Load Balancing
Step 5 in the System Design path · 8 concepts · 0 problems
📘 Learn Load Balancing from zero
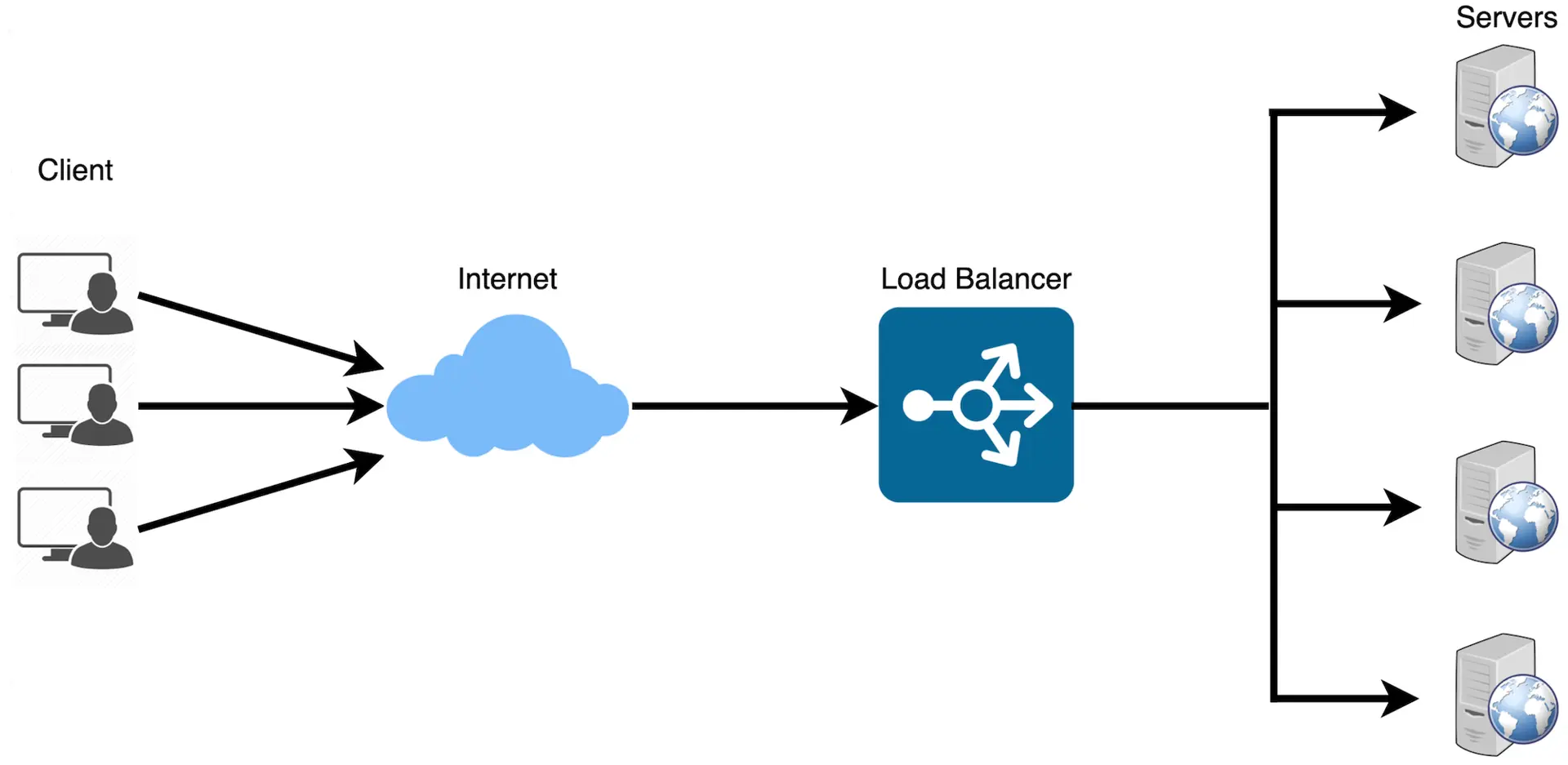
A load balancer sits in front of a pool of servers and spreads incoming requests across them, so no single machine becomes a bottleneck. In an interview it shows up the moment you say "we'll run multiple application servers" — the interviewer expects you to explain HOW traffic reaches them, how you avoid sending requests to a dead node, and what new problems the LB itself introduces (it becomes a single point of failure, it has to track health, it has to decide where state lives). Knowing the mechanism, the algorithms, and the trade-offs lets you justify your topology instead of just drawing a box labeled "LB".✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○Introduction to Load Balancing
- ○Load Balancing Algorithms
- ○Uses of Load Balancing
- ○Load Balancer Types
- ○Stateless vs Stateful Load Balancing
- ○High Availability and Fault Tolerance
- ○Scalability and Performance
- ○Challenges of Load Balancers
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 One app server handles 1,000 requests/sec but your traffic just hit 5,000 req/sec. You add 4 more identical servers. What breaks if clients still point at one IP, and what does the LB actually solve?
Reveal the reasoning
Cause → effect chain:
- Clients resolve
api.example.comto ONE IP, so all 5,000 req/sec still hit server #1 → it saturates at 1,000 → ~80% of requests queue or get 503s, while servers #2–#5 sit idle at 0% CPU. - Insert an LB as the single public endpoint. Clients hit the LB; it forwards each request to one of the 5 backends → ~1,000 req/sec each → all servers run near capacity, total throughput ≈ 5,000 req/sec.
- Bonus effects: the LB can stop routing to a crashed server (availability) and you can add/remove backends without changing the client-facing IP (elastic scaling).
Cost it introduces: the LB is now in the critical path of EVERY request. If it dies, all 5 healthy servers become unreachable — you've concentrated risk into one component (addressed in the HA step).
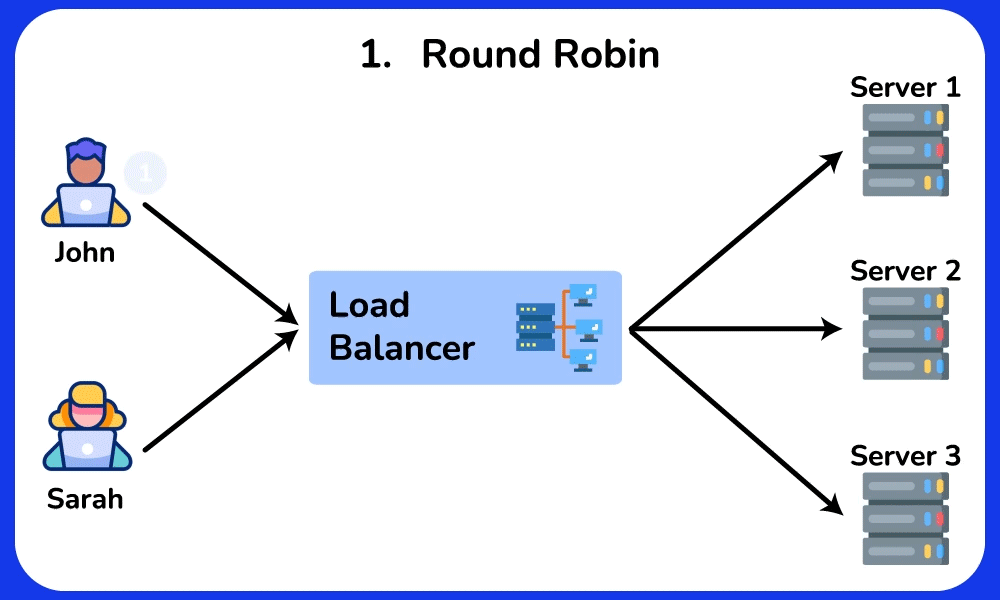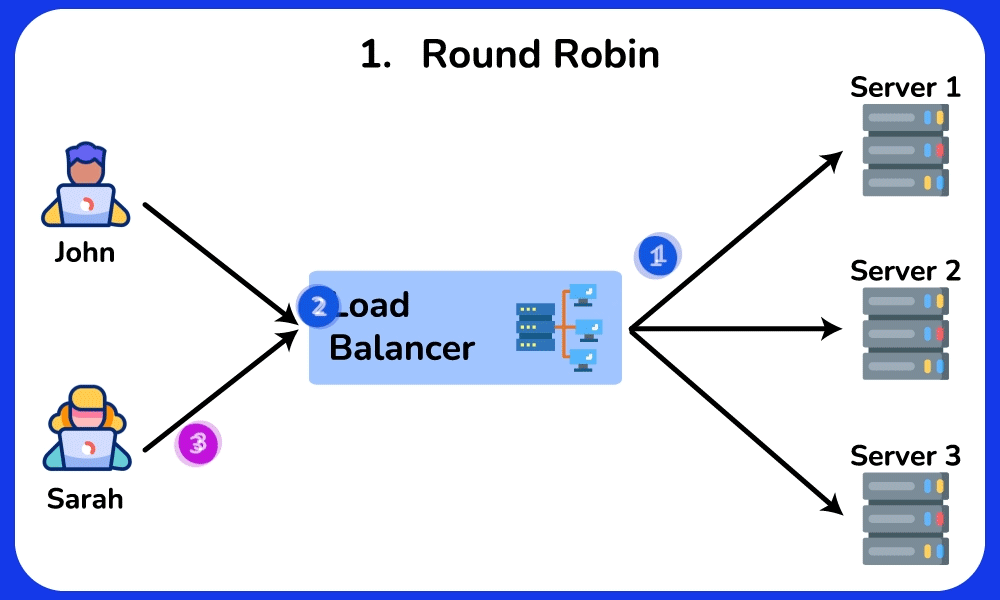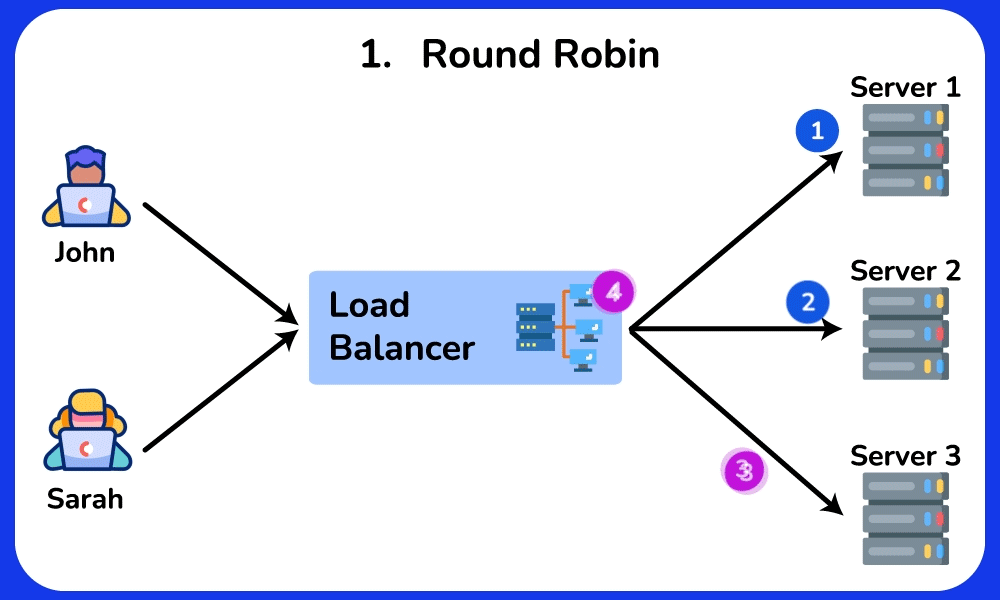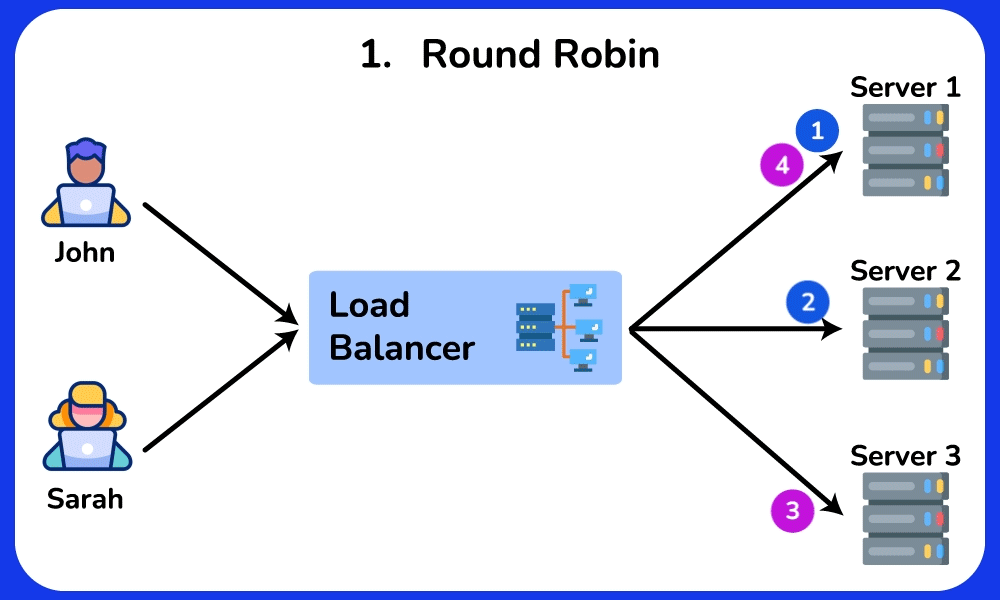
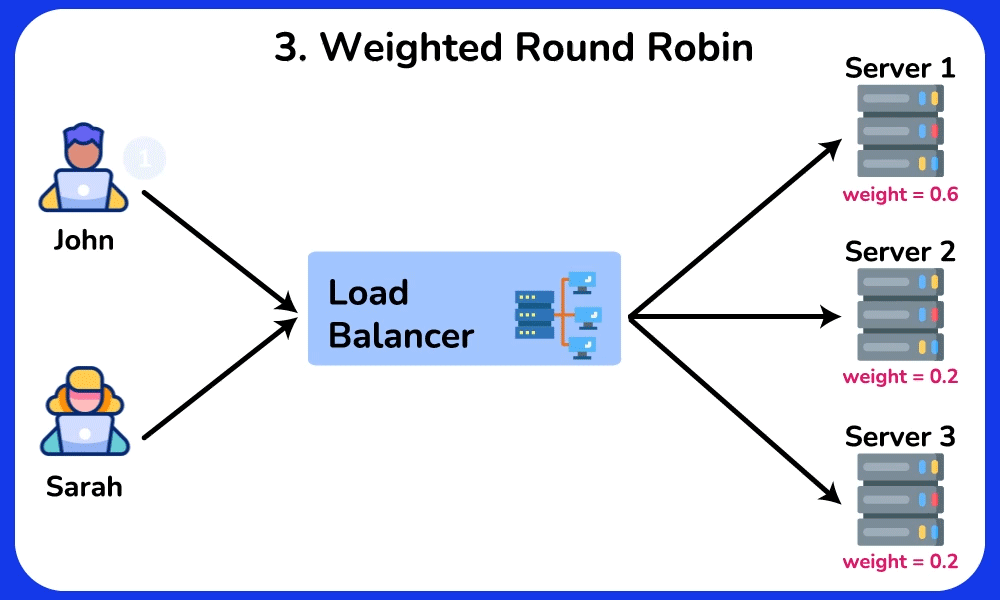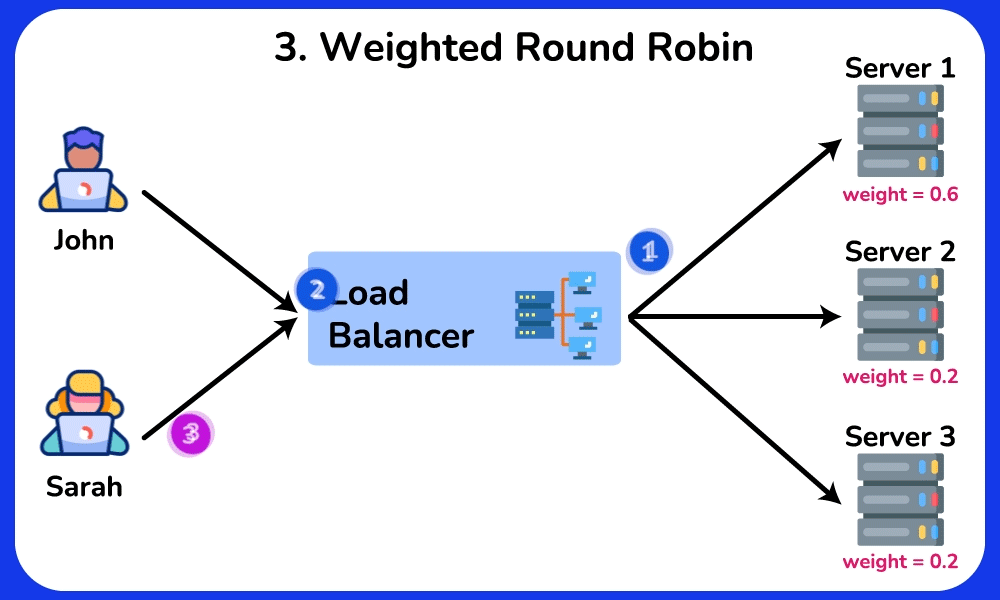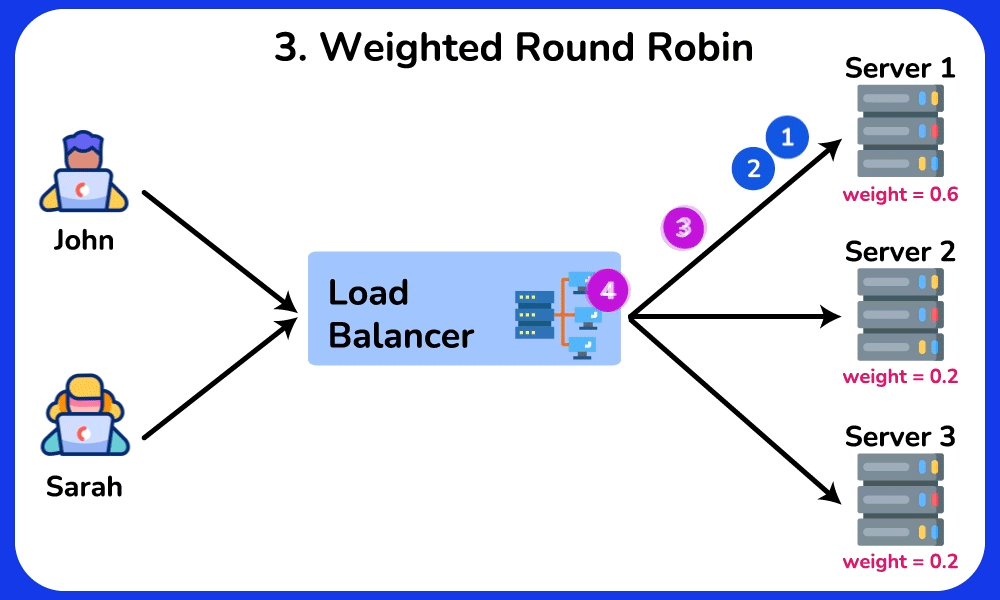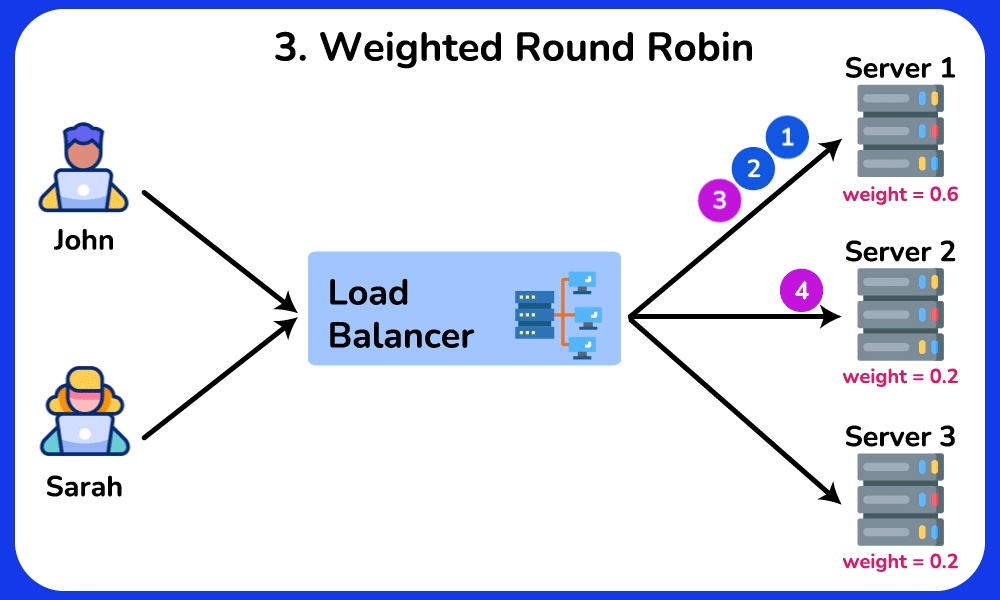
🤔 5 backends, requests arriving. The simplest rule is Round Robin (server 1, 2, 3, 4, 5, 1, 2…). Two of your servers are old and half as fast. What goes wrong, and which algorithm fixes it?
Reveal the reasoning
Cause → effect chain:
- Round Robin gives each server the same SHARE (1/5 = 20%) regardless of capacity → the two slow servers each get 20% of traffic but can only sustain ~10% → their request queues grow → their p99 latency spikes to seconds while the fast servers idle.
- Weighted Round Robin: give the 3 fast servers weight 2 and the 2 slow ones weight 1 (2+2+2+1+1 = 8 shares) → each fast server gets 2/8 = 25%, each slow one gets 1/8 = 12.5% → load matches capacity, queues stay flat.
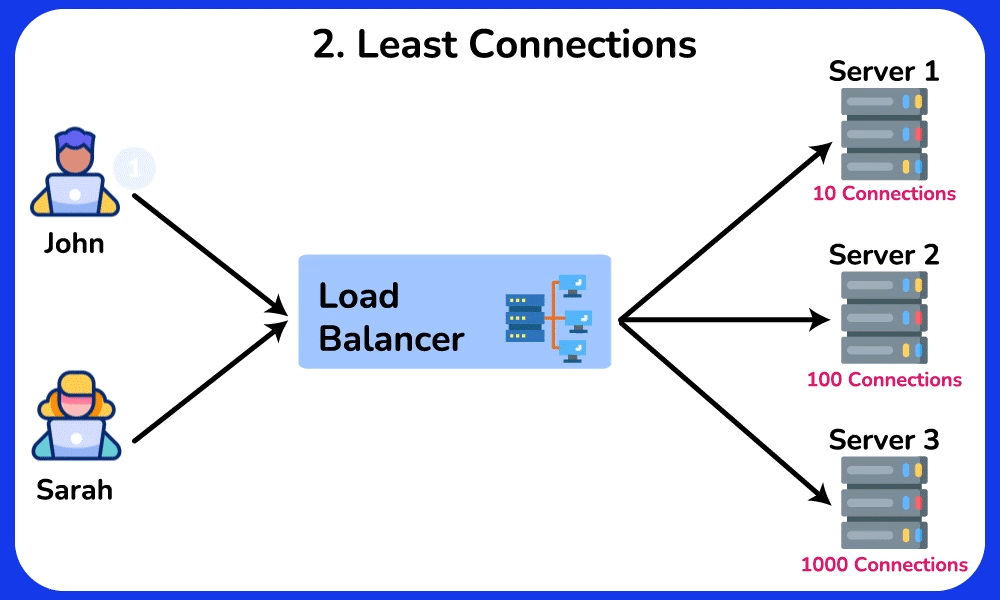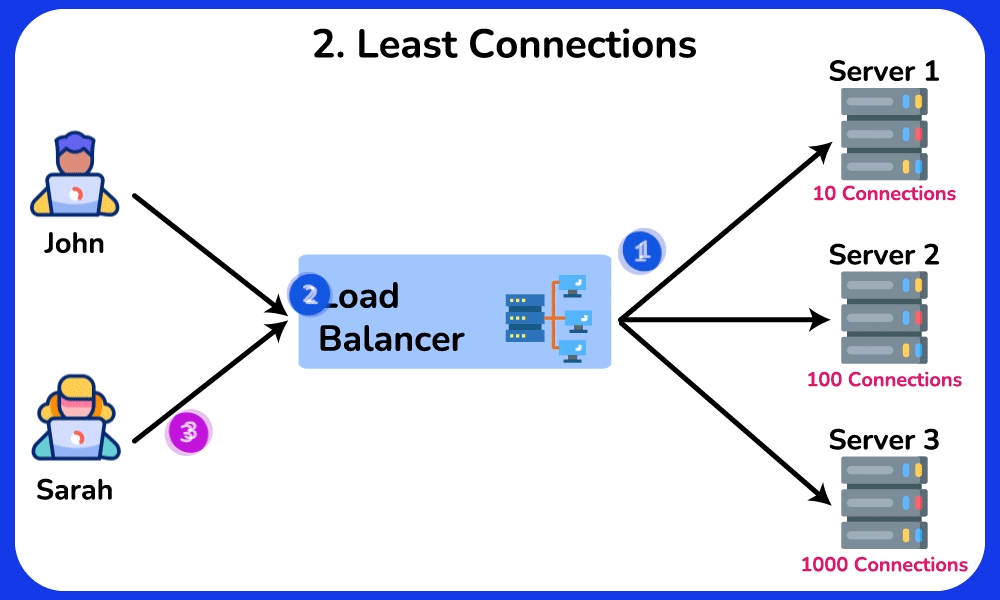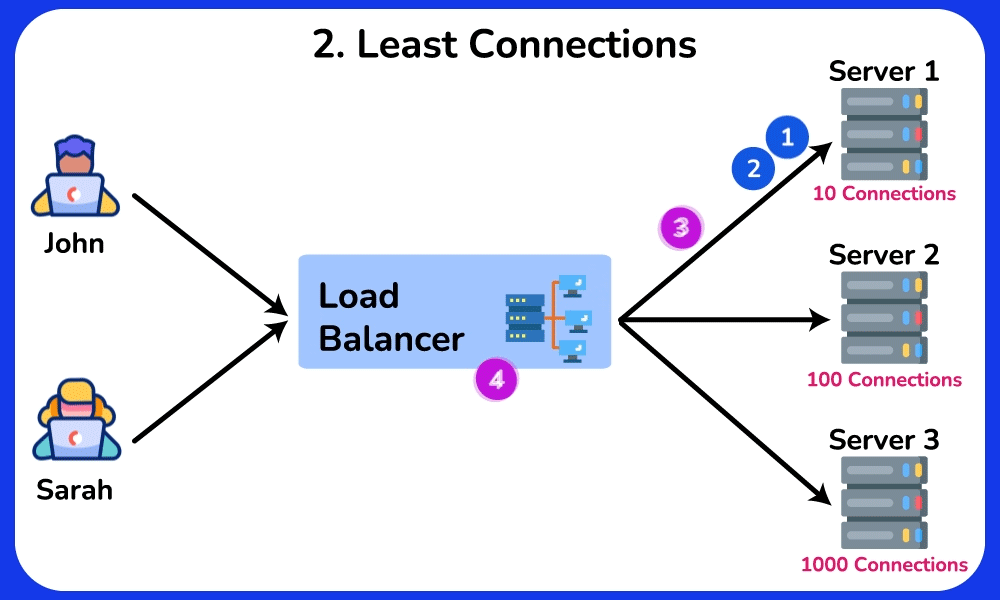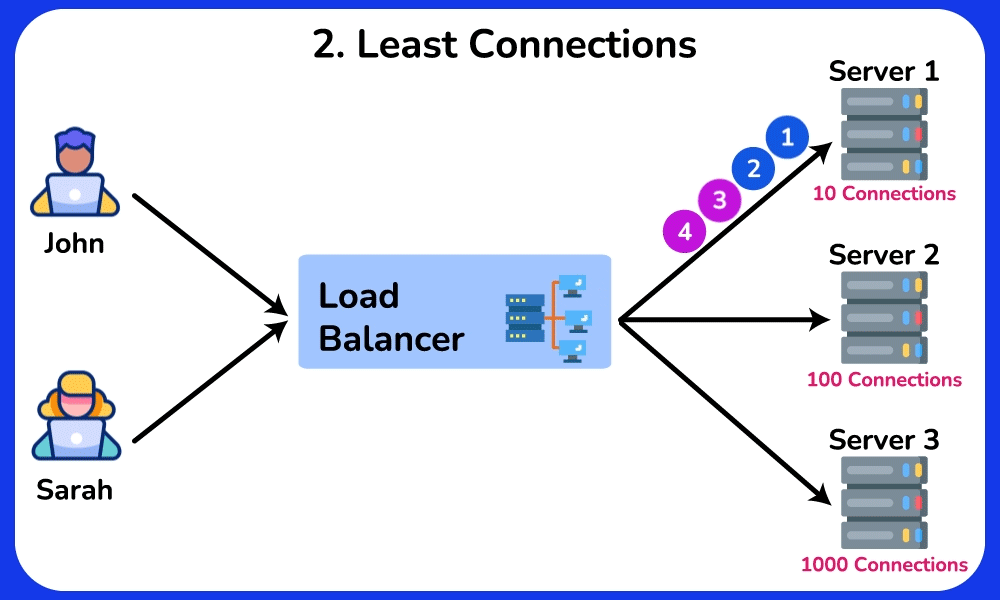
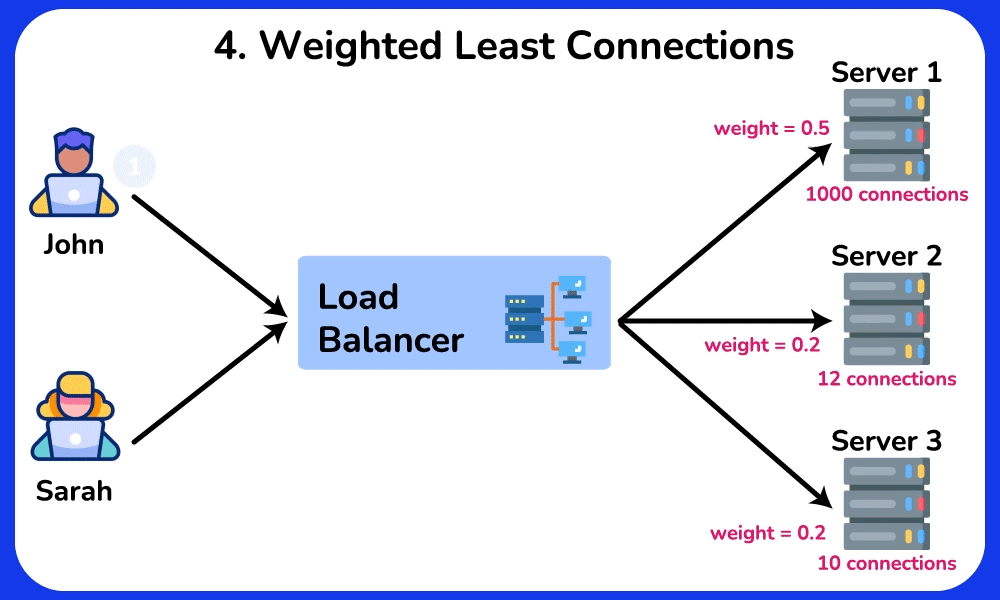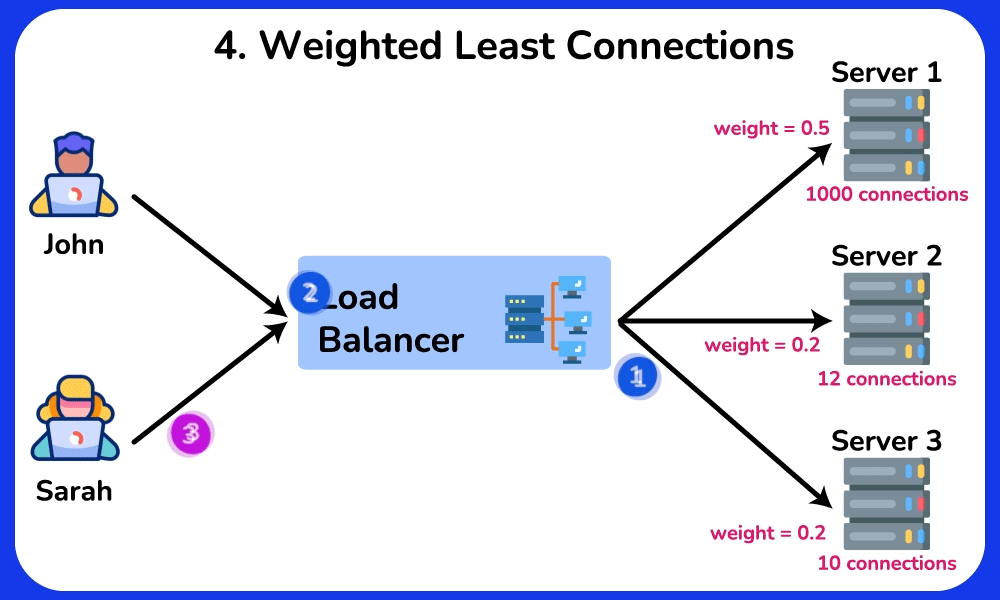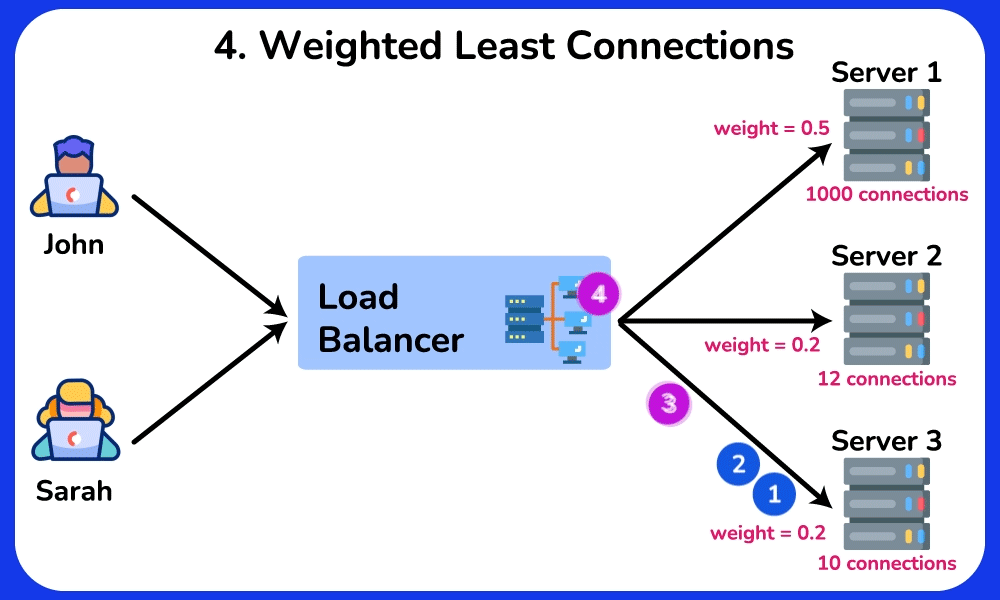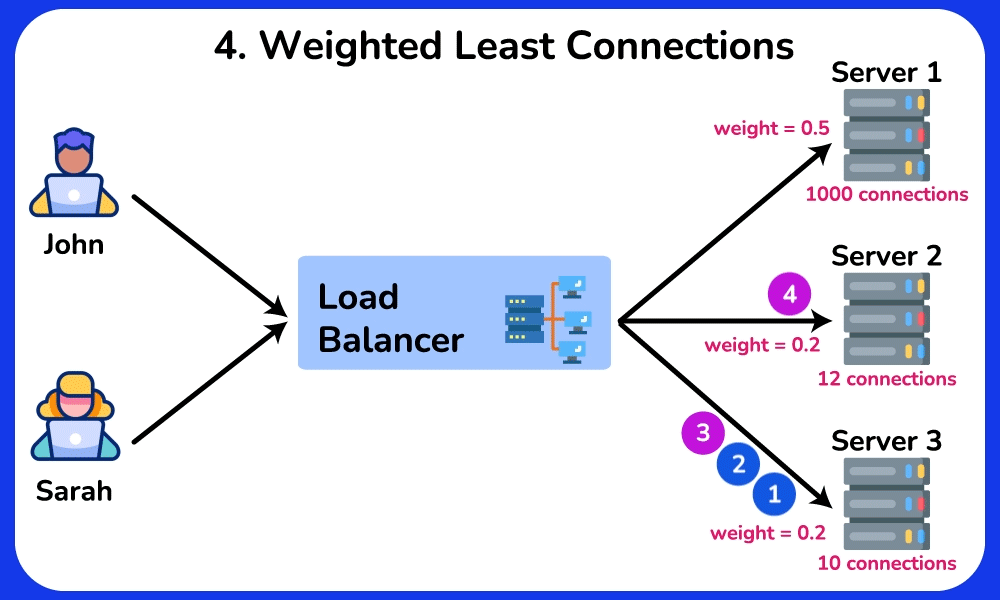
- Least Connections: route to whichever backend has the fewest in-flight requests → naturally drains away from a slow/stuck server because its open-connection count stays high. Best when request durations vary a lot (e.g. some take 5ms, some take 5s), where Round Robin's equal-count assumption breaks.
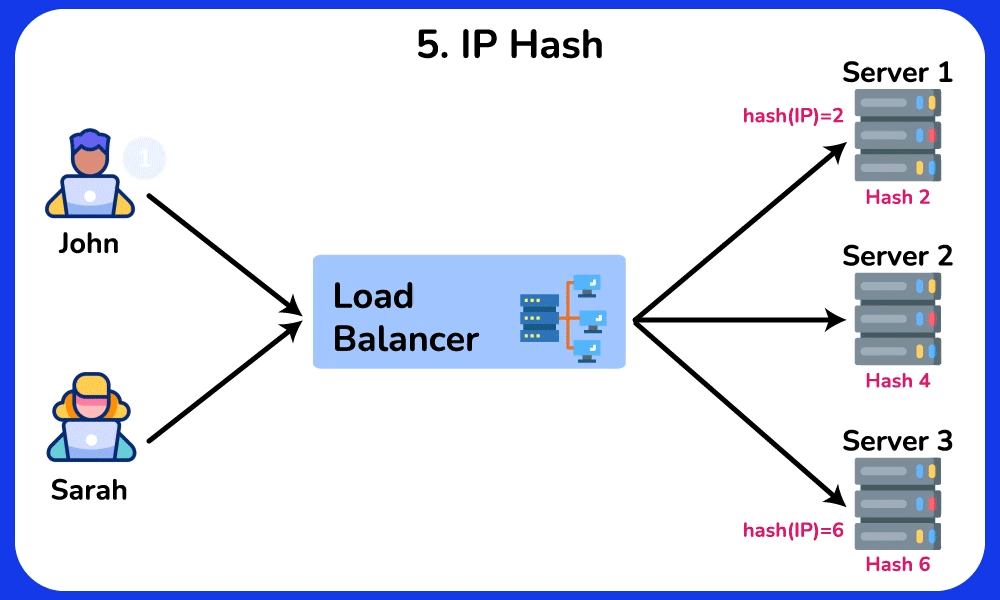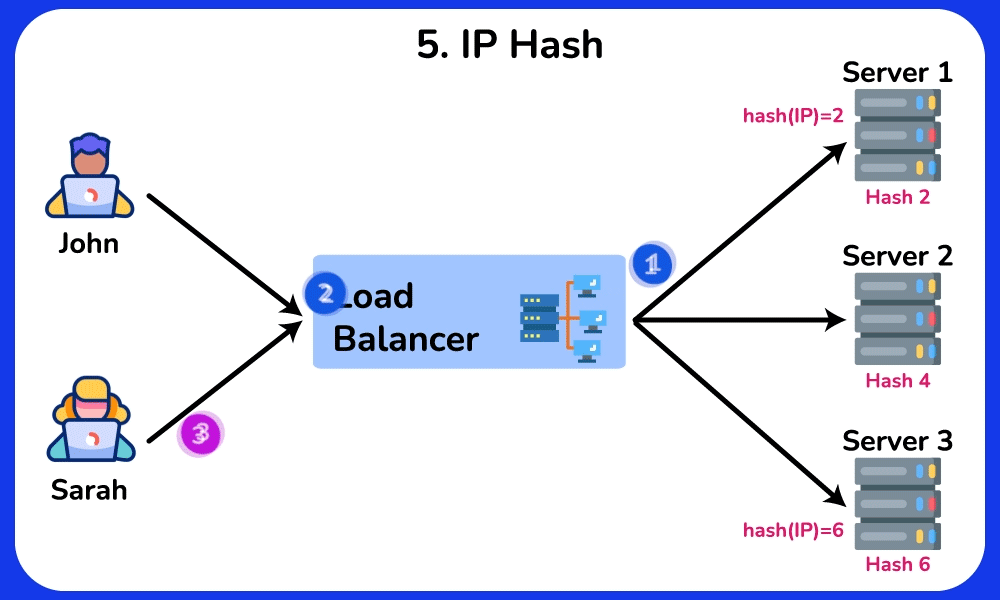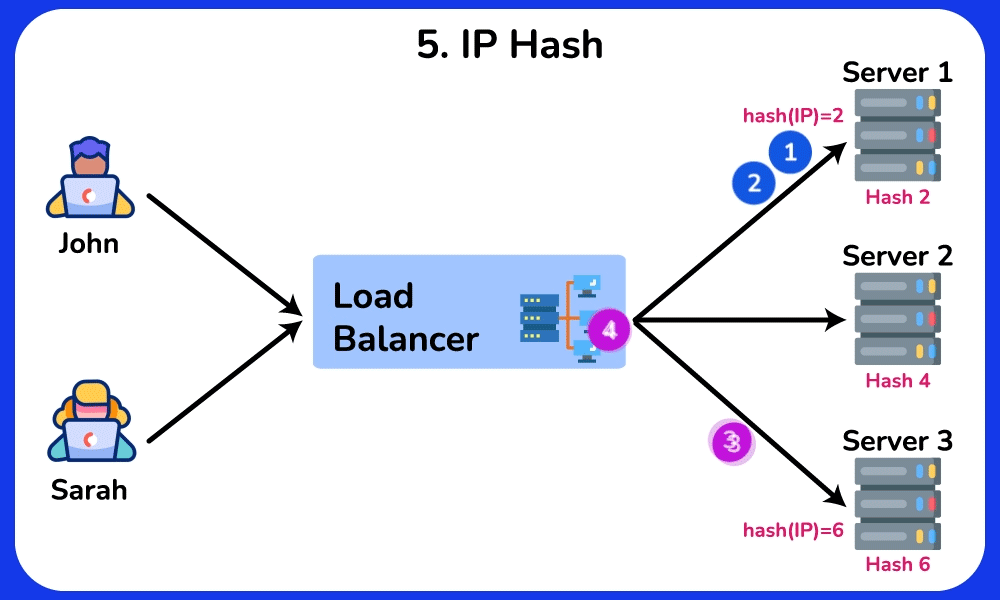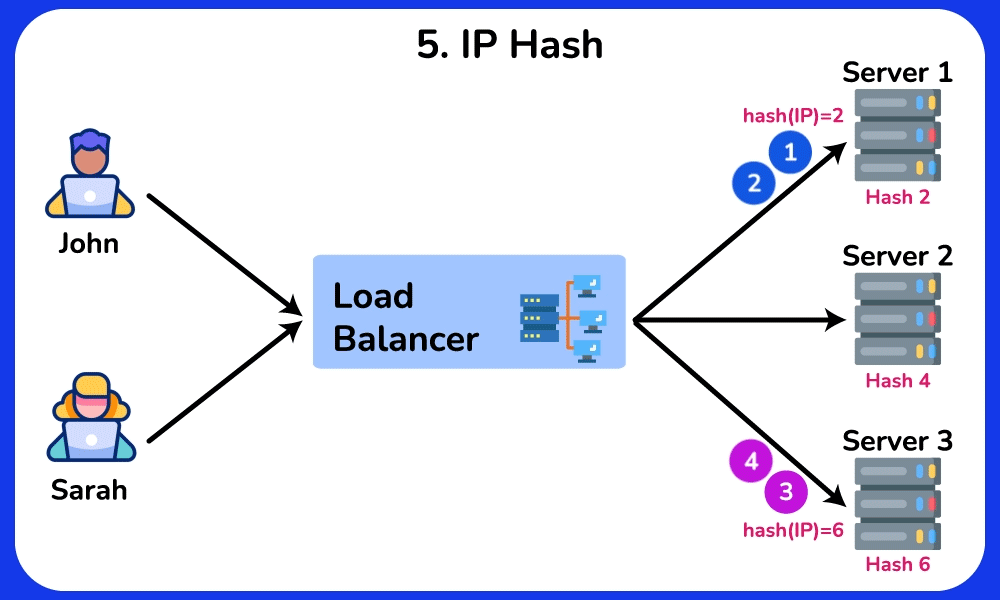
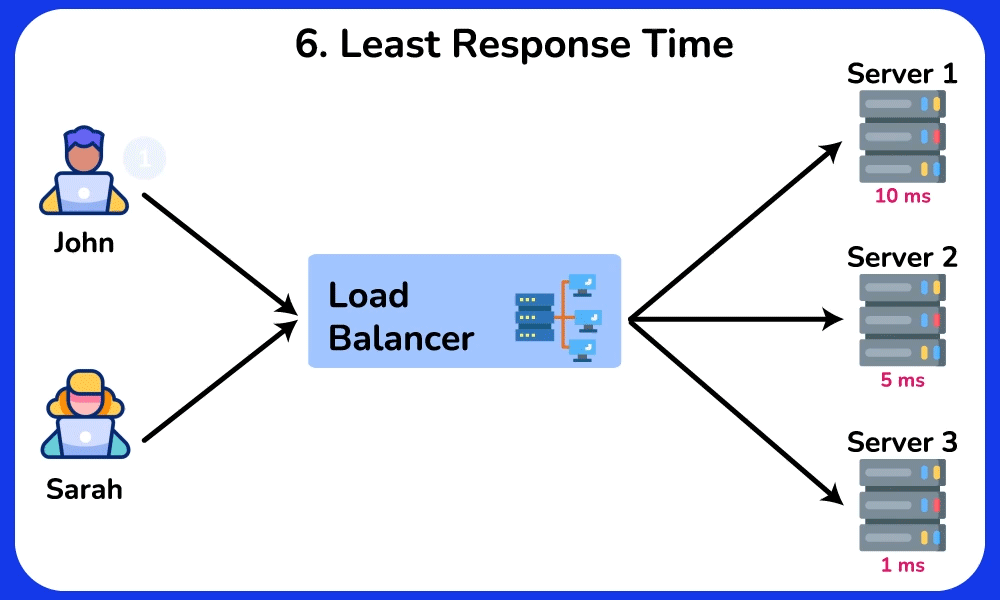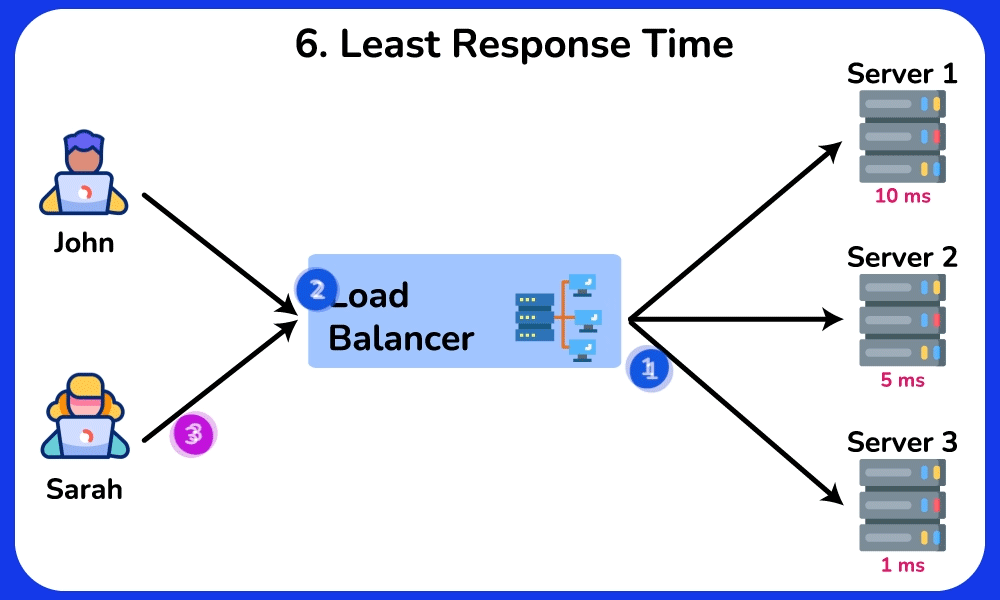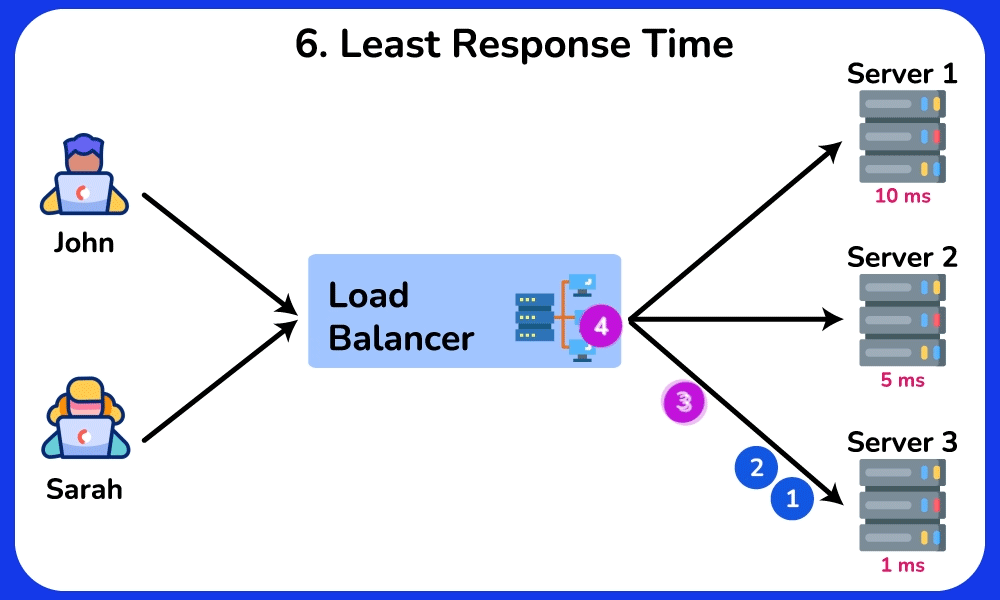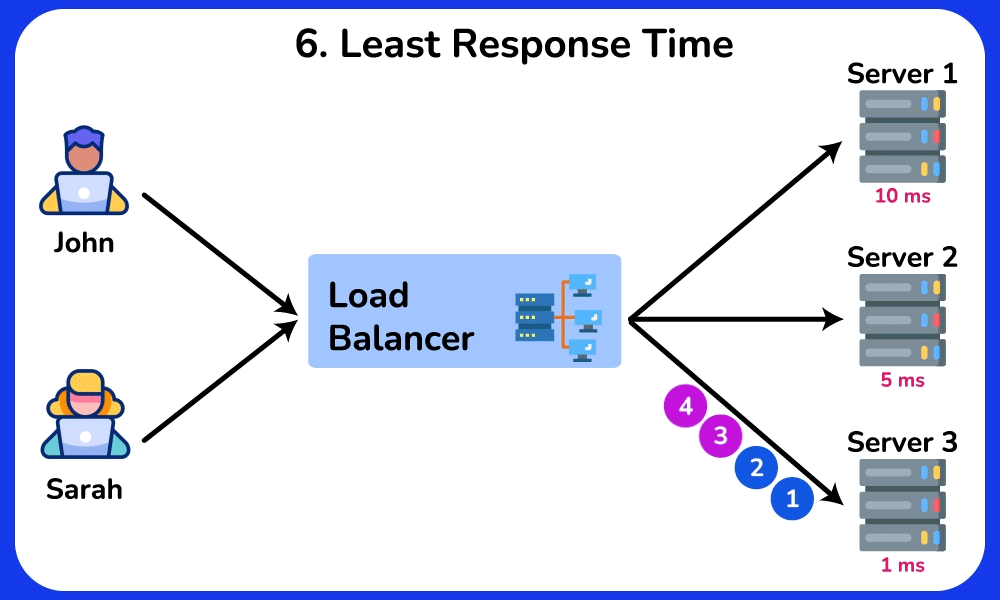
- Least Response Time / Consistent Hash: least-response-time favors the node with the lowest observed latency (often blended with connection count); consistent hashing on a key (e.g. user ID) pins a user to the same backend even as nodes are added/removed.
Cost/trade-off: Round Robin is stateless and trivially cheap — any LB replica can compute it independently. Least-Connections and Least-Response-Time require the LB to track live per-backend state → more memory/CPU on the LB, and that state must be shared or approximated across LB replicas, so the LB tier is harder to scale out.
🤔 You want to send all /video/* requests to a GPU-heavy pool and everything else to a cheap pool. A Layer-4 (TCP) load balancer can't do that. Why not, and what does Layer-7 cost you to gain it?
Reveal the reasoning
Cause → effect chain:
- An L4 LB only sees TCP/IP headers — source/dest IP and port. It forwards segments without reading the payload → it never sees the URL path
/video/...(which lives inside the encrypted HTTP body) → it physically cannot route on it. But because it just shuffles packets, it's extremely fast (millions of packets/sec, microsecond overhead) and protocol-agnostic. - An L7 LB terminates the TCP connection, parses the full HTTP request → it can read the path, headers, and cookies → it routes
/video/*to the GPU pool, does TLS termination, sets sticky-session cookies, and can retry an idempotent request against another backend if one fails. - To gain that, L7 must decrypt TLS and parse every request → higher CPU, higher per-request latency (tens to hundreds of µs more), and because it holds plaintext it's a security-sensitive component.
Rule of thumb: L4 when you need raw throughput and don't care about content (e.g. database or game traffic); L7 when you need content-based routing, TLS termination, or HTTP-aware features. Many real stacks layer both: an L4 tier spreads connections, with L7 proxies behind it for smart routing.
🤔 A user logs in; the session is stored in server #2's local memory. On their next request the LB (round robin) sends them to server #4 → they appear logged out. You have two fixes: sticky sessions or externalize state. Which scales, and why?
Reveal the reasoning
Cause → effect chain:
- Sticky sessions (state stays on the backend): the LB pins each user to the same backend via a cookie or source-IP hash → the user always returns to server #2 → session found. BUT: if server #2 crashes, every user pinned to it loses their session AND that traffic must rebalance — the other 4 servers suddenly absorb #2's whole share. Stickiness also defeats even distribution: a few 'whale' users hashed to one node can hot-spot it.
- Stateless backends + external session store: servers keep sessions in a shared Redis/DB, not local memory → any backend can serve any request → the LB can use pure round-robin/least-connections, you can add or remove backends freely, and a crashed node loses zero sessions (they're in Redis).
Cost/trade-off: externalizing adds a network round trip to Redis (~0.5–1ms) and a new dependency that must itself be made highly available. But it's the pattern that actually scales horizontally — sticky sessions are a quick patch that fights both load distribution and fault tolerance. Preferred interview answer: keep backends stateless, push session state to a shared store.
🤔 Server #3 hangs — it still accepts TCP connections but every HTTP request times out after 30s. A naive LB keeps sending it 20% of traffic. How does a health check detect this, and what's the danger of checking too aggressively or too leniently?
Reveal the reasoning
Cause → effect chain:
- Passive / TCP-connect only: #3 still completes the TCP handshake → the LB thinks it's healthy → 20% of users hit a 30s timeout. Not enough.
- Active health checks: the LB sends
GET /healthzevery 5s and expects a 200 within, say, 2s. #3 returns a timeout/500 → after N consecutive failures (e.g. 3) the LB marks it unhealthy and stops routing → in the worst case those users get rerouted to the 4 healthy nodes within ~15s (3 × 5s) of the hang starting. - Re-add on recovery: the LB keeps probing; after M consecutive 200s it returns #3 to rotation (hysteresis prevents flapping).
Cost/trade-off — tuning is a balance:
- Too aggressive (interval 1s, threshold 1 fail): a single GC pause or network blip ejects a healthy node → it flaps in and out, and during a brief shared slowdown you can eject so many nodes that the survivors get overloaded and ALSO start failing — a cascading failure.
- Too lenient (interval 30s, threshold 5): up to 30s × 5 = 150s (2.5 min) of sending traffic to a dead node before ejection.
- The
/healthzendpoint must check real dependencies (can it reach the DB?), or it returns 200 while the app is actually broken — a 'green but dead' false negative.
🤔 You've made the backends resilient, but now ALL traffic flows through one LB box. It reboots for a kernel patch → 100% outage for 90 seconds. The single LB is a single point of failure. How do you remove it?
Reveal the reasoning
Cause → effect chain:
- Active–passive pair: two LBs share a floating Virtual IP (VIP). The active one holds the VIP; the passive one heartbeats it. If active dies, the passive grabs the VIP (failover in ~1–3s, e.g. via VRRP/keepalived) → traffic continues with a brief blip instead of a 90s outage. Cost: the passive box sits idle (≈50% of LB capacity unused) and in-flight connections during failover are dropped/retried.
- Active–active: multiple LBs all serve traffic, fronted by DNS round-robin or anycast → losing one drops only its share (e.g. 1 of 3 ≈ 33% briefly, until traffic reconverges) and no capacity sits idle. Cost: more complex, and DNS-TTL caching means clients may keep hitting a dead LB IP until the TTL expires — so keep TTL low (e.g. 30–60s), and prefer health-aware routing over plain DNS round robin.
- Anycast / GSLB: the same IP is announced (via BGP) from multiple data centers; the network routes each client to the nearest live LB → a whole region can fail and traffic reroutes automatically as routes withdraw.
Key principle: 'high availability' means no single component — including the LB — can take everything down. You always want ≥2 LBs with automatic failover.
🤔 Your single LB box maxes out at 100,000 connections/sec, but you now need 1,000,000. You can't keep buying a bigger box. How do you scale the load-balancing TIER itself, and what new problem appears once there are many LB nodes?
Reveal the reasoning
Cause → effect chain:
- Scale up first (cheap, has a ceiling): bigger NIC, more CPU, kernel-bypass (DPDK/XDP) → one box might reach a few hundred K conn/sec. But there's a hard limit, and a single box is still a SPOF — so this only buys time.
- Scale out the data plane with ECMP: run many identical L4 LB instances that all advertise the SAME virtual IP via BGP. Upstream routers use Equal-Cost Multi-Path routing to hash each packet's 5-tuple (src/dst IP+port, protocol) across the LB instances → ~1,000,000 conn/sec spread over, say, 10–20 nodes, with no single box in the critical path. Adding an LB node just adds another ECMP next-hop.
- New problem — connection stickiness: ECMP hashing alone breaks when the LB set changes (add/remove a node re-hashes flows, snapping live TCP connections to a different LB that has no state for them). Fix: each LB uses consistent hashing to map a connection to a backend, so any LB node picks the same backend for the same flow → connections survive LB churn (this is the Maglev/Katran design).
- Direct Server Return (DSR): backends reply straight to the client, bypassing the LB on the return path → the LB only handles inbound packets (usually the small half of the traffic), so the tier scales much further on the same hardware.
Cost/trade-off: this tier is far more complex (BGP, consistent-hash tables, DSR networking, kernel-bypass) and is mostly L4 — content-based L7 routing happens in a proxy layer behind it. You pay operational complexity to get near-linear horizontal scale and no SPOF. The escalation ladder: scale up → active-passive → ECMP/anycast active-active with consistent hashing + DSR.
📐 Architecture diagrams (8)

🎯 Guided practice
- Easy — pick the algorithm. You have 3 identical stateless API servers and a flood of short, uniform requests (each ~5ms, no session). Which algorithm? Reasoning: (1) Identical servers means no weighting needed. (2) Stateless + uniform cost means every request is interchangeable, so there is no value in tracking per-server load. (3) Round robin cycles 1→2→3→1… giving each server an equal share at O(1) cost with no state to maintain. Answer: round robin. Now change one fact — requests are long-lived WebSocket connections of wildly different durations. Round robin counts each connection equally even though some hold a server for hours, so real load drifts uneven. Switch to least connections (or least response time): route each new connection to the server with the fewest active connections, which tracks actual load. Core pattern: match the algorithm to whether request cost is uniform (round robin) or skewed/long-lived (least connections / least response time), and whether you need locality/affinity (consistent hashing).
- Medium — kill the single point of failure and the sticky-session trap. Design: clients → LB → 4 servers, sessions stored in server memory with sticky sessions (a cookie pins each user to one server). Two problems are hidden here — find and fix both. Step 1, the LB itself: a single LB means if it dies, the whole site is down — the LB is now the single point of failure. Fix: run two LBs in active-passive sharing a floating/virtual IP; if the active one misses its heartbeat, the passive takes over the VIP (failover, e.g. via VRRP/keepalived). For more throughput, go active-active with both serving traffic, typically fronted by DNS. Step 2, sticky sessions: they pin a user to one server, so if that server dies the user loses their cart/login, and you cannot drain, rebalance, or scale down without disrupting pinned users. Fix: make servers stateless by moving session data to an external store (e.g., Redis). Now any server can serve any user, so the LB is free to use plain round robin or least connections, a server failure costs no user state, and you scale horizontally without affinity. Takeaway: high availability requires redundancy at every tier — including the LB — and statelessness is what makes a server pool truly elastic and fault-tolerant: push state out of the servers.
✨ Added by the guide — work these before the full problem set.