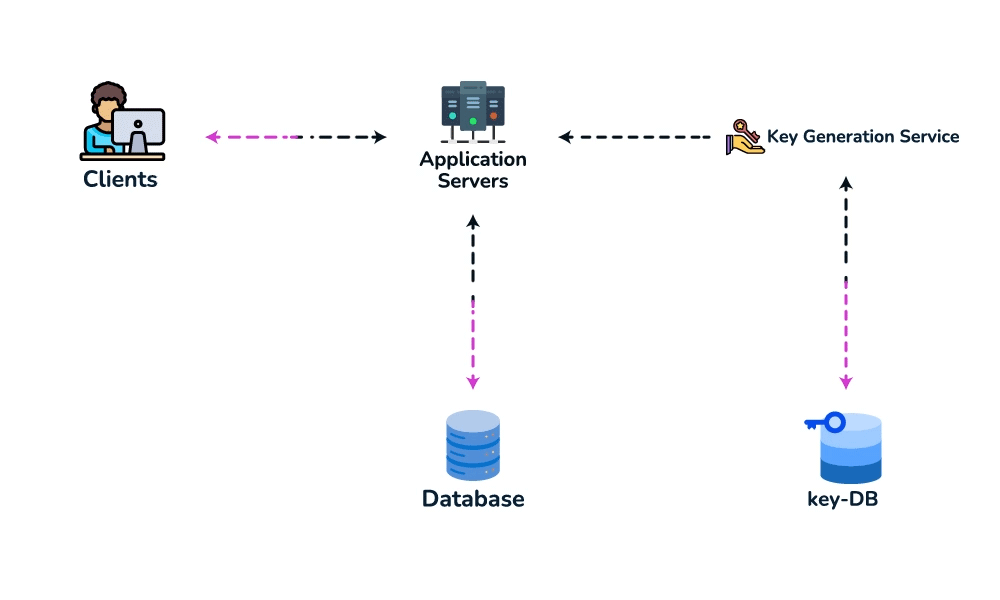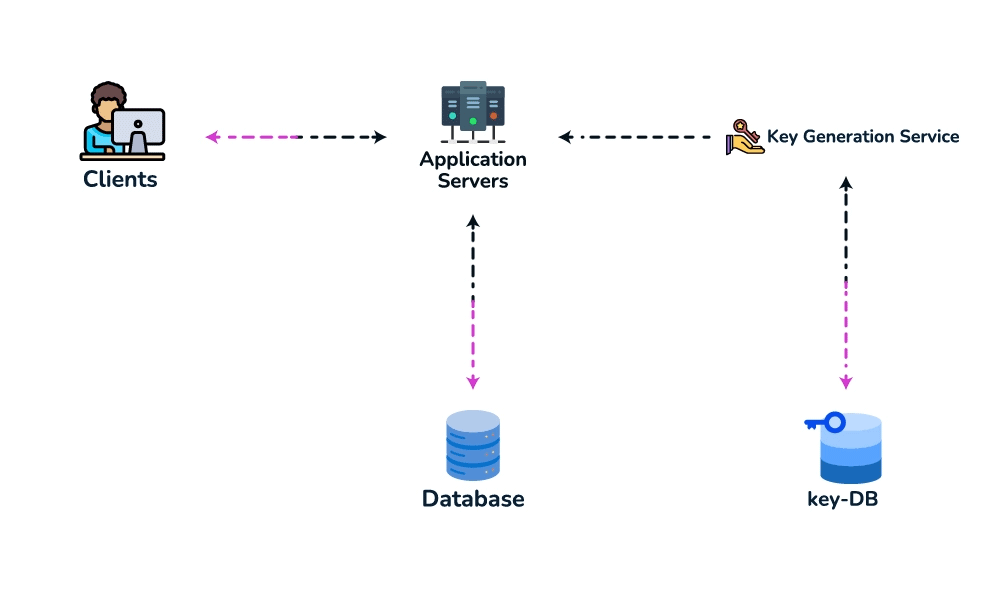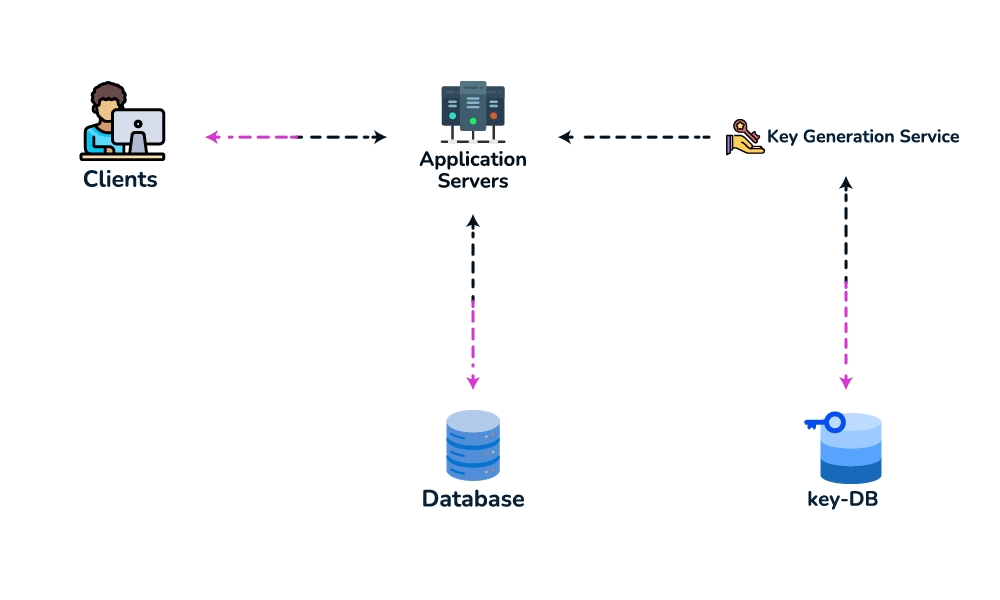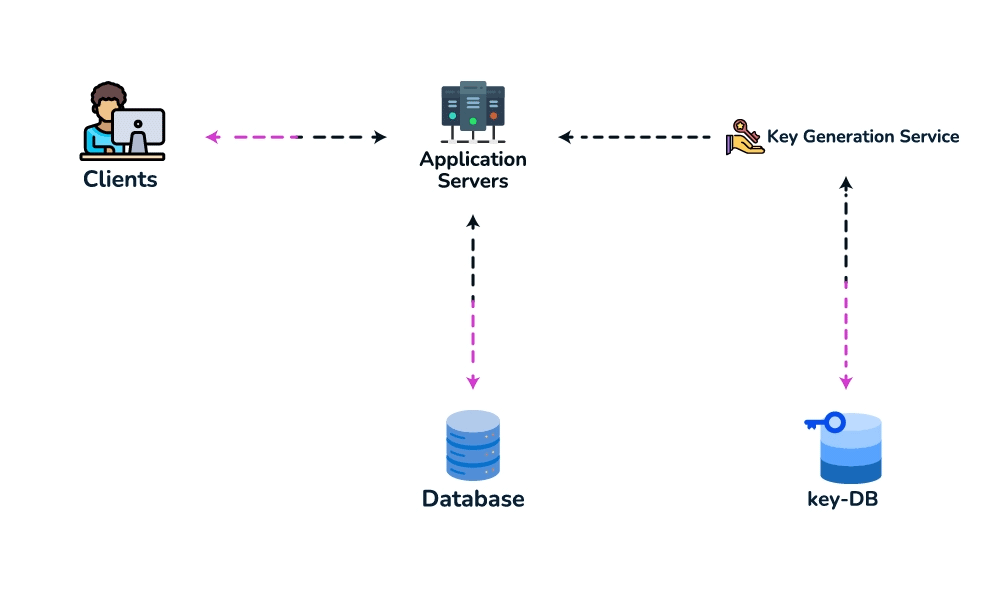
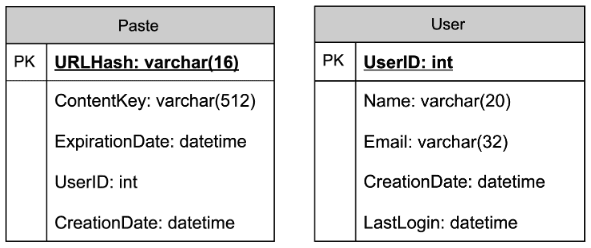
createURL(api_key, long_url, custom_alias?, expiry?) → short_urlandGET /{short_key} → 301/302 redirect. Theapi_keysets up rate-limiting-by-key later. - Data model. Store
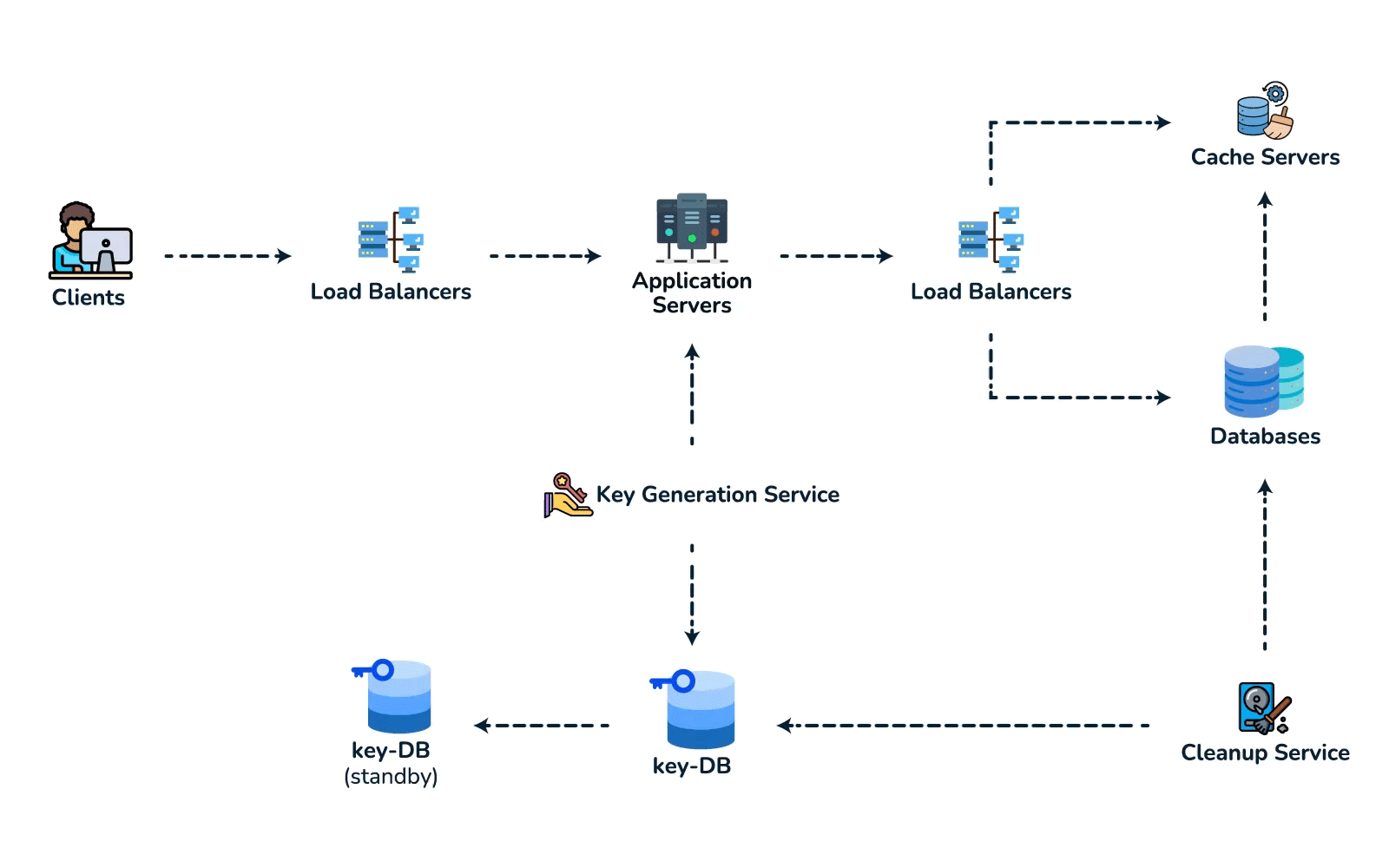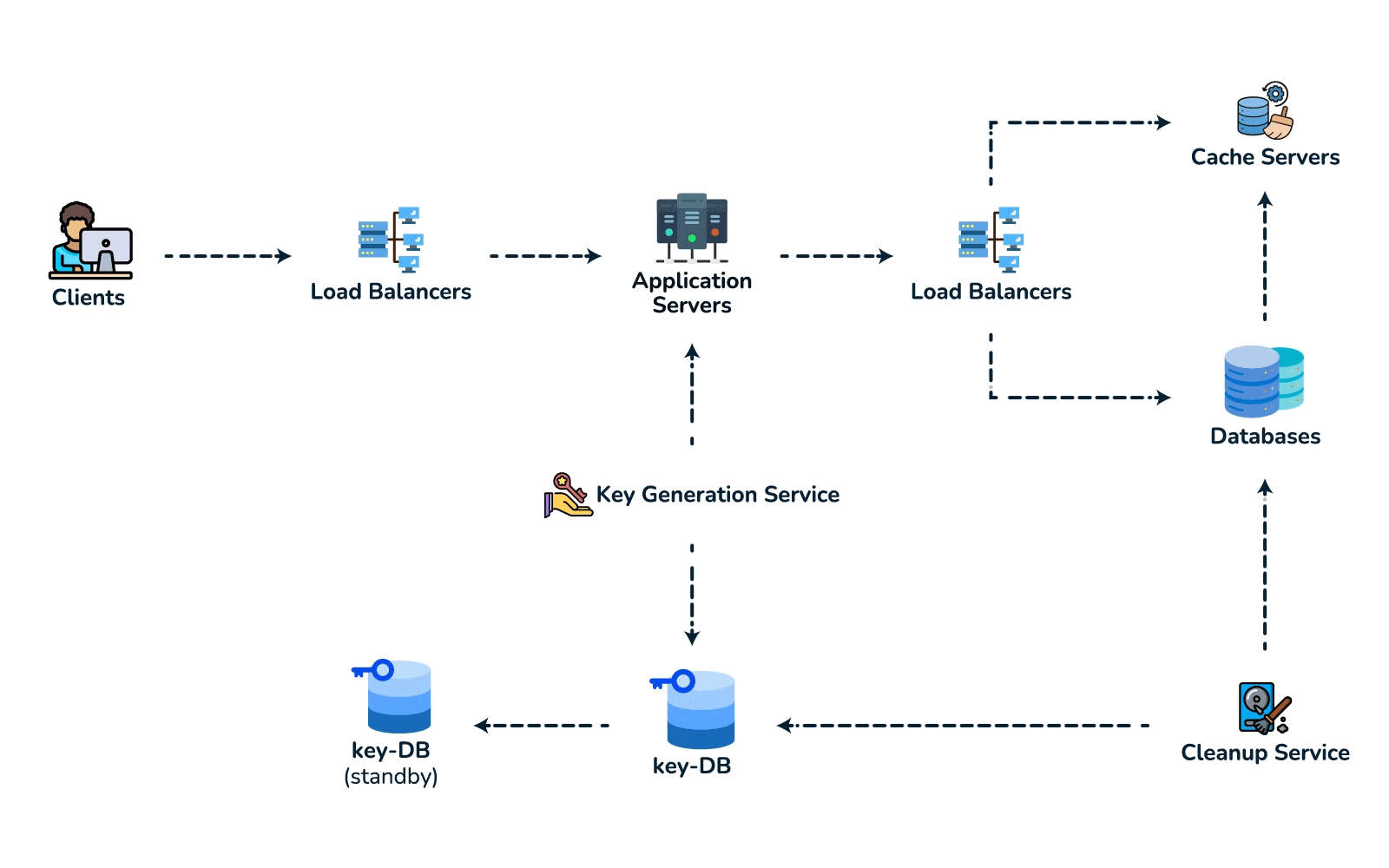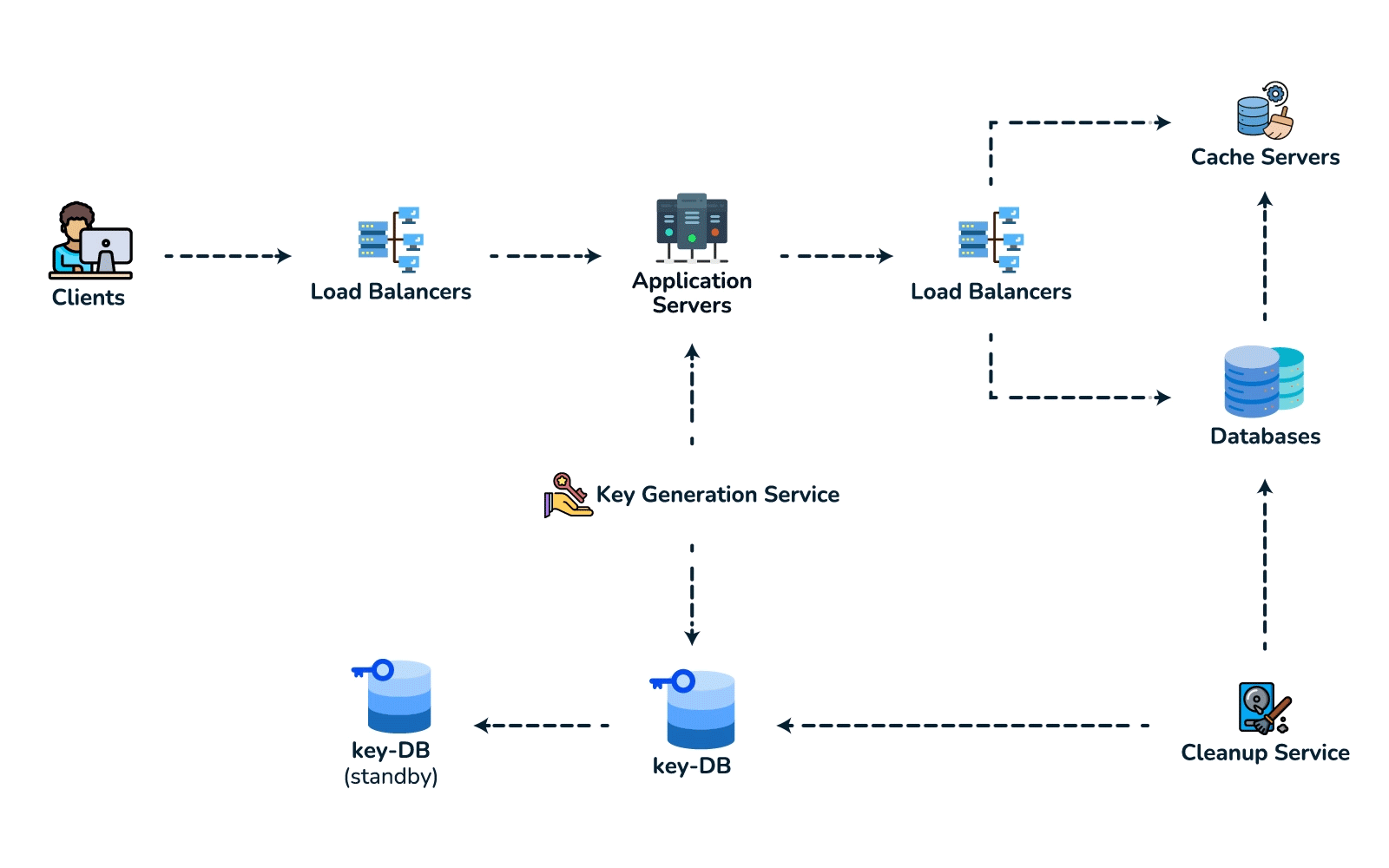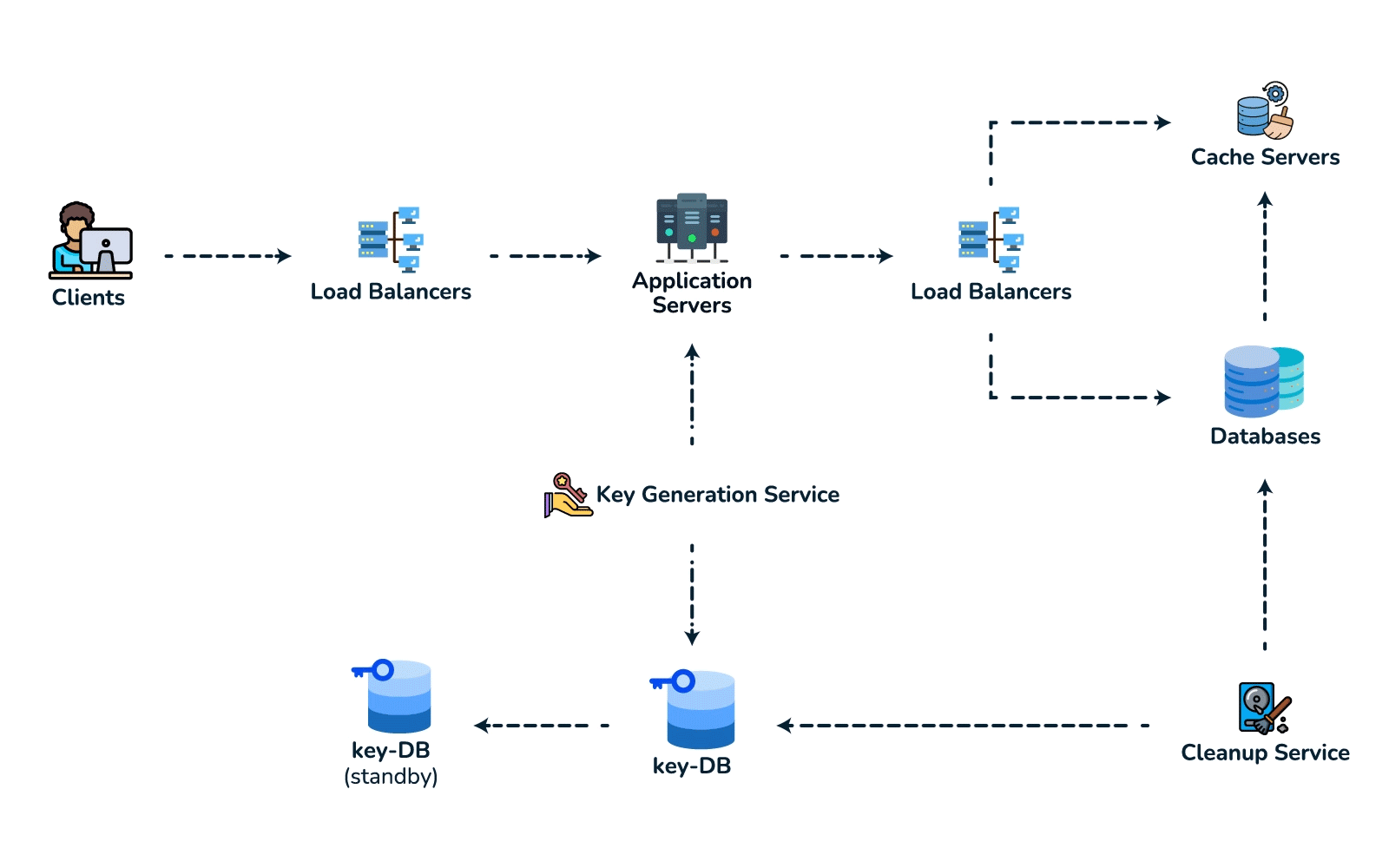
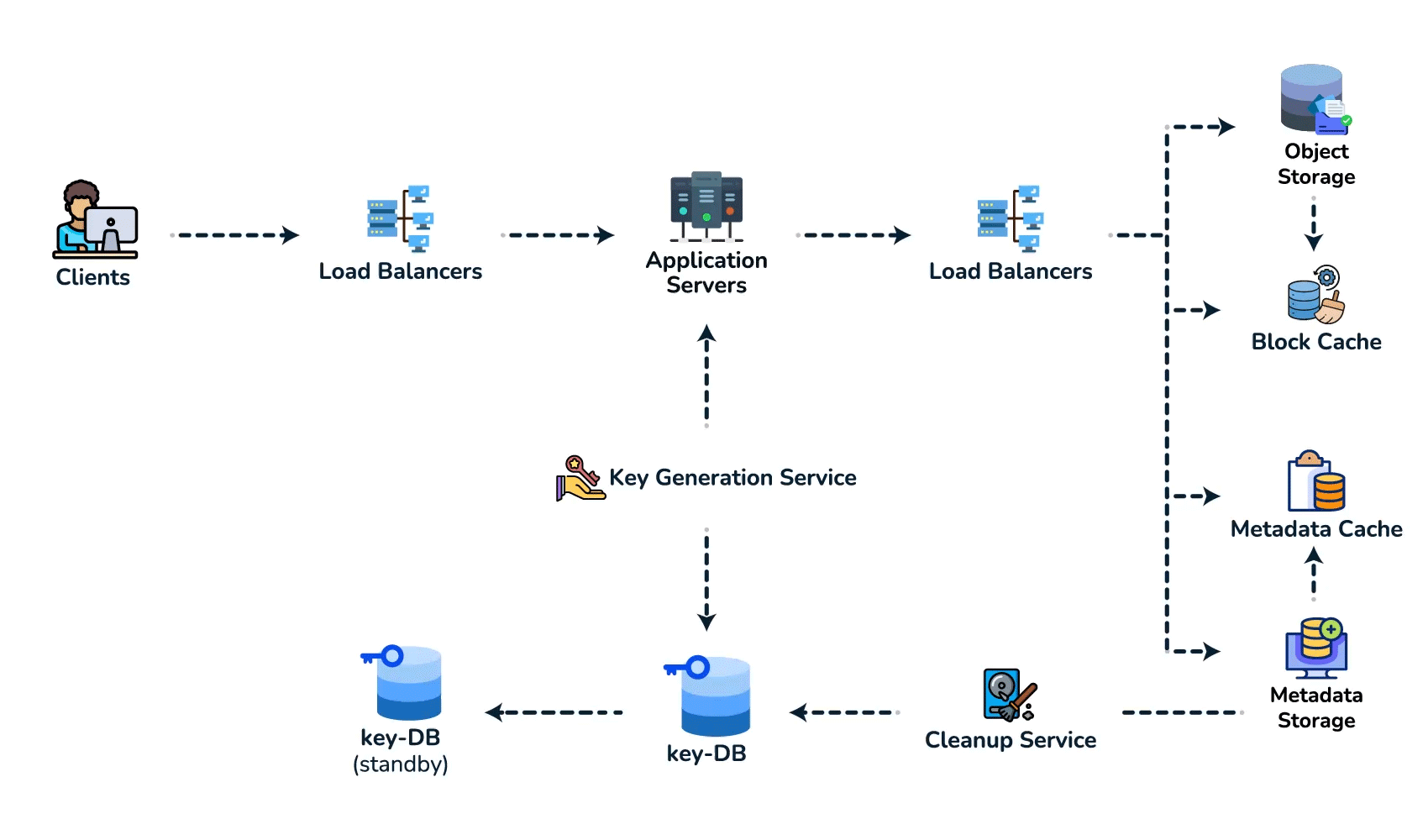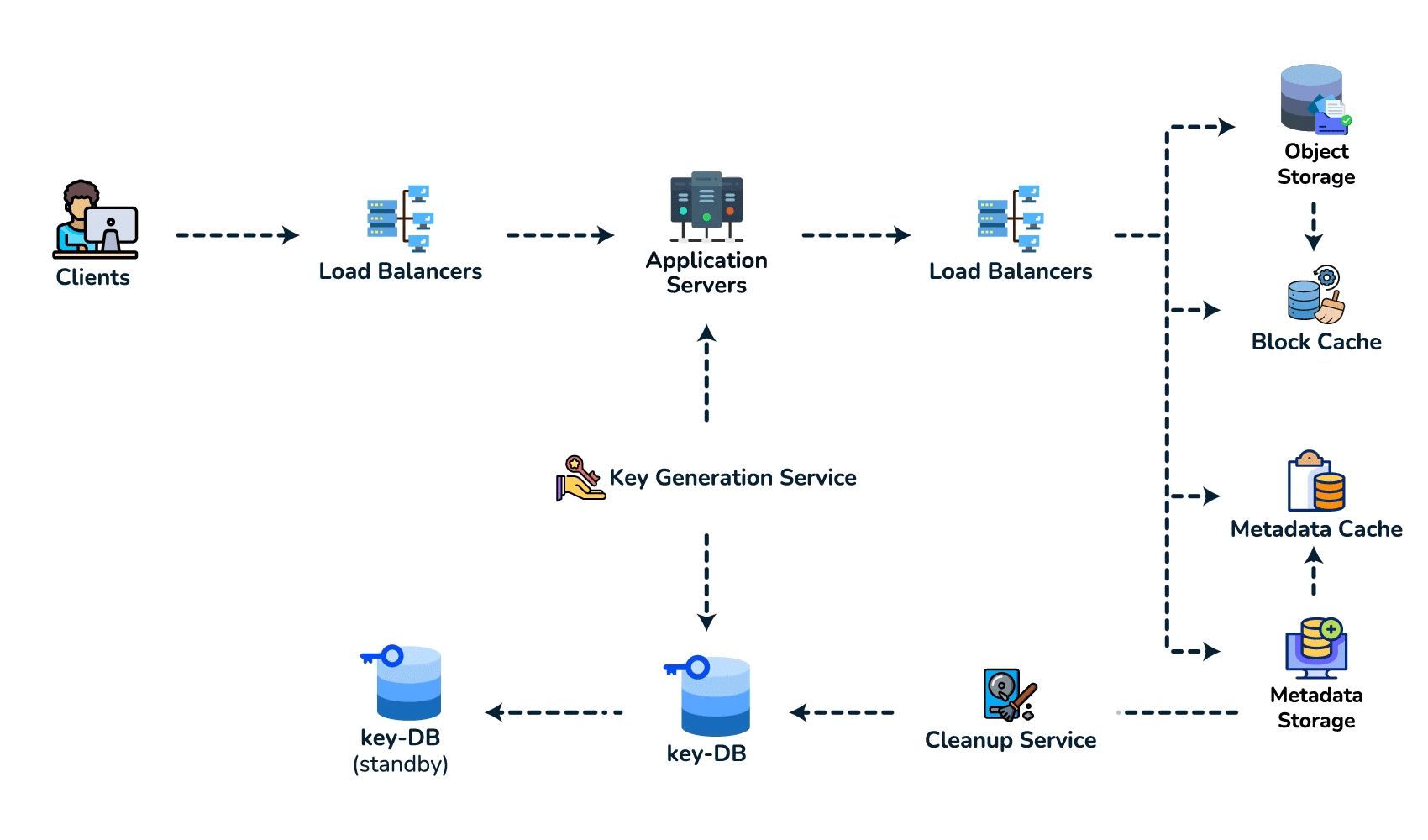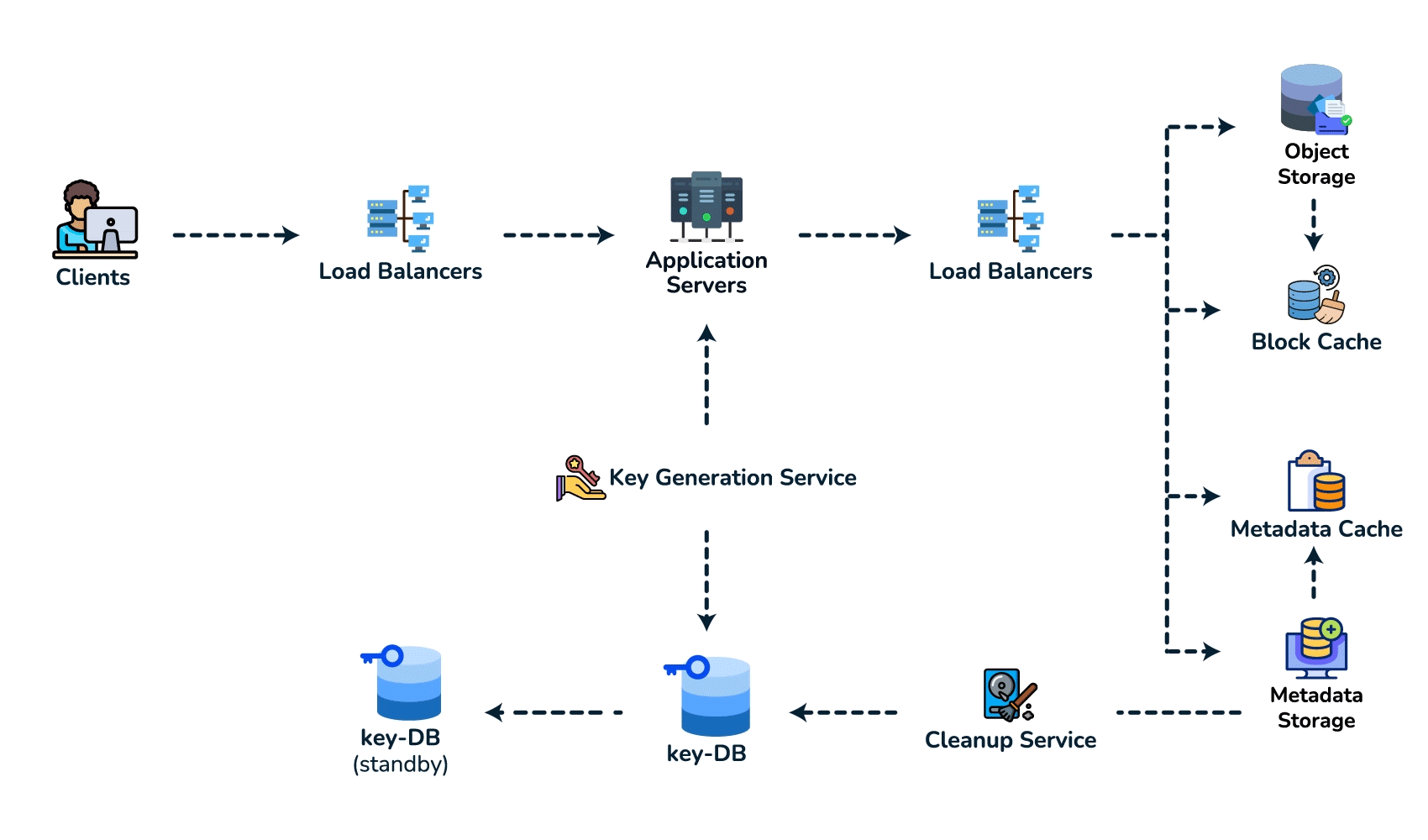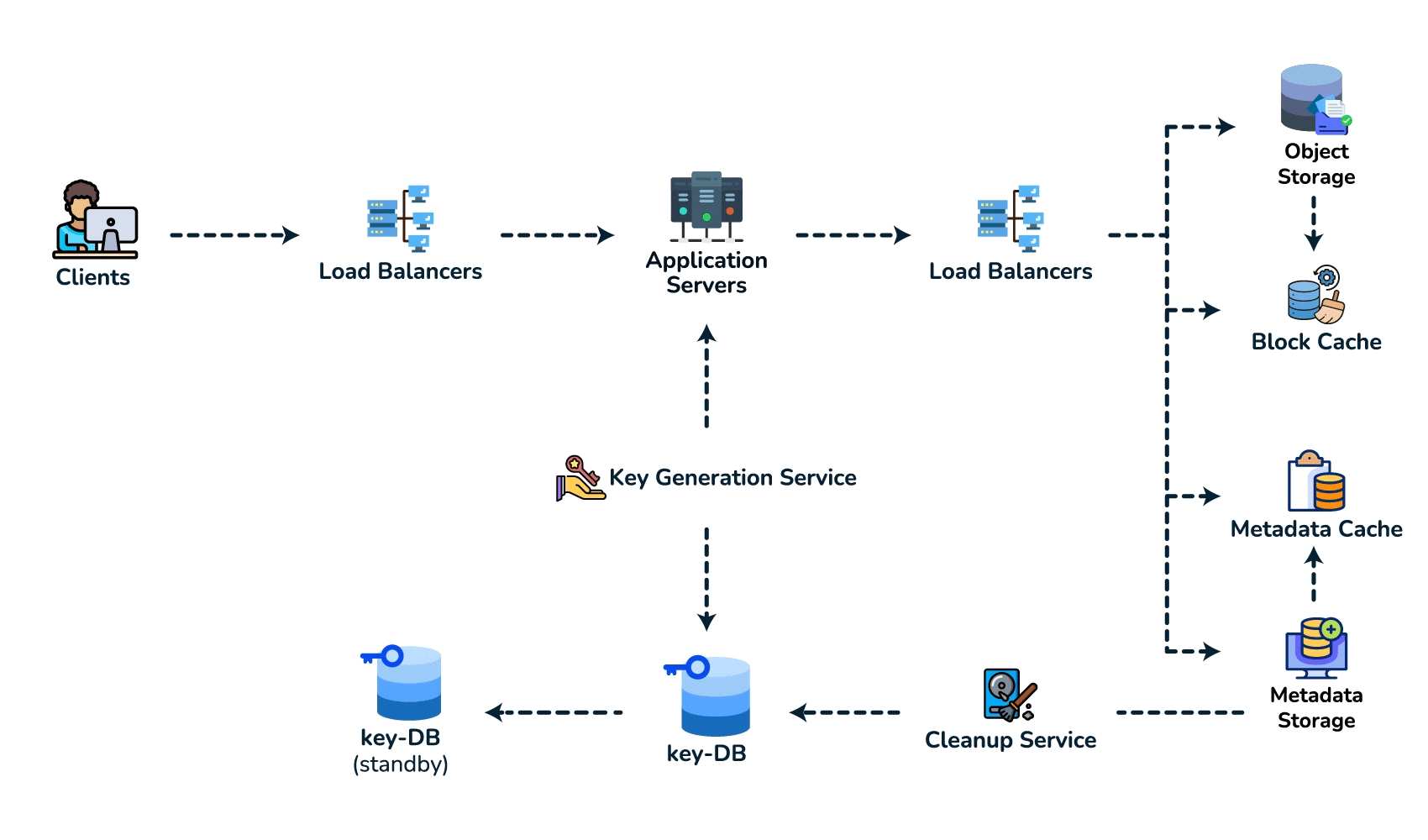
{short_key (PK), long_url, user_id, created_at, expiry}. Access is always a single lookup by key, with no joins, so a key-value / NoSQL store fits (high write throughput, trivial to shard by key). - Spot the core pattern: ID/key generation. The "unique short key, no collisions, at scale" signal points to two clean options. (a) Key-Generation Service (KGS): pre-generate random base62 keys offline into an "available keys" DB and hand them out — no collision check on the hot path; the one concern is concurrency, solved by having the KGS mark keys used atomically and keep two tables (used / unused). (b) Hash + encode: hash the long URL (e.g. MD5) and take 7 base62 chars — but you must handle collisions, so KGS is cleaner. Avoid a simple global auto-increment encoded to base62: it leaks volume and is a single point of contention (a distributed counter via ZooKeeper-assigned ranges is the fallback if pressed).
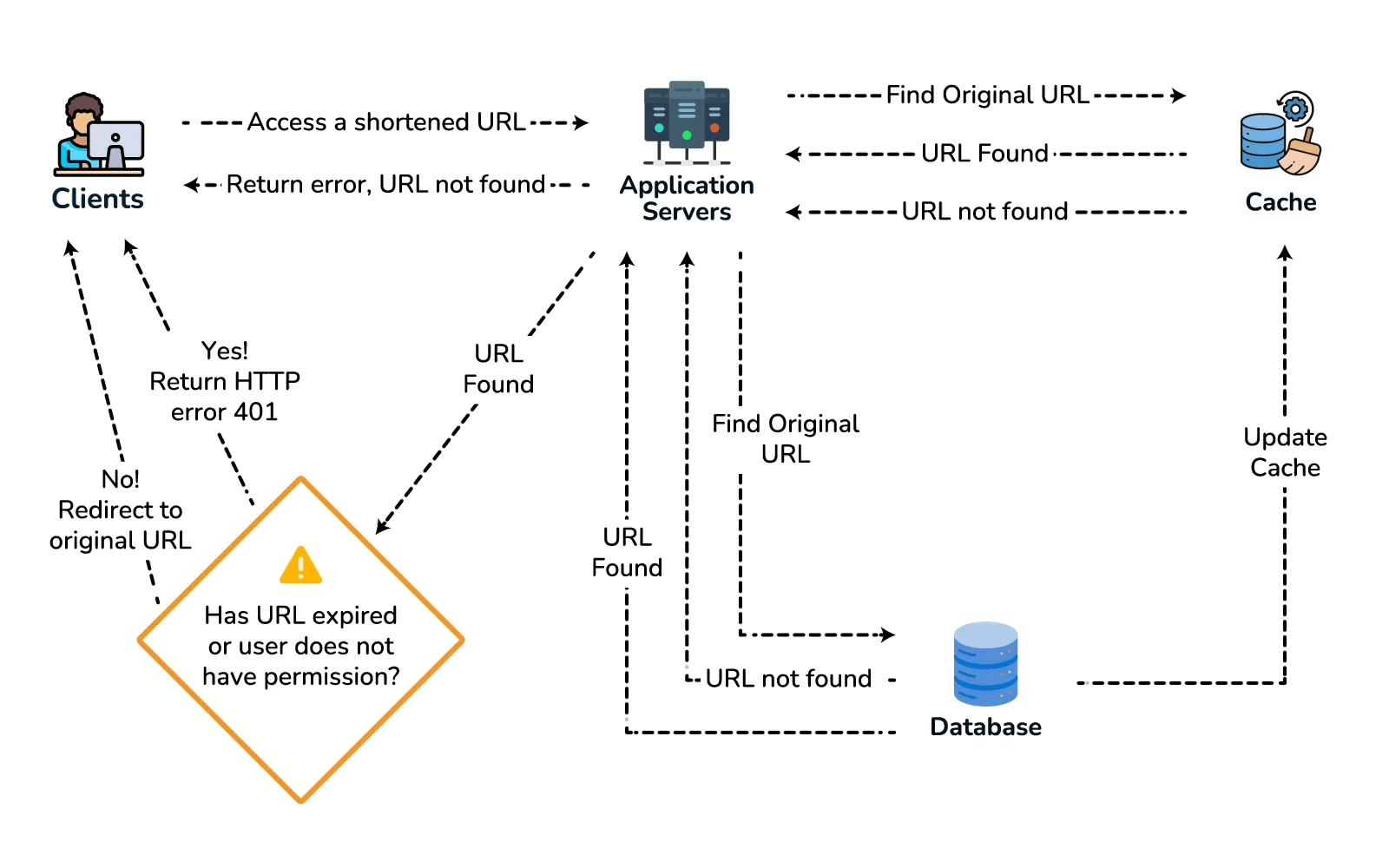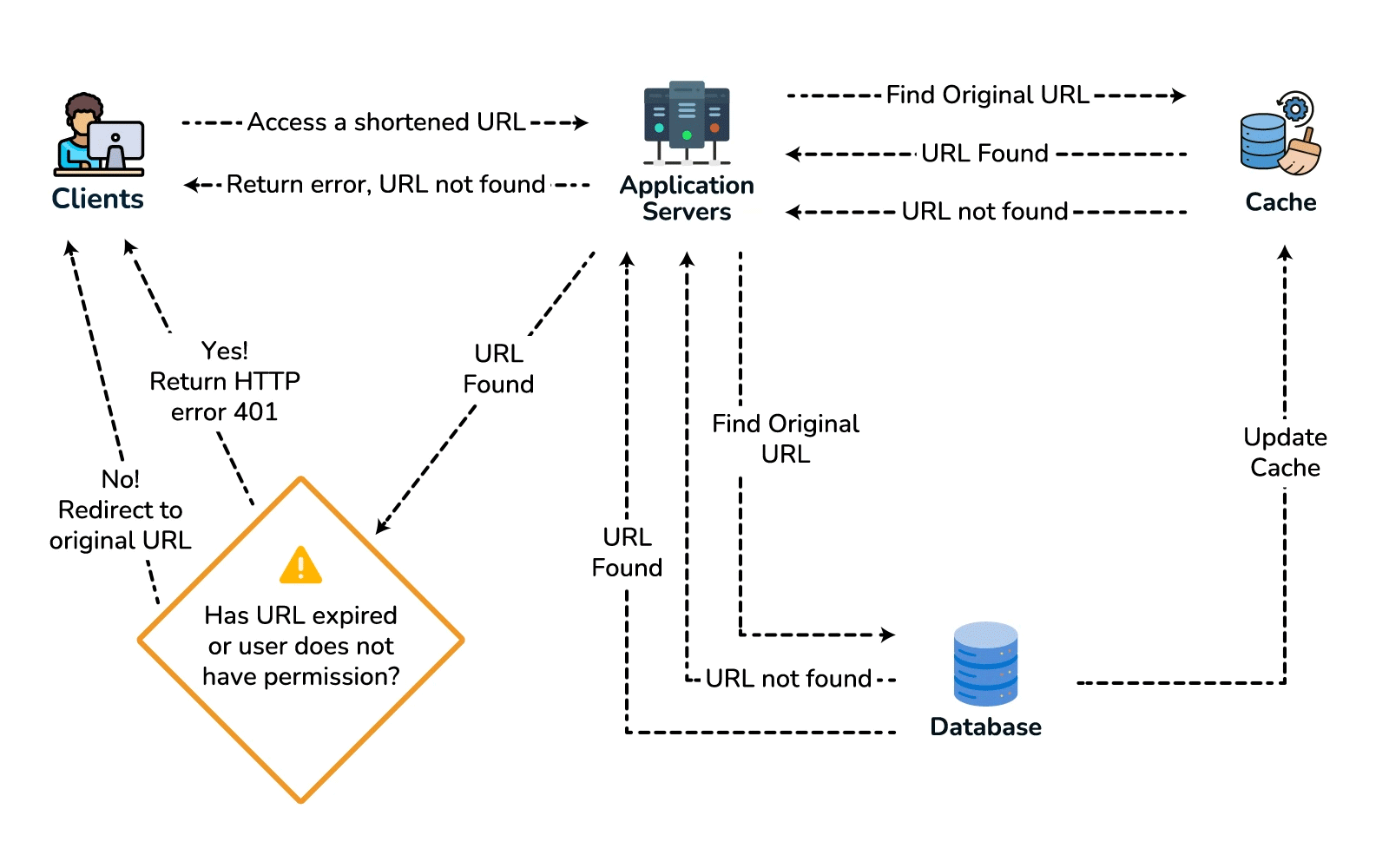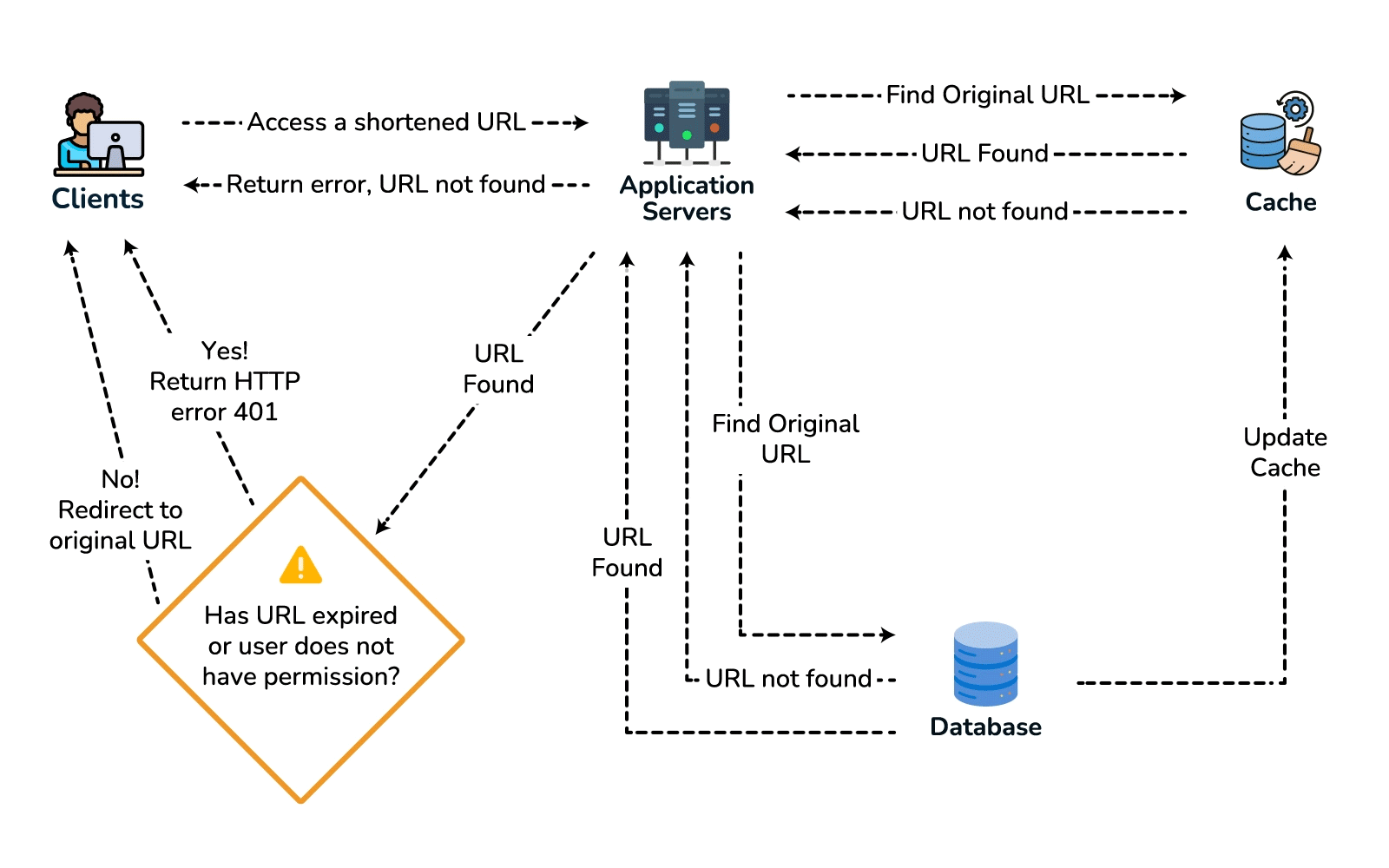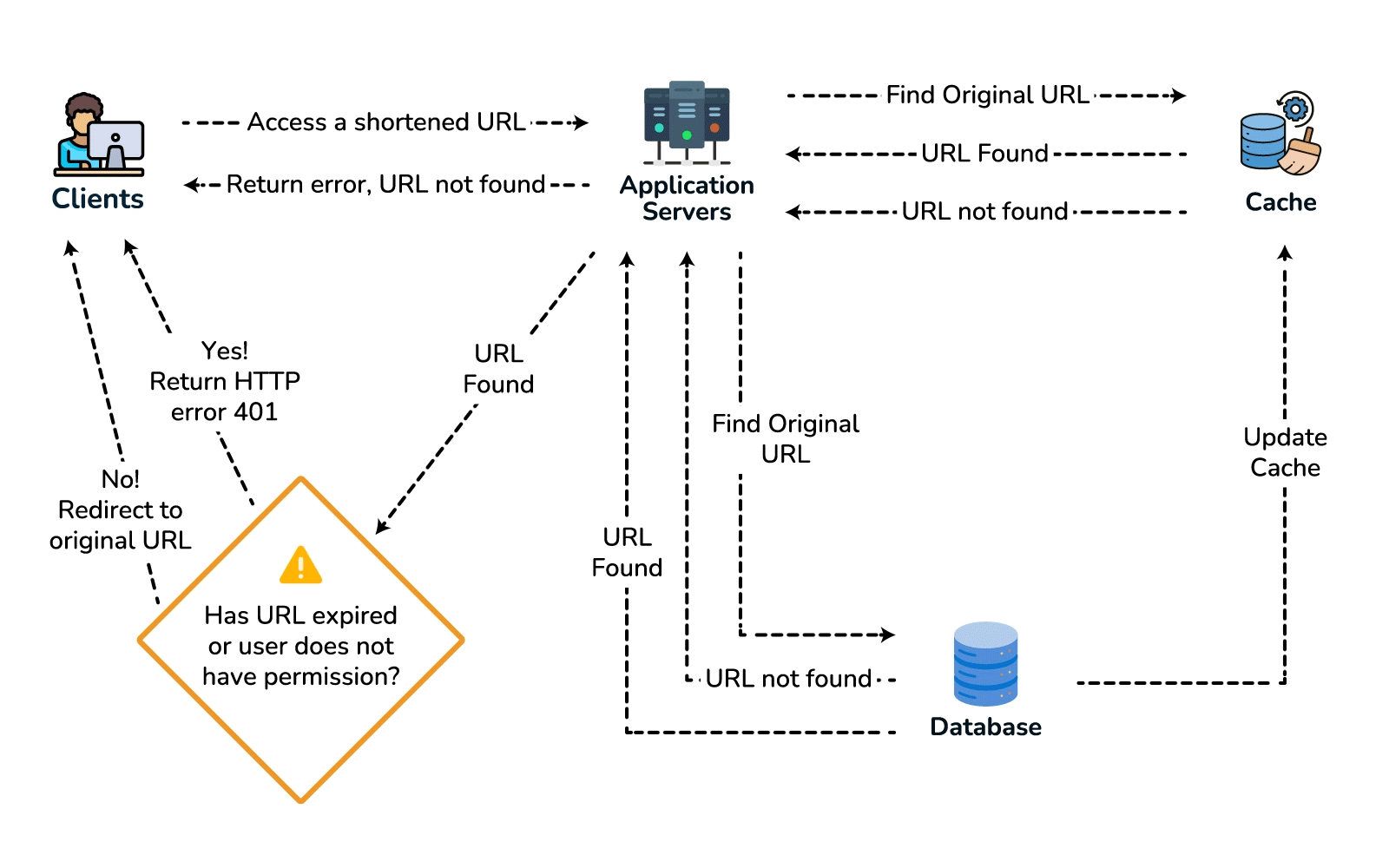
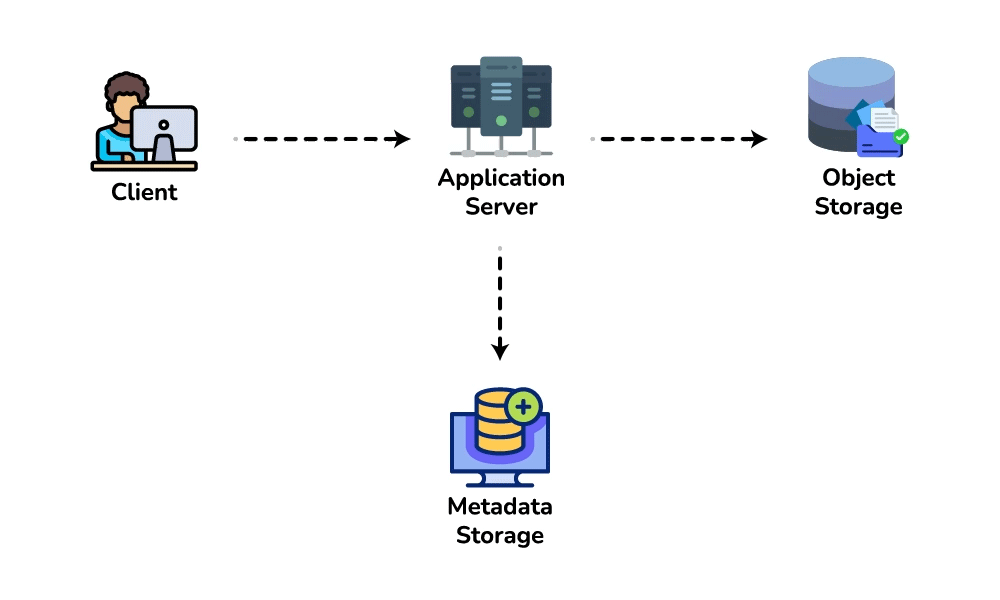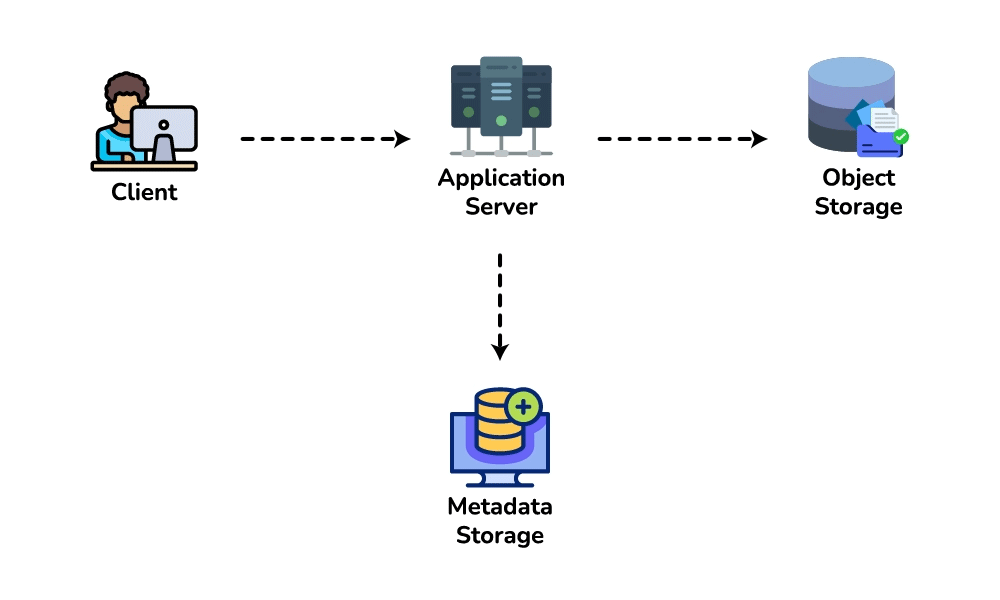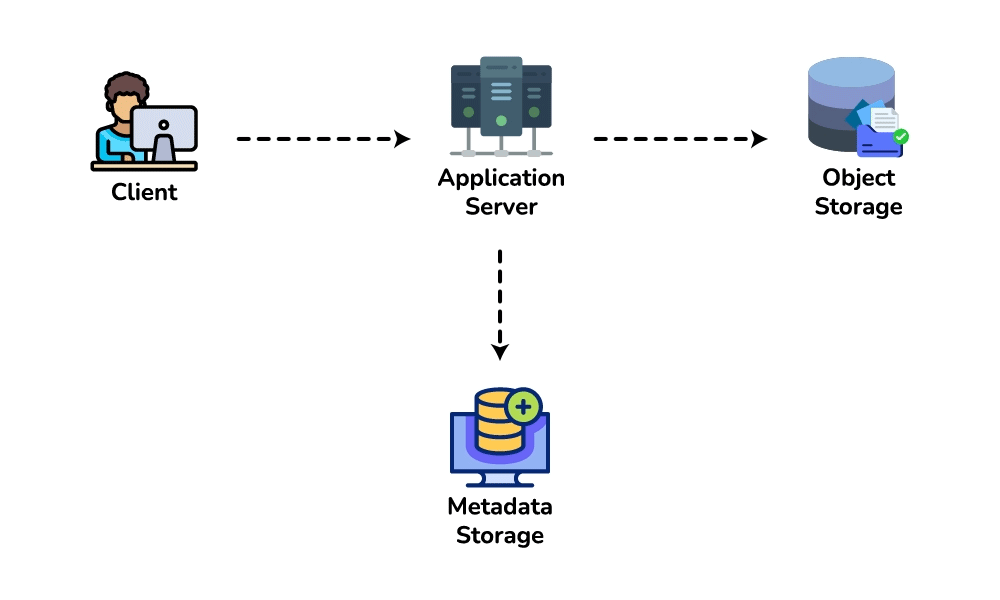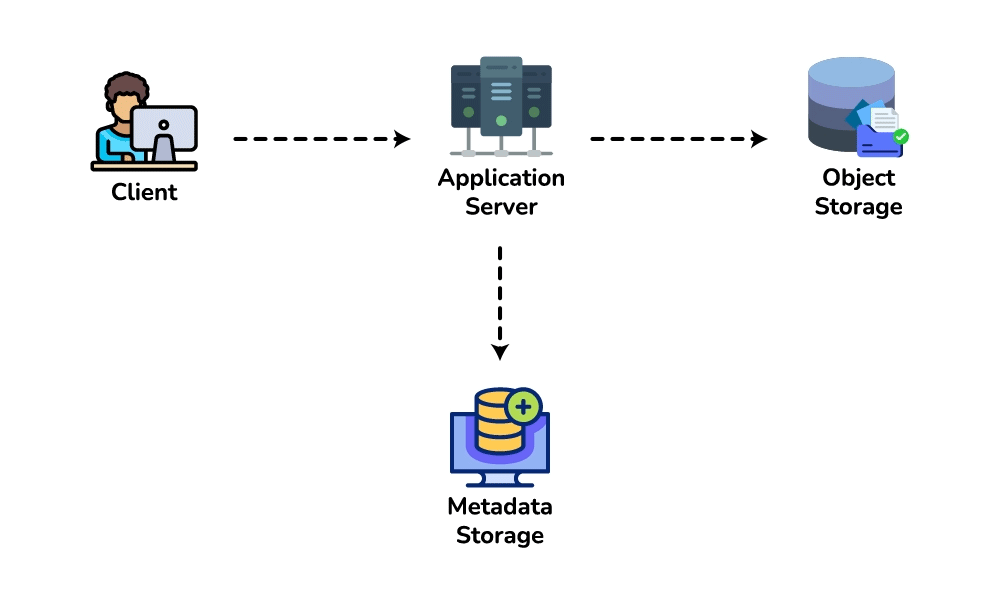
- High-level design. Client → load balancer → stateless app servers → KGS for new keys; persist to the key-value store. Redirect path: app server → cache (Redis, LRU) → DB on miss, return 301/302.
- Deep dive / bottlenecks — reads. Because of the 100:1 ratio, cache hot URLs (the 80/20 rule: ~20% of URLs drive most traffic) and front everything with a CDN / geo-distributed cache for low-latency redirects. Shard the DB by hash of
short_key(consistent hashing) for horizontal scale and add replicas for availability. For cleanup, a lazy/periodic job removes expired keys and returns them to the KGS pool. - Wrap up. Mention 301 (permanent, browser-cacheable, fewer hits) vs 302 (temporary, preserves analytics), rate limiting by api_key/IP to stop abuse, and DB replication/partitioning for availability.
Notice the move: one number (read:write ratio) selected the dominant technique (caching), and one constraint (unique-at-scale) selected the other (KGS). Verbalizing that signal→technique chain is exactly what's being graded.
✨ Added by the guide — work these before the full problem set.