Data Partitioning
Step 10 in the System Design path · 5 concepts · 0 problems
📘 Learn Data Partitioning from zero
Data partitioning (a.k.a. sharding) splits one large dataset across many smaller stores so no single machine has to hold all the data or serve all the traffic. In an interview, the moment your estimate crosses what one box can hold (~a few TB) or one node's write throughput (~10k–50k writes/sec), the interviewer expects you to reach for partitioning — and, more importantly, to reason out loud about HOW you split the data, the routing cost it adds, and the failure modes (hot shards, cross-shard joins, rebalancing) it introduces. This walkthrough teaches the mechanism step by step so you can defend a choice rather than just name-drop "we'll shard it."✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○Introduction to Data Partitioning
- ○Partitioning Methods
- ○Data Sharding Techniques
- ○Benefits of Data Partitioning
- ○Common Problems Associated with Data Partitioning
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 You estimate your user table at 50 TB and 200k writes/sec. A single beefy DB node tops out around 2–4 TB of working set and ~20k writes/sec. What problem are you actually solving by partitioning, and what are you NOT solving?
Reveal the reasoning
Cause → effect chain:
- One node caps at ~2–4 TB and ~20k writes/sec → 50 TB / 200k writes/sec cannot fit on one machine, period.
- Partition into ~20 shards → each holds ~2.5 TB and ~10k writes/sec → now each shard is comfortably within one node's limits.
- Effect: you scale capacity AND write throughput horizontally by adding shards instead of buying a bigger box (which hits a hard ceiling).
What it does NOT solve / the cost: partitioning helps writes and storage, but a single hot row (e.g. one celebrity's record) still lives on ONE shard — partitioning doesn't fix per-key hotspots. It also adds a routing layer and makes any query that spans keys (joins, aggregates) far more expensive. Don't partition prematurely: under ~1–2 TB, vertical scaling + read replicas is simpler and cheaper.
🤔 You shard a 50 TB user-events table. Option A: partition by timestamp range (Jan→shard1, Feb→shard2…). Option B: partition by hash(user_id). Today's events are 90% of writes. Which option melts down, and why?
Reveal the reasoning
Range by timestamp (A) melts down:
- 90% of writes are for "today" → today always maps to the SAME (newest) range shard → that one shard absorbs ~180k of 200k writes/sec while the other 19 shards sit idle.
- Effect: a hot shard — you've added 20 nodes but throughput is still bottlenecked at one node's ~20k/sec. The system falls over.
Hash by user_id (B):
hash(user_id) % Nscatters writes uniformly → each of 20 shards gets ~10k writes/sec → load is balanced.
The trade-off you just bought: hashing destroys ordering. A query like "all events between Mar 1–7" must now fan out to all 20 shards and merge results, instead of hitting one range shard. Rule of thumb: hash for even write distribution; range when your dominant query is a range scan AND your writes aren't time-skewed.
🤔 You route with shard = hash(key) % N where N=4. Traffic grows, you add a 5th node so N=5. How many of your existing keys now point at the wrong shard?
Reveal the reasoning
Cause → effect chain:
- A key's home was
hash(key) % 4; its new home ishash(key) % 5. These almost never match. - Concretely: only keys where
hash % 4 == hash % 5stay put — over the 20 residues of LCM(4,5), exactly 4 of 20 match → roughly 80% of all keys must physically move when going 4→5. - Effect: adding ONE node triggers a near-total reshuffle → massive data migration, cache invalidation storm, and reads return stale/missing data during the move.
Cost / takeaway: plain mod N is fine only if N never changes. The instant you need to add or remove a node — which scaling guarantees — mod N is catastrophic. This is exactly the pain that consistent hashing exists to fix (next step).
🤔 Consistent hashing claims that adding a 5th node moves only ~1/5 of keys instead of ~80%. By what mechanism does it confine the damage to one node's worth of data?
Reveal the reasoning
Mechanism, step by step:
- Map the hash output onto a ring — the space
[0, 2³²)wrapped end-to-end. Place each node at a point on the ring. A key lands on the ring athash(key)and is owned by the next node clockwise. - Add a 5th node → it lands at one spot on the ring and only steals the arc of keys between it and its clockwise neighbor → only the keys in that one arc move (~1/N ≈ 20%), and only from ONE adjacent node. Every other node is untouched.
- Effect: scaling up/down moves ~
1/Nof data, not ~all of it → cheap, incremental rebalancing.
The remaining problem + its fix: with few nodes, random ring placement gives uneven arc sizes → one node owns 40% of the ring, another 10% → imbalance. Fix: give each physical node many virtual nodes (e.g. 100–256 points each) → arcs average out → load variance drops to a few percent. Cost: more metadata to track virtual-node placements.
🤔 You used hash partitioning AND virtual nodes — load is perfectly even at the key level. Then Taylor Swift's account (one user_id) starts getting 50k reads/sec on Black Friday. Why does your "balanced" system still have a hot shard?
Reveal the reasoning
Cause → effect chain:
- Partitioning distributes load across keys, but a single key always hashes to exactly ONE shard → all 50k reads/sec for that one
user_idhit one node. - That node's ceiling is ~20k–50k req/sec → it saturates and starts dropping requests, while the other 19 shards are bored.
- Effect: even-with-perfect-hashing, a single hot key recreates the hot-shard problem you thought you solved.
Fixes and their costs:
- Replicate the hot key across multiple nodes and load-balance reads → solves read hotspots, but now writes must fan out to all replicas → write amplification + staleness.
- Add a cache (e.g. Redis) in front for the hot key → absorbs reads, but introduces cache-consistency/staleness.
- Salt the key (append a suffix →
swift_0..swift_9) to spread one logical key over 10 shards → but every read must now query all 10 salt buckets and merge.
Lesson: partitioning balances the many, not the one.
🤔 Users are sharded by hash(user_id). Orders are sharded by hash(order_id). A query needs "all orders for user 42 joined with the user's profile." Why is this now slow, and what design choice would have prevented it?
Reveal the reasoning
Cause → effect chain:
- User 42 lives on, say, shard 3 (by
hash(user_id)). But that user's orders are scattered across ALL shards (because each order is placed byhash(order_id), independent of who owns it). - The join must scatter-gather: fan out to all 20 shards, pull matching orders, ship them back, and join in the application layer.
- Effect: latency is governed by the slowest shard (tail latency dominates) and you pay 20× the query work → a join that was 5 ms on a single DB becomes 50–200 ms.
The preventing choice: a good partition key. Shard orders by hash(user_id) too (not order_id) → user 42 AND all their orders co-locate on the same shard → the join is local and fast again.
Cost of that choice: co-locating by user_id means a power-seller with millions of orders concentrates on one shard (hotspot risk), and queries like "all orders in the last hour across users" now scatter. There is no free lunch — you optimize the partition key for your dominant access pattern and accept the others are expensive.
🤔 A request arrives for user_id=42. How does the system know WHICH shard holds it — and what breaks if you hardcode that mapping in every client?
Reveal the reasoning
How routing works (three common approaches):
- Client-side / library: each client computes
hash(42)→sharditself. Fast (zero hops) but every client embeds the topology → adding a shard means redeploying all clients in lockstep. - Routing tier / proxy (e.g. a coordinator): client asks the proxy, proxy holds the shard map and forwards. One extra network hop (~1 ms) but topology lives in one place → add a shard without touching clients.
- Lookup table / directory service: a service stores key→shard explicitly. Most flexible (arbitrary placement, easy to move a single hot key) but the directory is a lookup on every request and a single point of failure → must itself be replicated.
What breaks with hardcoded mappings: the topology changes the moment you rebalance, so a hardcoded map goes stale → requests route to the wrong shard and return wrong/missing data. The proxy and directory approaches win precisely because they let you change the map in one place.
The deeper rebalancing cost + how it's tamed: moving partitions is never free — during a move a key has two homes (old and new), so you must keep serving reads/writes from the old shard while copying to the new one, then cut over atomically and update the shard map last. Real systems avoid splitting the difference per-key by pre-allocating a fixed large number of logical partitions (far more than nodes) and only ever reassigning whole partitions to nodes (the Kafka/Cassandra/Dynamo pattern) → rebalancing becomes "move N partitions," never "re-hash every key." Trade-off: you must pick the partition count up front (too few caps your max node count; too many adds metadata and coordination overhead), and you trade simple mod N math for a managed shard map you have to keep consistent and highly available.
📐 Architecture diagrams (4)
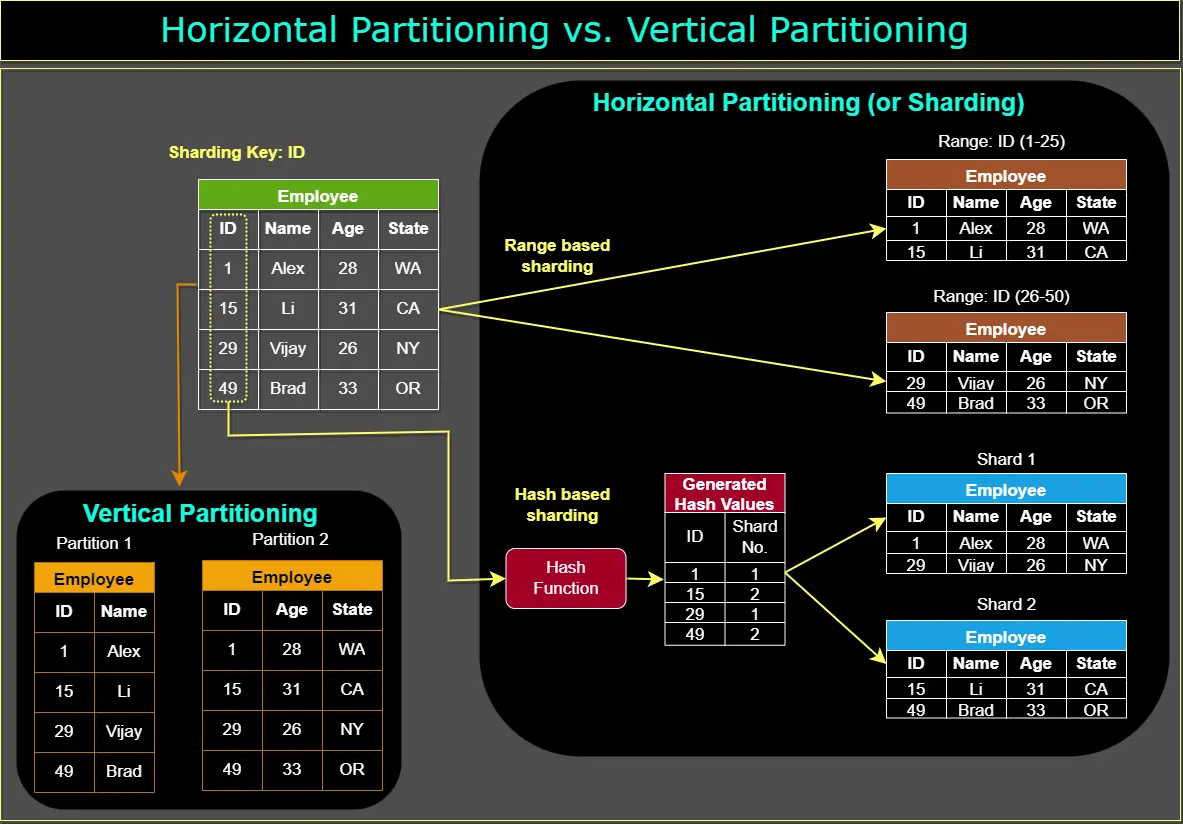
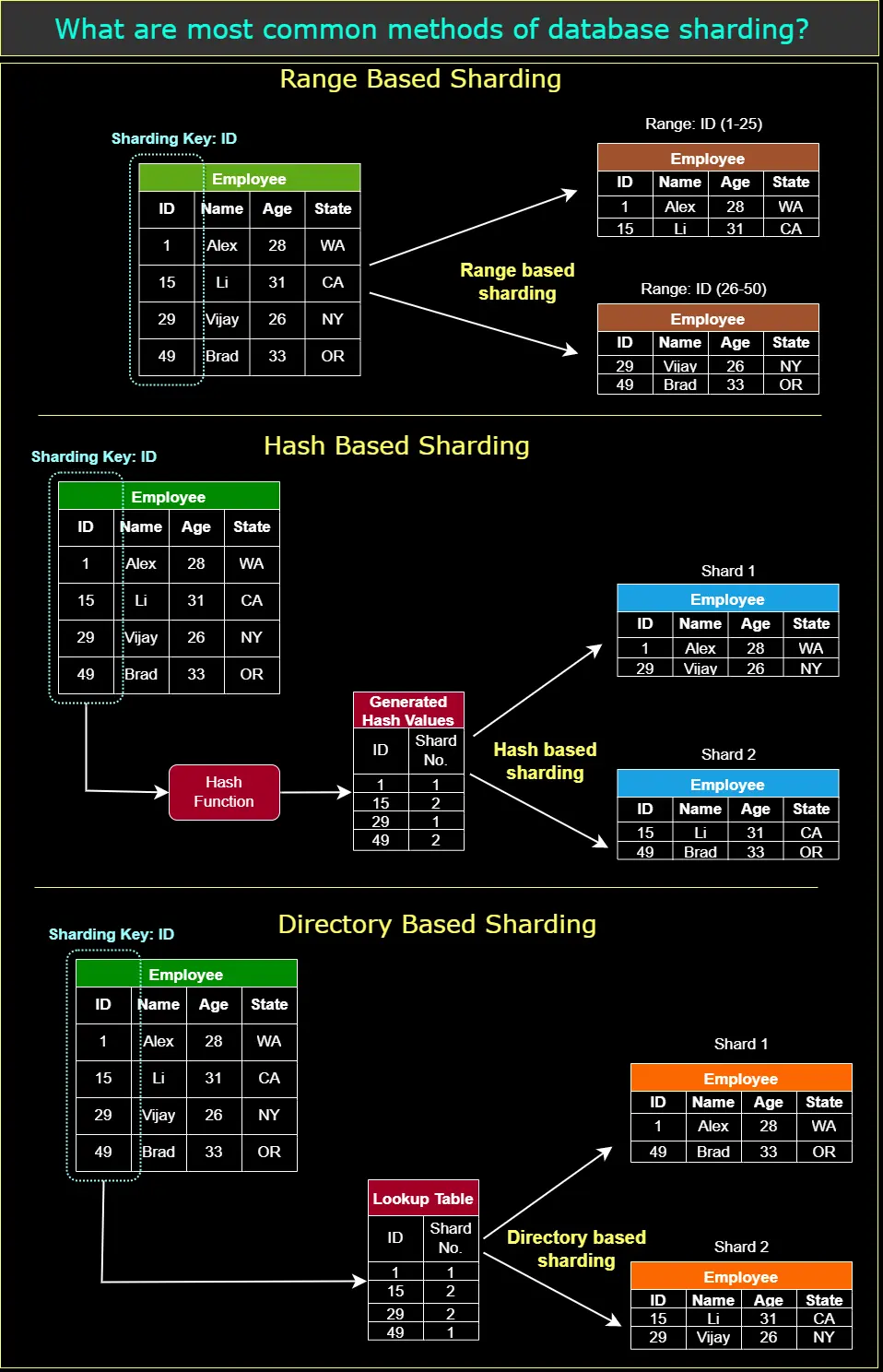


🎯 Guided practice
- Easy — pick the shard key. A chat app stores
messages(message_id, chat_id, sender_id, body, ts). The hottest query is "load the last 50 messages for a chat." Which column is the shard key? Reasoning: (1) Find the key in the hot query's filter — it'sWHERE chat_id = ?. (2) Sharding bychat_idco-locates every message of a conversation on one shard, so loading a chat is a single-shard query, not a scatter-gather. (3) Sharding bymessage_idinstead would scatter one chat's messages across all shards — wrong. (4) Within the shard, makets(or a time-orderedmessage_id) the clustering/sort key so "last 50" is a cheap reverse range scan, not a full read-and-sort of the chat. Pattern: the shard key is the entity your hottest reads filter on; co-locate data read together, and order it by the dimension your reads page over. - Medium — diagnose the hotspot and match the fix to the load type. A social platform shards posts by
user_id. One celebrity has 50M followers; their shard is melting under read load while others idle. Diagnose and fix. Reasoning: (1) Identify the problem: skewed/hot key (the "celebrity problem") — hash sharding balances key counts, not per-key load, so one heavy key still lands wholly on one shard; range sharding doesn't help a single hot entity either. (2) Classify the load: this is read-hot (millions reading one entity's posts), not write-hot. The fix depends on which. (3) For read-hot (this case): front the hot shard with a cache (celebrity reads are highly repetitive, so a high hit rate offloads the shard) and add read replicas for that shard; at the feed layer, switch celebrities to fan-out-on-read (merge their posts in at query time) instead of fanning out to 50M follower timelines. (4) For write-hot keys, the right tool is instead salting / sub-sharding — append a suffix (celebrity_id:bucket_0..N) to spread writes across shards. (5) Use consistent hashing so any rebalancing moves ~1/N of keys, not all of them. Pattern: uniform key distribution ≠ uniform load — detect skew, then pick the mitigation by load shape: cache + replicas (+ fan-out-on-read) for hot reads, salt/sub-shard for hot writes.
✨ Added by the guide — work these before the full problem set.