medium Designing Reddit

We are building an online social media platform similar to Reddit, where users can share content and discuss in community forums. In this system, users create posts (which can be text, images, links, or videos) and organize them into topic-based communities called subreddits (or communities). Other users can then engage by voting on posts (upvote or downvote) and adding comments to discuss the content. A real-world example is Reddit itself – often dubbed “the front page of the internet” – which hosts thousands of active communities for different interests. Each post has a score based on user votes, and posts are ranked within their community and on users’ personalized feeds.
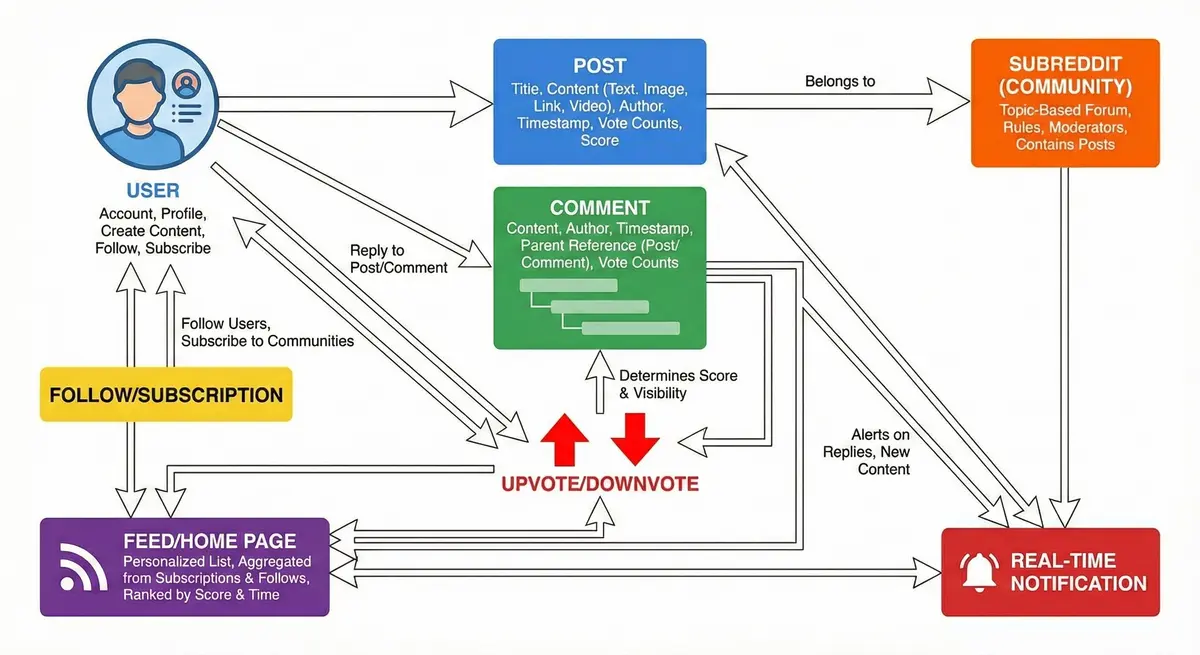
Key Entities/Terms:
- User – An individual with an account. Users have profiles and can create posts or comments, follow other users, and subscribe to subreddits.
- Subreddit (Community) – A forum or category created by users on a specific topic. Each subreddit contains posts related to that topic and has its own moderators and rules.
- Post – A piece of content submitted by a user to a subreddit. Posts can be text, images, videos, or links. Each post has attributes like title, content, author, timestamp, and vote counts.
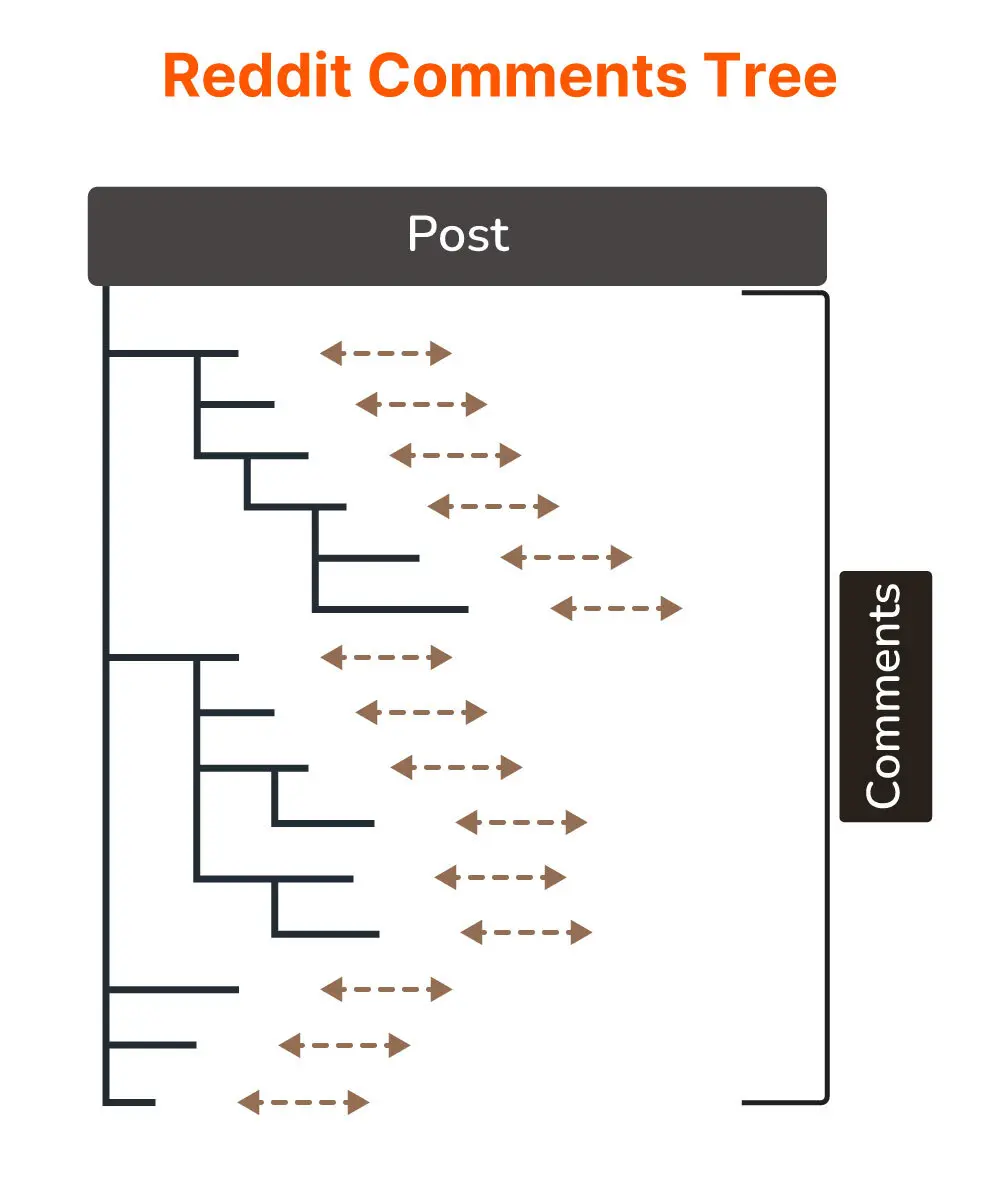
- Comment – A reply or discussion entry on a post. Comments are organized in a nested thread structure (replies to comments form a hierarchy). Each comment stores its content, author, timestamp, and a reference to either the post or a parent comment for threading.
- Upvote/Downvote – A positive or negative vote on a post or comment. Votes collectively determine the score of content and thereby its visibility (higher-scoring posts rank higher in listings). We will use a voting system to rank content (similar to Reddit’s “hot” algorithm combining votes and time).
- Feed/Home Page – A personalized list of posts a user sees. This is typically aggregated from the subreddits they subscribe to or users they follow, possibly with recommended popular posts. The feed updates as new content is posted or existing content gets new votes.
- Follow/Subscription – Users can follow other users or subscribe to subreddits. Following a user means you want to see content they post, and subscribing to a subreddit means posts from that community should appear in your feed.
- Real-time Notification – An alert delivered instantly to the user (in-app or via push) about relevant events (e.g. someone replied to your comment or a followed user posted new content). We plan to support real-time notifications to improve engagement.
Before designing, it’s crucial to pin down what features and constraints our system must satisfy. We identify both functional requirements (features) and non-functional requirements (performance and scale goals).
Functional Requirements (Features):
-
User Accounts & Profiles: Users can register, log in, and manage profiles. Basic profile info and preferences should be stored. Users need to be able to authenticate securely (e.g. via OAuth or email/password).
-
Content Creation: Users can create and share content:
- Posts: Ability to submit new posts containing text, links, images, or videos to a subreddit. Content may include a title and body or media attachments.
- Comments: Ability to comment on posts and reply to other comments (forming threaded discussions).
-
Voting and Ranking: Users can upvote or downvote posts and comments to signal quality. The system tallies votes to compute a score and uses it to rank posts/comments (e.g. for a “hot” feed sorting). Voting should be limited to one vote per user per item (with the ability to change vote). Content ranking algorithms (like Reddit’s mix of vote score and time decay) will determine which posts surface to the top.
-
Subreddits & Communities: Support creation of new subreddit communities and moderation features. Users can create a subreddit (becoming its moderator), and set rules or moderate content (approve/remove posts, although detailed moderation logic can be simplified since no special compliance was noted). Users can subscribe to or leave subreddits to customize their feed.
-
Personalized Feeds: Provide each user with a home feed of posts tailored to their interests. This includes posts from subreddits they subscribed to and content from users they follow. The feed can be sorted by different criteria (e.g. “hot”, “new”, “top”). We should implement voting-based ranking (most upvoted recent posts float up) and possibly time filtering. Also include a content recommendation engine to suggest popular or relevant posts/communities beyond a user’s subscriptions.
-
User Following: In addition to communities, users can follow other individual users. If I follow User X, I should see posts from User X in my feed (similar to following on Twitter). This requires maintaining follower relationships and treating a user’s posts somewhat like a personal subreddit for their followers.
-
Notifications: Real-time notifications for user interactions. For example, if someone replies to my comment, mentions me, if a followed user posts, or if my post gets upvotes, I should get an in-app notification (and possibly an email or push notification). Live updates should be supported – e.g. a notification bell icon updates instantly via WebSocket when a new event occurs.
-
Messaging: Ability for users to send direct messages to each other. This could be a simple inbox system or real-time chat. We will assume a basic messaging feature with real-time delivery (likely via WebSockets for instant chat).
-
Search and Discovery: Users should be able to search for subreddits or posts by keywords. Additionally, the system should surface trending subreddits or posts (e.g. a “popular” or “trending” feed). Content recommendation features (suggesting new communities or posts a user might like) are expected as well.
-
API for Clients: Since we expect to support web and mobile clients, the system should expose a well-defined API (e.g. RESTful JSON API) for all functionalities. Clients (web app, iOS, Android) will use this API to fetch feeds, submit content, etc. The API should be stateless and handle authentication (likely via tokens) so that multiple client types can interact uniformly.
Non-Functional Requirements (Scale and Performance):
- Scalability: The system must handle web-scale traffic, meaning potentially millions of users and a huge volume of content. We anticipate growth, so the design should scale horizontally (add more servers) without major rework. Both the user load (number of concurrent users) and data volume (posts, comments stored) should be scalable. For example, we may design for millions of daily active users in the future even if we start smaller.
- High Availability: The platform should have minimal downtime. Target a high uptime (e.g. 99.9% or above). Even under failures, the system should remain mostly available (using redundancies and failovers). Outages or data loss would severely hurt a social platform, so reliability is key.
- Low Latency & Performance: Fast content delivery is essential. Users should experience quick page loads and interactions – e.g. viewing their feed, posting a comment, or voting should happen in milliseconds to a few hundred milliseconds at most. The system should handle a high volume of read requests with low latency. Because reading (browsing feeds and comments) will far outweigh writing (posting) in this platform, our design must optimize for read-heavy workload. We might aim for P99 latency of, say, < 100ms for feed generation and sub-second load times for content, even under heavy load.
- Consistency and Integrity: We should ensure data integrity (no lost or corrupt data). Certain operations (like registering an account or posting a comment) should be strongly consistent (once confirmed, it should be reliably stored). However, to scale better, some aspects can be eventually consistent – for instance, vote counts or feed listings might update asynchronously and may briefly lag in reflecting the latest state. This trade-off can improve performance while maintaining an acceptable user experience.
- Storage Efficiency: Efficiently store and retrieve a massive amount of user-generated content. Over time, we could accumulate billions of posts and comments, so our storage layer and data model should handle large volumes (partitioning data and using appropriate database solutions). We also need to store media (images/videos) efficiently, likely separate from textual data.
These requirements define our target: a feature-rich platform that feels real-time and reliable to users, and can scale to large communities with heavy read traffic. Next, we estimate scale to guide our design choices.
Step 2. Back-of-the-Envelope Capacity Estimation
To design for scale, let's estimate the expected workload and data volumes:
Summary
- Scale: 500 million monthly users (MAU), 10 million daily users (DAU) → hundreds of thousands online at once.
- Read/write ratio: 95% reads operations (browsing), 5 % writes operations (posting, commenting, voting).
- Posts per day: ~1 million new posts and ~10 million new comments per day → sustained high write throughput.
- Comments per day: ~10 million new comments → very high read/write demand
- Votes per day: ~1 billion vote actions per day → extremely high-frequency counter updates, requiring efficient write paths.
- Read traffic: Billions of feed and comment views per day → demands aggressive caching and efficient data access patterns.
Details
- User Base: ~500 million monthly active users (MAU), with around 10 million daily active users (DAU) at peak. This implies many concurrent users at any given time (possibly hundreds of thousands).
- Traffic Pattern: The system is read-heavy. Approximately 95% of operations are read requests (browsing posts and comments), and 5% are writes (creating content or votes). This is typical for social media platforms where far more users consume content than create it.
- Posts: We anticipate about 1 million new posts per day being created across all subreddits. This leads to high write throughput for creating posts.
- Comments: Approximately 10 million new comments are added daily, as each post can have multiple comments. Comments are even more frequent than posts, so the comment system must handle very high write volume and also heavy reads (as users load comment threads).
- Votes (Upvotes/Downvotes): On the order of 1 billion vote actions per day (since each active user might cast multiple votes). Voting is an extremely write-intensive operation (frequent small updates to counters). This requires a highly efficient mechanism due to the sheer volume of events.
- Content Delivery: Many billions of read requests per day when counting all post feed views, comment page loads, etc. We must use caching and efficient querying to handle this scale.
- Storage needs: If an average post or comment is a few hundred bytes, the total storage for text content (posts + comments) is in the tens to low hundreds of GBs, which is manageable but should be distributed across multiple storage locations. Media (images/videos) will be stored in a separate blob storage (e.g., cloud storage such as Amazon's S3).
These estimates guide the design decisions (for example, the heavy read ratio suggests aggressive caching and replication, while the high write counts for votes suggest specialized handling). The system should also be designed to scale beyond these numbers, as a Reddit-like platform could continue to grow.
3. API Specifications
Here are the core internal APIs for a Reddit-like web-scale service. These internal APIs are not exposed publicly and are typically protected via network-level controls or service identity (rather than full user authentication).
1. Fetch Home Feed (GET /feed)
Description: Retrieves a personalized home feed for the authenticated user. The feed service aggregates posts from subreddits the user follows and recommended posts, sorted according to a specified ranking algorithm (e.g., hot, new, top). Supports pagination for infinite scroll. This is typically called when a user opens their home page feed.
Endpoint: GET /feed
Method: GET
Request Parameters:
- Query Parameters:
limit– (optional, integer) Number of posts to return per request (e.g., 10, 25). Defaults to 25 if not specified.sort– (optional, string) Sorting algorithm for the feed. Allowed values include"hot","new","top","best", etc. Defaults to"hot"if not provided.after– (optional, string) A cursor or ID of the last post from the previous page. When provided, the next set of results will start after this item (for pagination).
- Headers:
Authorization– (required, string) Authentication token or internal service credential identifying the user. If missing or invalid, the request is rejected as unauthorized.
Sample Request:
GET /feed?sort=hot&limit=20&after=t3_xy123 HTTP/1.1 Host: api.internal.redditclone.com Authorization: Bearer <USER_JWT_TOKEN>
In this example, the client requests 20 posts from the home feed, sorted by the "hot" algorithm, starting after post ID t3_xy123 (as a pagination cursor).
Response Format:
-
Success (200 OK): A JSON object containing an array of posts and pagination info.
{ "posts": [ { "id": "t3_xy124", "title": "Interesting Post Title", "subreddit": "exampleSub", "author": "user_123", "score": 532, "num_comments": 45, "created_at": "2025-02-09T12:34:56Z", "content_type": "link", "url": "https://example.com/some-article", "thumbnail": "https://example.com/thumb.jpg" }, { "id": "t3_xy125", "title": "Another Post", "subreddit": "funny", "author": "user_456", "score": 1200, "num_comments": 88, "created_at": "2025-02-09T12:40:00Z", "content_type": "text", "text_preview": "This is a text post preview...", "thumbnail": null } // ... up to 20 posts ], "next_page": "t3_xy145" }posts– Array of post objects. Each post includes fields likeid,title, thesubredditname,authorusername,score(net upvotes),num_comments,created_attimestamp, and content-specific fields. For example,content_typeindicates if it's a text, link, or media post; a link post provides aurland maybe athumbnail, while a text post might include atext_previewor excerpt.next_page– A cursor (e.g., the last post ID in this page) to be used as theafterparameter for fetching the next page. Ifnext_pageisnullor absent, it means there are no further posts at the moment.
-
Error (401 Unauthorized): If authentication is missing or invalid.
{ "error": "Unauthorized", "message": "Authentication token is missing or invalid." }The service returns a 401 status with an error message when the user context is not provided or the token has expired.
-
Error (400 Bad Request): If query parameters are invalid (e.g., an unsupported
sortvalue).{ "error": "Bad Request", "message": "Invalid 'sort' parameter. Must be one of 'hot', 'new', 'top', 'best'." }This indicates the client supplied a parameter that the service cannot process. The feed service will not return a feed and will instead provide an explanation for the mistake.
Expected Behavior & Use Case: The Feed service uses this endpoint to serve the home timeline for users. On success, it returns a personalized list of posts that the user is allowed to see (e.g., from subreddits they subscribe to or general recommendations). The results are ordered by the specified sorting algorithm (defaulting to Reddit’s “hot” ranking if none is specified). Pagination ensures the client can fetch additional posts by providing the after cursor from the previous response. This design allows the home feed to be dynamically generated and continuously fetched as the user scrolls, while maintaining performance at web scale (via cursor-based pagination and internal caching of personalized feeds).
2. Create a Post (POST /posts)
Description: Allows an authenticated user to create a new post in a specific subreddit. The post can be a text post, a link, or a media post (image or video). The service will validate the input (e.g., presence of required fields, title length, and content type consistency) before creating the post. This endpoint is used when a user submits a new post through the app or website.
3. Fetch Comments on a Post (GET /posts/{post_id}/comments)
Description: Retrieves all comments for a given post, returned in a threaded (nested) format. Supports pagination for posts with large numbers of comments and allows sorting by different criteria (e.g., new, top, old). Used when a user views a post and its comment thread.
4. Vote on a Post or Comment (POST /votes)
Description: Records an upvote or downvote from a user on a given post or comment. This is an idempotent action that sets the user’s vote to a specific value (upvote, downvote, or neutral) on the target item. A user can only vote once per item – repeated votes will update the previous vote. Used when a user clicks the upvote/downvote buttons.
5. Send a Direct Message (POST /messages)
Description: Sends a private direct message from the authenticated user to another user. The message is stored persistently (in the messaging service’s database) and triggers a notification for the recipient. This is used when a user composes a new message or replies to an existing conversation in their inbox.
6. Fetch Notifications (GET /notifications)
Description: Retrieves a list of notifications for the authenticated user, with a focus on unread notifications. Notifications can include things like someone mentioning the user, replying to their post or comment, receiving a direct message, or other alerts. The endpoint supports pagination for when there are many notifications, and can optionally mark notifications as read once retrieved.
7. Search Posts and Comments (GET /search)
Description: Provides a search across posts and comments in the Reddit-like system based on a query. Supports filtering by subreddit, author, and time, as well as specifying whether to search posts, comments, or both. This is used when a user enters keywords in the search bar to find relevant content.
Step 5: High-Level System Design
At a high level, we’ll design the platform as a set of distributed services and components that handle different responsibilities. The system will be structured to handle two primary flows: content submission (writes) and content consumption (reads). We will use a modular, microservices-oriented architecture to allow each piece to scale independently and to isolate complexity.
Key Points
- Client Applications: Web browsers and mobile apps call HTTP(S) APIs via a single endpoint (API gateway/load balancer) and receive JSON or HTML. Static assets are served over a content delivery network (CDN).
- CDN Layer: Caches images, videos, scripts, and pages for anonymous users at edge locations to reduce latency and load on the origin servers.
- API Gateway / Load Balancer: Authenticates tokens/cookies, enforces rate limits, routes requests to service clusters, performs health checks, and balances load across stateless gateway instances.
- Microservices Architecture: Separate services for each domain:
- User Service for auth and profiles; Post Service for creating/fetching posts; Comment Service for nested replies; Vote Service for up/down votes; Subreddit Service for communities; Feed Service for personalized timelines; Media Service for uploads via object storage; Search Service backed by Elasticsearch; Messaging Service for DMs; Notification Service for alerts; Moderation Service for content control.
- Polyglot Data Storage: NoSQL (Cassandra/DynamoDB) for high-volume posts and comments (eventual consistency, horizontal scale); SQL (Postgres/MySQL) for user accounts and subreddit metadata (strong consistency, ACID); Object Storage (e.g., S3) for media; Search Index (Elasticsearch) for full-text queries; Data Warehouse for offline analytics.
- Caching Layer: Redis/Memcached for hot data (feeds, profiles, counts) with TTL and invalidation; CDN for static assets and public pages, reducing backend and bandwidth load.
- Message Queue & Streaming: Kafka topics carry events like “PostCreated” or “UserUpvoted”; consumers handle search indexing, feed updates, notifications, and spam detection asynchronously.
- Typical Request Workflow: When a user opens their feed, the client calls
/feedAPI; the API gateway authenticates the request and forwards it to the Feed Service, which fetches data from a cache (or the Post Service) and returns JSON. For voting actions, the client calls the Vote Service, which records the vote and asynchronously publishes events (e.g., to update scores, trigger notifications, or run spam checks), ensuring the UI stays responsive.

Details
Below are details of the major components and how they interact:
-
Client Applications: Users access the service via a web browser or mobile app. The client talks to our backend through HTTP(S) APIs. We’ll serve both a web UI and a JSON API (for mobile apps). All client requests are routed to the backend through a common interface (which could be an API gateway or load balancer URL). Clients will also receive real-time updates for notifications, possibly via long-polling (though the absence of a live chat requirement simplifies this process). Static assets (images, scripts, etc.) are loaded via a content delivery network (CDN).
-
CDN Layer: We use a Content Delivery Network (CDN) as the first layer for requests. The CDN (e.g., Fastly or Cloudflare) caches static content and serves it from edge locations globally. It can also handle some routing logic at the edge. For instance, Reddit uses Fastly to route requests based on domain/path before hitting the origin. In our case, the CDN will serve cached pages for non-logged-in users (such as the public front page or trending page) and all images/videos. This reduces latency for users and offloads work from our servers.
-
API Gateway / Load Balancer: At the core entry point in the backend, we use an API Gateway or a set of load balancers. This could be an Nginx or HAProxy layer, or a cloud LB, that accepts incoming HTTP requests from clients and distributes them to the internal services. The API gateway can handle standard functionalities, including authentication (verifying user tokens or session cookies), request routing to the appropriate service, and rate limiting. It provides a unified endpoint (e.g., api.reddit.com) and then forwards requests to microservices. Alternatively, we could have separate subdomains for certain services (like search) if needed, but generally a single API entry point is simpler for clients. This gateway layer should be stateless and highly available (multiple instances). It ensures no single backend server is overloaded, balancing traffic across many app server instances. It also performs health checks and can stop routing to failed nodes.

- Application Servers / Microservices: The backend logic is divided into multiple services that each handle a specific domain: for example, User Service, Post Service, Comment Service, Feed Service, Search Service, Messaging Service, Notification Service, etc. These could be separate microservices running (for scalability and separation of concerns), or some could be grouped if using a modular monolith approach. Given the scale, we’ll assume distinct services so they can scale independently. Each service will run multiple instances across many servers (forming a cluster) to handle the load. A request coming from the API gateway will be routed to the appropriate service cluster. For example:
-
User Service (Authentication & Profiles) - Manages user accounts, profiles, and authentication. It handles user registration, login, password hashing, and OAuth integration. Profile data (username, avatar, bio, karma points) is stored and served by this service. For security, this service interacts with a secure user database and may also interact with an identity provider for OAuth.
-
Post Service - Handles all operations related to posts (creating a new post, editing or deleting a post, fetching a post’s details). It interacts with the database that stores posts. Posts are identified by IDs and associated with a subreddit and a user. The Post Service also implements content ranking logic for listing posts (often in conjunction with a Feed/Ranking component).
-
Comment Service - Manages comments on posts. It allows adding a comment, editing or deleting (if authorized), and fetching comment threads. Comments data is typically stored with references to the post and parent comment (to support nested replies). This service must support retrieving a large comment tree efficiently.
-
-
Microservice
-
Vote Service - Responsible for recording upvotes/downvotes on posts and comments. It updates vote counts (scores) and ensures a user’s vote is only counted once. The Vote Service might also handle computing the new rank or score of content after a vote, or send events to update cached rankings. Because voting is so frequent, this service must be optimized for very high write throughput.
-
Subreddit (Community) Service - Handles creation and management of subreddits. It stores subreddit metadata (name, description, and creation date), membership information (subscriber count and list of moderators), and user subscriptions to subreddits. It ensures unique subreddit names and enforces community rules. This service also helps filter or query posts by subreddit.
-
Feed Service – Responsible for assembling personalized feeds and trending lists. It might call the Post service and Recommendation service to gather posts for a user’s feed.
-
Media Service: Manages storage and retrieval of images/videos. Rather than serve large media through our main app servers, we will store media files in an object storage (like AWS S3 or a distributed file system) and serve them via CDN. The Media Service handles uploading files and returning URLs. It may also create resized thumbnails or transcoded videos for efficient delivery.
-
Search Service – Handles search queries by querying the search index (Elasticsearch or similar) and returning results.
-
Messaging Service – Stores and retrieves direct messages between users.
-
Notification Service – Sends notifications to users about events (new comment replies, direct messages, mentions, etc.). It listens for events from other services (like the Comment Service or Messaging Service) via a message queue. Notifications may be delivered as in-app notifications (stored in a database for each user), as push notifications to mobile devices, or as emails. This service must scale to handle fan-out (one event might notify many users, e.g., a new post in a popular subreddit).
-
Moderation/Spam Service – (or integrated into others) an internal service or set of tools for processing content filters, handling user reports, and giving moderators an interface to act. Some of this might be offline processes.
-
Inter-service Communication: The microservices will primarily expose RESTful APIs (or gRPC endpoints) that the API Gateway calls. For example, when a user loads a subreddit page, the request might go to an endpoint in the API Gateway, which then calls the Post Service (to get posts) and the Comment Service (to get comment counts) and aggregates the response. However, many operations are best handled asynchronously via an event stream. We will use a distributed messaging system like Apache Kafka (or RabbitMQ) to enable event-driven processing. For instance, when a user upvotes a post, the Vote Service updates the score in its database and publishes an event such as "PostUpvoted" to a Kafka topic. The Notification Service consumes that event to send a notification to the post author, and the Post Service consumes it to recompute the post’s rank. Using a queue decouples these actions and improves throughput (services don’t block waiting on each other). It also provides a buffer during spikes.
-
Data Storage: We will use a mixture of storage technologies to meet different requirements:
-
NoSQL Databases for Posts and Comments: Posts and comments are high-volume, and the access patterns involve heavy reads with fairly frequent writes. A distributed NoSQL database (like Cassandra or DynamoDB) is a good choice for this data. NoSQL stores can scale horizontally by sharding data across multiple nodes, offering high write throughput and availability. Data can be partitioned by subreddit or by post ID hash to distribute load evenly. NoSQL’s eventual consistency model is acceptable here — e.g., if a comment count or vote score is slightly stale for a few seconds, it’s not critical, while availability and partition tolerance are more important.
-
Relational Database for User Accounts and Subreddit Metadata: A traditional SQL database (e.g., PostgreSQL or MySQL) can manage user data and subreddit info. This data requires strong consistency (e.g., unique usernames, transactional updates for login/password changes). The volume of user records and subreddits is relatively smaller and fits well in a relational model. We can use an RDBMS for these, with proper indexing (username and email) and possibly read replicas to scale read operations (like profile fetches). ACID properties ensure, for example, that a username or subreddit name is unique and that authentication data is stored safely.
-
Object storage for media: All uploaded images and videos will not be stored directly in our databases (this would be too heavy). Instead, we will use a distributed object storage such as Amazon S3 or a similar system. Media files are stored as objects and accessed via CDN. Thumbnails or previews can also be stored there. This decouples heavy binary data from our main DBs. Even user avatar images are stored in object storage.
-
A Search Index store: We will maintain a separate search system using something like Elasticsearch (built on Lucene) or Solr. This will index the text of posts and comments (and possibly user profiles or titles) to allow full-text search and advanced queries. The search cluster will store inverted indexes, which are optimized for text queries, not something a SQL DB or Cassandra does efficiently. This is essentially a specialized database for search.
-
Analytics storage: For trending topics, logs, and ML data, we may have data pipelines writing to a data warehouse (such as Hadoop/Hive or BigQuery). That’s more for offline processing, not part of the live user request path, but worth noting as part of the overall system (it will read events from Kafka and store aggregated stats).
-
-
Caching Layer: To achieve fast read performance, we will use an in-memory cache (like Redis or Memcached). This cache tier will store frequently accessed data such as popular posts, front-page feeds, comment threads, and user session info. By using caching, we reduce direct database load and latency for reads. We’ll likely have a distributed cache cluster and use consistent hashing to distribute keys across cache nodes (so that if a cache node goes down, its keys are redistributed with minimal disruption). For example, caching the top N posts of a subreddit in memory can allow quick retrieval when users load that subreddit.
-
Message Queue & Streaming System: To handle asynchronous processing and decouple components, we will use a message queue like system. One good option is Apache Kafka which is a high-throughput event streaming system. The idea is that when certain events occur (such as a new post, a new vote, or a user action), instead of handling all consequences synchronously, we publish events to Kafka. Various consumers then process these events:
- An indexing consumer picks up new post events and indexes them into Elasticsearch (so search updates eventually).
- A feed fan-out consumer might take a new post and update relevant feed caches or trigger recommendation logic.
- A notification worker will consume events like “user A commented on user B’s post” to create a notification for user B.
- A spam detection pipeline might consume all new content to evaluate for spam (using ML classifiers) asynchronously.
-
Workflow (Putting it together):
- Posting Content Flow: A user’s client calls the Post Service API to submit a new post (with text or media). The API (via a gateway) authenticates the user (Auth Service verifies the token). Post Service performs any necessary checks (e.g., calls Moderation Service). The post is stored in the Posts database. The Post Service then produces events: it might publish a message like “New PostCreated” into a message queue or notify Feed Service and Notification Service. The Feed Service will take this new post and fan-out to relevant users’ feeds (for a subreddit post, the fans are all subscribers of that subreddit). The Notification Service will send real-time notifications to those subscribers if they opted in (e.g., “Subreddit X has a new post”). The post’s ID and metadata might also be cached for quick access. If the post had an image, the image was uploaded to the Media Service first and an URL was included in the post data.
- Reading Feed Flow: When a user opens their home feed, the client calls the Feed Service API (through the gateway). The Feed Service authenticates user and then fetches a list of relevant posts. Internally, it might pull from a precomputed feed cache or query the Posts database for newest posts from each subreddit the user follows, then merge-sort by ranking. The Feed Service returns a JSON of posts (with titles, thumbnails, etc.). The client then fetches any media from the CDN as needed and displays the feed. We also employ caching here: popular feeds or subreddit listings might be cached in Redis so that many users requesting the same list (e.g., the “hot” posts in r/news) don’t all hit the database.
- Voting Flow: When a user upvotes a post, the client calls the Vote Service (or Post Service endpoint). This service updates a Vote count in the database (or in a cache). To handle heavy voting, it might simply enqueue the vote in a job queue for processing so the API can return quickly. A background worker will pull from the queue to update the post’s score in the database and invalidate relevant caches (like the sorted order of posts in that subreddit). For immediate feedback, the API could optimistically update the vote count in cache so the user sees their vote reflected. The system needs to ensure a user cannot vote twice on the same item – we could enforce this by checking a User-Interaction table that logs each user’s votes.
- Comment Flow: Similar to posting, adding a comment goes to Comment Service, which writes to the Comment database and then notifies the post owner or replied user via Notification Service. The updated comment count might be sent to feed or post caches. When loading a post page, the Comment Service fetches all comments for that post (possibly from a cached precomputed tree structure for efficiency).
- Notification Flow: When an event occurs (new reply, new follower, etc.), the Notification Service directly pushes a message via WebSocket to the online user and also stores the notification to be fetched. We maintain a mapping of online users to open WebSocket connections. For scalability, if we have multiple notification server instances, they will subscribe to a pub-sub channel or message bus. For example, when a notification event is created, it’s published to a Kafka topic which all notification servers listen to, and the server with the target user’s connection will pick it and send it out. If the user is offline, we could save the notification in a table (for later retrieval) and possibly send an email or mobile push via a third-party service.
This high-level design emphasizes separation of concerns: each service has a focused responsibility, and we’ve outlined how data flows through the system. Next, we’ll delve deeper into specific components and data management details, and address how to handle the core challenges (like feed fan-out, data storage, and maintaining performance at scale).
Note: In an initial version, one might start with a monolithic architecture (all web/app logic on one server cluster and one big database). However, at “web-scale” (hundreds of millions of users), a monolith would quickly break down. The system must be distributed. Reddit’s own architecture evolved from a monolith to multiple services for scalability. Our design adopts a modular approach from the start, enabling us to meet the scale requirements.
In this section, we detail how each major component will work internally and how data will be organized and managed. This includes data schemas, partitioning strategies, and the implementation of different features under the hood.
Key Points
-
Data Model:
- Posts: Sharded NoSQL records (post_id, subreddit_id, author_id, title, content, score, comment_count, etc.) partitioned by post_id hash or subreddit for efficient queries.
- Comments: Sharded NoSQL adjacency-list items (comment_id, post_id, parent_id, author_id, content, score) sharded by post_id to localize each thread.
- Subreddits & Users: Metadata and relationships (subscriptions, moderators) in relational tables with many-to-many user–subreddit mapping; user profiles (credentials, karma) in SQL.
-
Voting & Score Management: Handling billions of vote actions:
- Vote storage: Record per-user votes to prevent duplicates, log events for audit.
- Score updates: Atomic counter increments in Redis (or DynamoDB counters), async persistence via Kafka to avoid blocking, race-free aggregation.
- Karma updates: Author points incremented asynchronously.
-
Feed Generation & Ranking: Creating personalized and trending timelines:
- On-the-fly merging: Pull top N posts per followed subreddit from Redis sorted sets, merge by “hot” score formula (votes + decay).
- Caching: Short-lived per-user feed caches and subreddit hot lists; global trending posts computed periodically and heavily cached.
-
User Messaging: Inbox-style direct messages:
- Schema: Messages table (message_id, sender_id, receiver_id, content, sent_at, is_read) partitioned by receiver for fast inbox queries.
- Workflow: POST to store and trigger notification; GET to fetch sorted messages; mark read; optional archiving of old messages.
-
Notification System: Alerting users to events:
- Event sources: Services emit Kafka events (comments, mentions, DMs, mod actions).
- Delivery: Store per-user notifications with TTL in Redis (or DB), serve via
GET /notifications; optional push or email integration; track unread counts.
-
Search Indexing & Retrieval: Full-text search over posts/comments:
- Engine: ElasticSearch (ES) cluster with inverted indexes, sharded, and replicated.
- Async indexing: Post/Comment services publish “New” or “Update” events to Kafka; indexer consumes and updates ES.
- Query handling: Search service builds queries, applies filters, and caches popular searches with short TTL.
-
Workflow Examples: End-to-end data flows:
- Create post: API → write to NoSQL → update cache → emit Kafka events → indexer, feed updater, spam detector.
- Vote: Client call → atomic Redis increment → log event → feed service updates sorted sets.
- Message & notify: Store message → emit event → Notification Service writes alert → client fetches or receives push.
Details
Data Model for Posts, Comments, Subreddits, and Users
- Posts: Each post will be represented as a data object containing the following fields:
| Field Name | Data Type | Description |
|---|---|---|
| post_id | BIGINT | Primary Key. Unique post ID (could be globally unique across shards, e.g. via a Snowflake ID generator). |
| subreddit_id | BIGINT | FK to Subreddits.subreddit_id. Subreddit in which the post is made. Indexed. |
| author_id | BIGINT | FK to Users.user_id. User who created the post. Indexed. |
| title | VARCHAR(300) | Post title text. |
| content | TEXT | Post content (text or URL). |
| content_type | VARCHAR(20) | Type of post ('text', 'link', 'image', etc.). |
| created_at | DATETIME | Post creation timestamp. |
| updated_at | DATETIME | Last edit time (if edited). |
| score | INT | Denormalized score (net upvotes minus downvotes). |
| comment_count | INT | Denormalized count of comments on this post. |
| is_deleted | BOOLEAN | Flag if the post is deleted/removed. |
Given the volume, posts will be stored in a sharded NoSQL database. Partitioning can be done by post_id hash or by subreddit_id. For example, we could incorporate the subreddit identifier into the partition key, allowing posts in the same subreddit to be spread across shards while also enabling them to be queried together. Using a wide-column store like Cassandra, we might have a primary key as (subreddit_id, post_id), which allows efficient retrieval of all posts in a subreddit (since they will be clustered by subreddit). Alternatively, a store like DynamoDB could store each post item with a primary key of post_id and a secondary index on subreddit_id for querying by subreddit. Data is denormalized as needed to avoid cross-shard joins (each post entry might also store the subreddit name or author username for convenience, or these can be fetched from the User/Subreddit service).
- Comments: Stores comments on posts, supporting arbitrary nesting (comment threads). We use an adjacency list model: each comment stores a pointer to its parent comment. All comments belong to a post. For scalability, comments can be sharded by
post_id(ensuring all comments of a post reside on one shard, which makes retrieving a post’s entire comment tree localized). Like posts, comments are also indexed in Elasticsearch for text search.
| Field Name | Data Type | Description |
|---|---|---|
| comment_id | BIGINT | Primary Key. Unique comment ID. |
| post_id | BIGINT | FK to Posts.post_id. The post on which this comment was made. Indexed. |
| parent_comment_id | BIGINT | FK to Comments.comment_id of the parent comment (NULL if top-level). Indexed. |
| author_id | BIGINT | FK to Users.user_id. User who wrote the comment. |
| content | TEXT | Comment text content. |
| created_at | DATETIME | Comment creation timestamp. |
| updated_at | DATETIME | Last edit timestamp (if edited). |
| score | INT | Denormalized score (upvotes minus downvotes) for the comment. |
| is_deleted | BOOLEAN | Flag if comment is deleted/removed (content may be null or replaced with “[deleted]”). |
The Comment Service can retrieve all comments for a given post_id efficiently by querying the comments table on the post_id partition. For nesting, we can either use recursive queries or fetch all comments for a post and then construct the tree in memory. Comments can also be sharded by post_id or by comment_id. A likely choice is to partition by post_id so that all comments for a post reside in the same partition or set of partitions (ensuring one post’s comment thread can be fetched with minimal scatter). Since one post could have thousands of comments, those partitions still need to handle high read volume. We can cache the top-level comments separately to reduce load.
- Subreddits: Subreddit data (community info) is much smaller in scale (tens of thousands to maybe millions of subreddits, versus hundreds of millions of posts). We can store subreddit metadata in a relational database. Each subreddit record contains
subreddit_id,name(unique),description,creation_date, and lists of moderators or rules. The number of subreddits is not huge, so even a single SQL table could hold them. The Subreddit Service provides APIs to create a subreddit (which inserts a new row) and to query information about a subreddit. We also need to manage user subscriptions to subreddits: this is a many-to-many relationship between users and subreddits. This could be stored as a separate table (user_id, subreddit_id) pairs. - User Data: Each user has a profile with username, hashed password (if using our own auth), email, join date, karma points, etc. This goes into the User Service’s relational database. It’s essential that this is consistent and secure. We’ll have unique constraints on username and email. The user’s subscriptions to subreddits, as mentioned, might be stored with the Subreddit Service, but could also be partially cached with the User Service for quick lookup.
- Data Size and Partitioning: By partitioning posts and comments across many nodes, we ensure no single machine handles all write traffic. Consistent hashing can be used to allocate new partitions as the data grows. We might have, say, 100 Cassandra nodes, each holding a portion of the data. Replication factor (e.g., 3) in Cassandra ensures that each piece of data is stored on 3 nodes for fault tolerance. For DynamoDB, throughput capacity is managed by AWS and can scale transparently, but we still design keys to avoid “hot partitions.” Using the subreddit ID as part of the key helps distribute popular subreddits across multiple partitions if needed.
Voting and Score Management
Voting is a critical feature that directly influences content ranking. However, handling billions of votes efficiently is challenging. Key design points for the Vote Service and data handling include:
- Storing Votes: We need to record each user’s vote on each item to prevent multiple voting and to allow un-voting. This can be a record in a database table or NoSQL store keyed by
(user_id, post_id)storing the value (+1, -1, or 0 if no vote). However, storing every single vote in a centralized store might be too much load given 1B votes/day. A pragmatic approach is to maintain an eventually consistent log of votes and focus on keeping the vote counts up to date in real-time. - Vote Counts: The primary thing we need immediately is to update the score (net votes) of the post or comment. We will use a high-throughput key-value store or in-memory counter for vote totals. For example, when a user upvotes a post, the Vote Service can increment that post’s score in Redis. Redis can handle millions of ops/sec and can increment a counter atomically. This updated score can be cached and also eventually persisted to the main post database (or a separate aggregation store). Alternatively, if using DynamoDB, we could use its atomic counters feature to update a numeric attribute. The key is to decouple the frequent small updates from the heavy data store.
- Asynchronous Processing: To avoid making the user wait on heavy updates, voting actions are handled asynchronously. When a vote is received, the Vote Service quickly logs the action (e.g., writes to a commit log or sends to Kafka) and returns success to the user. A background worker (or the same service in another thread) then updates the necessary counts. By queuing the vote events, we buffer them and process them in batches if needed (e.g., aggregate multiple votes to the same post within a short window). This improves throughput and user-perceived latency.
- Preventing Race Conditions: With multiple votes coming in, especially in a distributed system, there is a risk of race conditions updating a score. To handle this, the vote update could be done by a single consumer or through the use of atomic operations. If using Redis, the increment is atomic. If using a log + batch update, then the final aggregation can happen with locking or eventually correcting itself (since if two updates race, the order doesn’t matter for addition).
- Storing Karma: User karma (points accumulated from upvotes on their content) is another thing that needs to be updated when votes happen. This can be handled similarly by incrementing the author’s score count in a User Stats store asynchronously. It’s not as time-sensitive.
- Downvotes: A downvote might decrement the score. The logic is similar. We must ensure a user’s vote change (from upvote to downvote, etc.) adjusts counts correctly (possibly by reading the old vote value, which is why storing user vote history is useful). This read-modify-write can still be done in the Vote Service’s memory or a fast DB.
- Ranking implications: The Vote Service might notify the Post Service (via events) that a particular post’s score changed significantly. The Post Service can then recalculate that post’s ranking in its subreddit or globally. More on ranking below.
Feed Generation and Ranking
One of the hardest parts of a social platform is efficiently delivering feeds – the lists of posts users see – especially as content and user counts grow. We have two main approaches to deliver feeds:
- Pull Model: Compute a user’s feed on-the-fly when they request it. The server will query the latest posts from each subreddit the user follows, merge them, sort by ranking, and return the result. This ensures the feed is fresh, but doing this heavy computation on every request can be slow if the user follows many communities or if there are thousands of new posts.
- Push Model (Fan-out on write): Pre-compute and store feeds for each user whenever new content is created. On a new post, determine which users should see it (all followers of the user or subscribers of the subreddit) and immediately fan-out add that post to those users’ feed data (often in a feed cache or database). This makes reading very fast (just read a pre-made list), but writing can be expensive if a post has to be copied to thousands or millions of feeds.
We will use a hybrid approach for Reddit-like design:
- For most users and communities, use the push model. E.g., if a subreddit has a manageable number of subscribers (say thousands or a few million), when a new post arrives, the Feed Service will push that post ID into a feed queue or feed datastore for all subscribers. We could maintain a feed database where each user has a sorted list of recent postIDs. This way, when User A opens their app, we just read their feed list (from a cache or fast DB) and fetch those posts.
- For very large fan-out cases (the “celebrity problem” or extremely large subreddits with tens of millions of subscribers), pushing to everyone could overwhelm the system. In those cases, we fall back to pull model on demand. For example, a post in r/all or r/pics (with huge subscriber counts) might not be pushed to every user. Instead, when users load their feed, if it includes r/pics, the system will fetch the latest posts from r/pics at that moment. This saves us from writing millions of entries at post time and spreads out the load as read queries.
- In practice, we can implement this by setting a threshold: e.g., if a subreddit’s subscriber count is below X, do push fan-out; if above, mark it for pull. Also, a hybrid approach could be push to a certain point, then let less frequent users pull. For instance, maybe push to the first 100k online users and let the rest pull later.
Feed Ranking: After determining which posts go into a feed, we need to order them. We will implement Reddit-like ranking algorithms:
- By default, Reddit’s “hot” algorithm ranks posts using a combination of score (upvotes minus downvotes) and age. As per Reddit’s published formula:
score = log10(|upvotes - downvotes|) + sign(vote_difference) * (post_age_in_seconds / 45000). This essentially means a post with a lot of upvotes will rank high, but as it gets older, newer posts can overtake it even with fewer votes, keeping the feed fresh. We will use a similar approach for the home feed and subreddit feeds. We can compute this ranking score whenever a post’s votes change or as part of feed assembly. - We also provide other sort options (new, top, etc.). “New” is just chronological. “Top” might be all-time score or within a time range. These can be computed with simpler queries (e.g., top = most upvotes).
- Implementation: We will likely maintain sorted data structures for feeds. For example, for each subreddit, we could maintain a sorted list of postIDs by their “hot” score. This could be in a sorted set in Redis. That way, retrieving the top N posts for a subreddit is fast. When votes come in, we’d update the score and adjust the sorted set. This is heavy if done synchronously, so we might use background workers for this as mentioned (vote queue that updates rankings). Alternatively, we recompute on reads, but caching results is important.
- The Feed Service when constructing a user’s personalized feed might pull the top posts from each subscribed subreddit’s sorted set and then merge them. Merging many lists is still expensive if a user has 100 subscriptions. To optimize, we could maintain a per-user feed cache that is directly a sorted set of all their posts. This is what push model accomplishes (pre-merged feed).
- Given the complexity, we might do a combination: maintain per-subreddit sorted lists and for heavy users or frequent loads, do on-the-fly merging, but for very active users, also maintain a cached feed.
Caching Feeds: We heavily utilize caching for feeds. For example, the front page (r/popular or aggregated) is seen by many users; we can cache that query result for a short time (say 1 minute) so that not every request triggers DB work. User-specific feeds can also be cached in memory (perhaps stored in Redis with a key like feed:user123) for quick retrieval. This cache would be invalidated or updated whenever new posts arrive for that user. The job queue approach can be used: on a new post or vote, enqueue tasks to update relevant cached lists.
Feed Example: If User A follows subreddit X and Y, and user Z:
- When a new post is made in subreddit X, the feed service finds all users following X (from the Subscription table, possibly using an index or a pub-sub mechanism) and appends the post to their feed list. Similarly if user Z (who A follows) posts.
- If A opens their feed, the service either pulls A’s cached feed (already sorted) or queries “latest from X, Y, Z” and sorts. Given real-time requirements, caching and precomputation are preferable for an engaging experience.
User Messaging Design
For user messaging (DMs), the system functions like a simple mail inbox. Real-time delivery (as in chat) is not required, which simplifies things: we do not need persistent WebSocket connections or instantaneous typing indicators. Instead, we focus on reliable storage and retrieval of messages and notifications when new messages arrive.
Messages Table: Stores private direct messages between users. This table is smaller and can be replicated fully or sharded by receiver_id.
| Field Name | Data Type | Description |
|---|---|---|
| message_id | BIGINT | Primary Key. Unique message ID. |
| sender_id | BIGINT | FK to Users.user_id. User who sent the message. |
| receiver_id | BIGINT | FK to Users.user_id. User who is the recipient. |
| content | TEXT | Message content body. |
| sent_at | DATETIME | Timestamp when the message was sent. |
| is_read | BOOLEAN | Flag if the receiver has read the message. |
Workflow for messaging
-
Sending a Message: When user A sends a message to user B:
- The client (A’s browser/app) calls the Messaging Service API (e.g.,
POST /messages) with the recipient B and content. - The Messaging Service authenticates A, checks whether B exists, and ensures that A is not blocked by B (for some abuse prevention).
- The service creates a new message record in the database. This could be inserted into a table partitioned by B (the recipient) so that B’s inbox has this message. If using Cassandra: partition key = B’s user_id, cluster by timestamp (so B’s messages are sorted by time). The message ID can be a UUID or time-based ID to ensure uniqueness. The message status is initially set to “unread.”
- The service could also simultaneously insert a copy or pointer in A’s “sent messages” if we want that feature (or we can derive the sent folder by querying messages where sender = A).
- After writing to storage, the service sends a notification: it will send an event to the Notification Service (or directly create a notification for B: “You have a new message from A”). If B is online, we might push a notification event. If not, it will be available when B checks.
- The service returns success to A’s client. A sees the message in their outbox as sent.
- The client (A’s browser/app) calls the Messaging Service API (e.g.,
-
Receiving a Message: When user B wants to read messages (say B opens their inbox):
- The client calls
GET /messages(or a websocket could push, but let's assume it pulls). - The Messaging Service fetches messages for B from the datastore. Since we partitioned by user, this is efficient – retrieve the list sorted by time. We might implement pagination if B has many messages (e.g., fetch last N).
- The service returns the list. The client displays them. The client might periodically poll for new messages or rely on notification prompts.
- When B reads a message, the client might call an API to mark it
read. The service updates the message record (settingis_read=trueor moving it from an unread set to read). - The Notification for that message could be marked as read as well, so B’s notification count goes down.
- The client calls
-
Data storage and consistency: Since losing messages is unacceptable, we will replicate this data. If using Cassandra, the replication factor ensures durability (multiple nodes have the data). If using SQL, we’d have a primary-replica setup, and the message write goes to the primary. We’ll also back up messages regularly. The data model is straightforward, and since writes are not super high (messaging is likely a fraction of overall site usage), consistency can be strong here (write and read your message immediately).
-
Scale considerations: If even 10% of 100M users send one message a day, that’s 10 million messages/day, which is significant. However, each message is typically only a few hundred bytes of text. Over the course of a year, ~3.6 billion messages are sent, which is a significant amount. However, partitioning by user means that no single query touches billions; only those relevant to a single user are affected. We will need to ensure the partitioning is even – some users (such as mods or very active users) might receive thousands of messages, but that’s still acceptable. We might also consider auto-archiving old messages (e.g., those older than X years) to secondary storage, which would help keep the active dataset smaller.
In short, the Messaging component is like a mini email system: it stores messages reliably, allows retrieval by the user, and ties into notifications for new message alerts. It’s simpler than real-time chat and can be built on top of existing database tech with partitioning.
Notification System
The Notification system ensures users are kept aware of relevant events (without having to constantly check everything). Design considerations for notifications:
-
Types of notifications: replies to your comment/post, mentions (@username in a post), new messages, someone followed you, moderator invites or actions, etc. Each type might have slightly different data (e.g., a reply notification needs to identify the comment and maybe include a snippet of text).
-
Event Sources: Various services will generate events:
- Comment Service generates “User X replied to your comment Y in post Z”.
- Post/Comment Service for mentions “User X mentioned you in post Z”.
- Messaging Service for “New message from X”.
- Moderation service for “Your post was removed by mods,” or “You earned a badge,” etc.
- We could also have periodic notifications, such as “Trending in a subreddit you follow,” which would come from a trending service or a cron job.
-
Delivery mechanism: We can handle notifications via:
- Push to device/browser: e.g., using Web Push API or mobile push notifications for instant alert. This requires capturing device tokens and integrating with APNs or FCM (mobile push services). It’s an extension beyond core web functionality, but likely desired for a modern service.
- In-App Notification Center: The website/app will feature a notifications inbox (similar to the bell icon on Reddit). The client will fetch notifications from the server (e.g.,
GET /notifications) periodically or when the user opens the panel. - Email: Optionally, send email notifications for specific events (if the user has opted in, such as a summary email or an immediate notification for direct messages).
For our design, we focus on storing and retrieving notifications in-app; however, it’s worth noting that push/email could be integrated by having the Notification Service call external email/SMS gateways.
-
Storage: Notifications can be stored per user, ideally in a fast store like Redis for quick access. For durability, we could also log them to a database or at least replicate the Redis (Redis can have AOF persistence, or we can mirror writes to a backup DB). Each notification is small (a type, an id pointer, a short message).
-
Workflow: Using an example: User A commented on User B’s post.
- Comment Service processes A’s comment on B’s post. It sees that the post’s author B should be notified of a new comment.
- It publishes an event
CommentAdded {post_id, commenter=A, post_author=B, comment_id}to Kafka. - The Notification Service consumes this event. It creates a notification in storage: key = B’s user_id, value = “User A commented on your post X” with a link to that comment. It sets it as unread.
- If B is currently online, the Notification service could send a real-time update. For example, if B has a WebSocket open, send a message over it to increment their notification count. If not, rely on the next fetch.
- When B opens the app, they call
GET /notifications. The service fetches B’s notifications (say the last 20) from the sorted set (sorted by time) and returns them. The unread ones are marked or counted. - B sees the notification, clicks it (which leads them to the comment). Optionally, the client or server marks that notification as read (so it can be excluded from the unread count or moved out of the “new” list).
-
Scalability: Notifications can be frequent, but each user’s list is manageable. The write volume of notifications equals the number of events to notify. Potentially, with 100M DAU, if each user triggers even 0.1 notifications on average (like 10M notifications per day), that’s still acceptable, as it’s similar to the message volume. The key is that these writes are short, and we can batch them if needed.
-
Clearing Old Notifications: We don’t want to store every notification forever, or the lists will become long. We can auto-expire notifications older than, say, 30 days. Using Redis with an expiration TTL on each notification entry, or periodically trimming the list per user, can achieve this.
-
Handling read state: We could keep an
unread_countfor each user (increment on new notification, decrement on read). This can live in an in-memory store or be computed from the list. Usually easier to maintain a counter field in a small DB or cache. -
Design choice: We might implement Notification Service as part of or alongside the Messaging/Feed services, but conceptually it's distinct. It heavily relies on events from other parts of the system (so it’s a good use of the publish-subscribe pattern via a message queue).
Overall, notifications enhance user engagement by alerting users to relevant interactions. The system uses an event-driven approach to capture events and deliver notifications asynchronously. High availability is important (we don’t want to lose notifications), so the process should be reliable (using durable queues and redundant storage).
Search Indexing and Retrieval
Search is a critical feature given the huge volume of content. Users should be able to search for posts (and possibly comments) by keywords, with options to filter by community, date, or author. Implementing this at scale requires a specialized search engine.
-
Search Engine (Elasticsearch/Solr): We will set up an Elasticsearch cluster to handle indexing and querying. Each post (and possibly each comment) will be indexed as a document. The index will include fields such as title, body, author, subreddit, and creation time, among others. We’ll use inverted indexes for keywords, which allow efficient full-text search over millions of documents by keywords. The search service supports advanced queries, including phrases, boolean conditions, filtering by subreddit or author, and sorting by relevance or date. Elasticsearch can handle this with proper mapping and queries.
-
Index Updates: Whenever new content is created or updated (such as a post or comment), it must be added to the search index. This will be done asynchronously:
- The Post Service, after writing a new post to the database, will publish an event (e.g. to Kafka: “NewPost {id:123, subreddit:X, ...}”). A Search Indexer service (a consumer) will pick up this event and then index the document in Elastic. The indexer will extract the text fields and call the Elasticsearch API to add a document. Similar for comments (though we might decide to index comments only for certain search types, or separately).
- If a post is edited or deleted, corresponding events trigger update or deletion in the index. (Deleting is important so that we don't show removed content in results.)
- There will be some lag (a few seconds) between a post creation and it being searchable – this is acceptable for eventual consistency in search.
-
Index Size and Sharding: The search index can encompass billions of documents (including all posts and comments). We will need to shard the index across many nodes. Elasticsearch can automatically shard indices (e.g., up to 50 shards or more, each hosted on different servers). Queries are distributed to all shards, and the results are merged. To keep indices manageable, we might partition by time or by subreddit. For example, have an index per year, or per major category, to limit any single index’s size. Alternatively, maintain a single, large index with multiple shards. We’ll also keep replicas of each shard for fault tolerance (if one node fails, the replica serves).
-
Query Processing: When a user searches (i.e., they input a keyword and optional filters), the request is sent to the Search Service. This service will:
- Parse the query and construct an Elasticsearch query (including full-text search on the keywords and filters for subreddit, etc.).
- Send the query to the Elastic cluster, which executes it across shards. Elastic will return a ranked list of matching documents (posts) along with their scores. We can post-process if needed (e.g., filter out any deleted content that might still be indexed, or apply permissions if some communities are private).
- The service then formats the results (possibly fetching additional information, such as snippets or highlights, and the post metadata). It might call the Post service or cache to get the current vote count or comment count for display alongside each result.
- Results are returned to the client, possibly paginated if many results.
-
Caching search queries: Popular search queries (such as “cute cats” on Reddit) are often repeated. We could cache the results of common queries for a short time. However, since search results are updated with new content, the cache TTL may be set to a low value (minutes). Still, if thousands of users search the same trending term, caching can reduce the load on Elastic. We can use an LRU cache keyed by query+filters in the Search service for this.
-
Search Throughput: Search queries can be expensive (scanning lots of index). The search cluster needs to be scaled according to query volume. If, say, 5% of users perform searches during peak times, that could result in thousands of queries per second. We’ll ensure the Elastic cluster has enough nodes and may implement query rate limiting to prevent abuse (e.g., someone sending 100 queries per second could degrade performance). Heavy search usage might also require horizontal scaling by adding more shards or splitting indices by topic.
In summary, the Search subsystem is built around an engine similar to ElasticSearch with asynchronous indexing.
Putting it Together: Workflow Examples
To illustrate end-to-end how data flows through the designed components, consider a couple of scenarios:
-
User creates a post:
- User hits “submit” on a new post in subreddit X. The request goes to Post Service.
- Post Service validates (user auth, subreddit exists, user not banned in X, content length, etc.). It writes the post to the Posts DB (Cassandra). It sets the initial score=1 (the user's upvote).
- In parallel, it writes to a cache (maybe update subreddit X’s “new posts” list in Redis).
- It enqueues events: “NewPost” event to Kafka with post details.
- A Search indexer gets this event and indexes the post for search.
- A Feed updater gets it – it updates the sorted set for subreddit X hot posts (initial score) and possibly checks if this post is trending enough to notify some users. At least, it’s now in the pool for future feed fetches.
- A Notification event might be generated if some users requested notifications for new posts in a subreddit (not common, but could be a feature like “alert me of new posts in my own community” for mods).
- A Spam detection service gets the event and checks the content. If flagged, it may immediately mark the post as removed (update the DB status and possibly send it to the mod queue).
- The user gets a success response. Other users will see this post when they next load the subreddit or their home feed (if they subscribe to X and the post ranks).
- If a mod removes the post shortly after (via mod tools), a Mod action event could trigger search index removal and feed removal.
-
User votes on a post:
- User clicks upvote. The client calls the Vote Service with the post ID and vote action.
- The service checks if this user has already voted. It may be retrieved from a Redis cache of users’ votes or a Vote DB. If no vote or a change in vote, it is accepted.
- It increments the post’s score (maybe in a counter service or DB). Possibly the vote count update is done in-memory and queued (not to lock the DB for each vote). But assume a simple approach: update the Post record’s score or a separate score table.
- It records the user’s vote (in a user->post vote table or cache) to prevent re-voting.
- In the background, it emits an event “Vote {post, newScore}”. The Feed service listening can then update that post’s ranking in the subreddit’s sorted set (maybe bump it up). If the post gains a lot of votes quickly, the Trending logic might catch it and include it in the global trending list.
- The user sees the vote reflected immediately (we optimistically updated the client, or the API returns a new score).
- If the vote triggers any threshold (maybe an upvote causes the post to hit the front page), nothing special in the system, except it appears in more feeds due to rank.
-
User receives a message:
- Another user sends them a direct message, which is routed through the Messaging Service and stored.
- The Notification Service gets an event, stores a notification for a new message.
- If the user is online, perhaps a WebSocket server (if we have one for notifications) sends a “ding”. If not, an email may be sent after a few minutes if they don’t see it.
- When the user clicks their inbox, the Messages are fetched from storage and marked read.
Each of these flows involves multiple components but is designed in such a way that heavy lifting (like updating many indices or sending many notifications) is done asynchronously and does not block the user’s action.
To meet the demands of a web-scale system, we employ multiple strategies to scale horizontally and maintain high performance:
1. Horizontal Scaling of Stateless Services: All our core services (Auth, Post, Feed, etc.) are designed to be stateless and thus can run behind load balancers with multiple instances. If user traffic increases, we simply deploy more instances of each service. Because state (data) is in the databases and caches, any service instance can handle any request for a given type. This gives us near-linear scaling on the application layer – for example, if one API server can handle 1000 requests/sec, 10 servers can handle 10k/sec. We also plan for auto-scaling: monitoring CPU, memory, and QPS, automatically adding or removing server instances according to demand (which is useful given diurnal traffic patterns).
2. Database Sharding and Replication: The databases are often the bottleneck in large systems, so we must scale them:
- We will use replication (master-replica or leader-follower setup) for read-heavy data. For instance, user profile or content databases will have one primary for writes and multiple replicas to serve read queries. The Feed Service and others can read from replicas, spreading load. Replication also provides high availability – if a primary fails, a replica can take over.
- We implement sharding (data partitioning) to distribute data across multiple database servers. As mentioned, we can shard by entity type (different clusters for posts, comments, etc.), and also shard within an entity. For example, we might partition posts by their ID or by subreddit. If using SQL, that could mean separate table instances or schema per shard. If using Cassandra, we rely on its partitioning.
- The choice of sharding key is crucial: Subreddit-based sharding is intuitive – all posts for a subreddit go to the same shard. This localizes community data, which is good for locality of reference (e.g., pulling all posts from one community hits one shard). It also means a very large subreddit could overload one shard. To mitigate that, we can further split very large communities across shards or use hash-based sharding for posts of large communities.
- Another approach is userID-based sharding (store all content by users whose IDs hash to a shard). This balances write load if active users are evenly distributed, but a popular community post (with many authors involved) still touches multiple shards. A hybrid could exist (shard primary content by community, but globally shard extremely large communities separately).
- We also separate hot data vs cold data: recent posts and comments could live in faster storage, and older archived data could move to cheaper storage. For instance, posts older than a year might be stored in a different cluster or even static storage if rarely accessed.
3. Caching Everywhere: Caches are our best friend for performance:
- We use an in-memory cache cluster (Redis/Memcached) to cache results of frequent queries: e.g., the front page feed, top posts of big subreddits, recent comments on a popular post. When a read request comes in, the service first checks the cache. If present, it returns the cached data in a few milliseconds (in-memory retrieval), avoiding hitting the database. If not present, the service fetches from DB, then stores the result in cache for next time.
- We will employ cache invalidation strategies to keep data fresh. For example, when a new post is added or a vote changes a ranking, we invalidate the cached feed or post list for that subreddit/user. Some caches can also expire entries after a short time (TTL) so they refresh periodically. Reddit specifically used an atomic read-modify-write to update cache and also used locks to prevent race conditions when many updates occur.
- The cache cluster is distributed via consistent hashing so we can scale it by adding nodes. If one cache server fails, its keys are redistributed to others (and those will miss until repopulated, but the system remains running).
- Content Delivery Network (CDN): All our static content (images, videos, and possibly static HTML/JS for web) is cached globally on CDN servers. This drastically reduces load on our servers for media and speeds up content delivery (since CDNs serve from locations near users and are optimized for static file delivery). We offload as much as possible to CDNs – user profile pictures, post images, etc. The CDN also helps absorb traffic spikes (e.g., an image going viral won’t overwhelm our origin servers).
- Browser Caching: We can leverage user browsers as well. Set cache headers on images and API responses where appropriate so the client doesn’t refetch data unnecessarily (e.g., avatars or already seen posts).
4. Asynchronous Processing: We extensively use message queues and background workers to handle tasks that need to be done but not necessarily immediately:
- Queue for Feed Updates: When a new post or comment is created, instead of synchronously notifying every follower or recomputing feeds (which would slow down the posting action), we place a job in a fan-out queue. Worker processes take these jobs and update user feeds or send notifications in the background. This decouples the write path from the expensive distribution work.
- Queue for Vote Counting: As described, votes go to a queue. This smooths out spikes in voting and allows batching. For example, a worker could aggregate 100 votes on the same post that came in a short window and then apply a single update to the ranking, reducing overhead.
- Rate Limiting Queue: If a particular subreddit is extremely hot (e.g., a live thread with thousands of comments per minute), we could isolate it by processing its events in its own queue and even apply a quota (as Reddit did with queue quotas). This prevents one busy subreddit from starving processing resources for others.
- Notification Delivery: Use async jobs to send out notifications (e.g., sending an email might be done via a worker to avoid delaying the main flow).
- Batch Operations: The recommendation jobs and any analytics (like generating weekly top posts email) are run as offline batches during off-peak hours to not interfere with interactive load.
5. Load Balancing and Traffic Management:
- As mentioned, we have a load balancer for incoming requests. We might also have internal load balancing where an API gateway routes calls to different service clusters. For microservices communication, we could use a service mesh or discovery system to evenly distribute calls among service instances.
- We need to handle spikes in traffic elegantly. Strategies include auto-scaling, but also graceful degradation. For instance, if the homepage is receiving too much traffic, we might temporarily serve a slightly stale cached version to everyone (trading freshness for speed). Or if the notification system is lagging, we ensure the core feed is not affected, and we can delay less critical notifications.
- Implement rate limiting on APIs to prevent abuse (for example, limit how many posts or comments a user can submit per minute, or how frequently they can refresh the feed). This protects the system from accidental or malicious overload.
6. Handling Failures and Redundancy:
- Each service should ideally run in at least two availability zones or data centers. We design the system such that if one data center goes down, another can take over (this involves replicating data across regions, which is complex, but at least for critical data like user accounts, we might have cross-DC replication).
- Within a data center, we have redundancies: multiple app servers (if one crashes, LB stops sending to it), multiple cache nodes (if one fails, we lose its cached data but not permanent data), and database replicas (if the master fails, promote a replica).
- Use of consistent hashing in caches and possibly in request routing means the system can tolerate node changes smoothly.
- We also plan backup and recovery processes for data (regular backups of databases, etc.).
7. Performance Optimizations:
- We will use efficient data structures and algorithms in our services. For instance, for feed merging, if we do on-demand merging of sorted lists, we ensure to use a min-heap or k-way merge algorithm which is O(n log k) (where k is number of sources). We will avoid N^2 algorithms on large lists.
- Use pagination and lazy loading: We never fetch an unbounded number of posts or comments in one go. Feeds will be paginated (e.g., 20 posts at a time). Comments similarly load 50 at a time. This controls memory and CPU usage per request.
- We might precompute some aggregates. E.g., maintain a count of comments on each post so we don’t have to COUNT() on the fly. Or keep track of the top N posts of the last hour to make “trending” queries fast.
- CDN and edge caching for API?: In some cases, even API responses that are same for many users (like a public subreddit feed) could be cached at the edge. But since most feeds are user-specific, this is limited.
- Use of connection pooling, prepared statements, etc., in the services to optimize database access. Also, using a content delivery technique for notifications (like long polling fallback for older browsers if WebSocket not available, etc).
Trade-offs and Final Thoughts: Our design choices balance complexity with performance:
- We chose a more complex architecture (microservices, queues, caches) to meet scalability and reliability goals. This adds development overhead (communication between services, potential consistency issues) but is necessary for a large system.
- We accept eventual consistency in places (feeds, counts) to get better performance and user experience. The trade-off is that users might not see absolute real-time accuracy in counts, but they get a fast, responsive app.
- By partitioning data (both vertically by entity and horizontally by key), we ensure no single database becomes our Achilles heel, at the cost of having to manage multiple database systems and possibly complex join logic (which we mitigate with denormalization and carefully designed APIs that don’t require cross-shard joins).
- The push vs pull hybrid feed means extra complexity, but it solves the celebrity problem where a naive push would break. We deemed this necessary to handle cases like very popular subreddits or users, ensuring the system doesn’t get overloaded delivering millions of updates in one go.
- Using WebSockets for notifications gives a snappy user experience (real-time updates), but means we have to maintain a lot of open connections and state. We considered that trade-off and found it acceptable given the requirement for real-time notifications; we mitigate the load by segregating that functionality into its own scalable service and possibly using specialized brokers.
Finally, with this architecture, our platform should be able to handle the target load: the modular design allows scaling each part (web servers, databases, cache nodes) independently. We have addressed the main challenges of a Reddit-like system – ensuring fast reads through caching and precomputation, handling heavy writes via queues and sharding, and keeping the user experience real-time and personalized. The design is complex, but it covers reliability, scalability, and performance, which are all essential for a modern social media system at large scale.
🤖 Don't fully get this? Learn it with Claude
Stuck on Designing Reddit? Open Claude, copy a block below, and it'll teach you this exact concept — visually and interactively.
Progressively stronger hints — you still solve it.
I'm working on the problem **Designing Reddit** (System Design). Give me a HINT LADDER: start with the tiniest nudge, then wait. Only reveal the next, stronger hint when I ask. Do NOT show the full solution unless I type 'show solution'. Keep me doing the thinking. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
See the technique, not just code.
Explain the optimal approach to **Designing Reddit** with a VISUAL walkthrough: trace it on a small concrete example using ASCII art / a step-by-step diagram, narrate what changes each step, then give time & space complexity with a one-line derivation. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Catch bugs, edge cases, sub-optimality.
I'll paste my solution to **Designing Reddit**. Review it for correctness, missed edge cases, and time/space complexity, then coach me toward the optimal — don't just rewrite it. Ask me to paste my code now. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Lock in recognition with look-alikes.
Give me 2 problems that use the SAME underlying pattern as **Designing Reddit**. For each, let me attempt first, then review my answer and name the trigger signal that reveals the pattern. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.