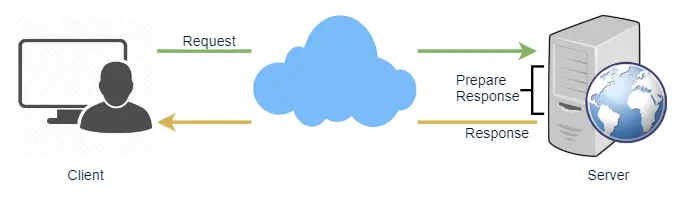
System Design Trade-offs
Step 26 in the System Design path · 24 concepts · 0 problems
📘 Learn System Design Trade-offs from zero
System design interviews aren't about reciting components — they're about defending trade-offs out loud. Every choice (cache, replica, queue, gateway, consistency model) buys you one property at the cost of another, and the interviewer is listening for whether you know the cost you just signed up for. This walkthrough drills the building-block mechanisms — how each one actually works, when to reach for it, and the bill it sends you. Treat each step like the interviewer asking "why?": think first, then check.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○Functional vs Nonfunctional Requirements
- ○SQL vs NoSQL
- ○LongPolling vs WebSockets vs ServerSent Events
- ○Strong vs Eventual Consistency
- ○Latency vs Throughput
- ○ACID vs BASE Properties in Databases
- ○ReadThrough vs WriteThrough Cache
- ○Batch Processing vs Stream Processing
- ○Load Balancer vs API Gateway
- ○API Gateway vs Direct Service Exposure
- ○Proxy vs Reverse Proxy
- ○API Gateway vs Reverse Proxy
- ○SQL vs NoSQL (2)
- ○PrimaryReplica vs PeertoPeer Replication
- ○Data Compression vs Data Deduplication
- ○ServerSide Caching vs ClientSide Caching
- ○REST vs RPC
- ○Polling vs LongPolling vs WebSockets vs Webhooks
- ○CDN Usage vs Direct Server Serving
- ○Serverless Architecture vs Traditional Serverbased
- ○Stateful vs Stateless Architecture
- ○Hybrid Cloud Storage vs AllCloud Storage
- ○Token Bucket vs Leaky Bucket
- ○Read Heavy vs Write Heavy System
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 You're asked to design Twitter. Before drawing a single box, what TWO categories of requirements must you pin down, and why does skipping one sink the design?
Reveal the reasoning
Functional = WHAT it does (post tweet, follow user, load timeline). Non-functional = HOW WELL (latency, availability, scale).
- Functional defines the API surface → you can't size anything without it.
- Non-functional drives every trade-off →
p99 < 200ms+99.99%uptime +500Mreads/day forces caching, replication, and CDN.
Cause→effect: state 200M DAU, 100:1 read:write → that single number tells you it's read-heavy → you justify caching + read replicas later. Cost: time spent here is time NOT drawing; under-spending here means you over-engineer the wrong axis (e.g. sharding writes when the pain is reads).
🤔 Your data is user profiles + their tweets + follower edges. One engineer says "just use Postgres," another says "Cassandra scales better." What property of YOUR data decides it, not the buzzword?
Reveal the reasoning
Decide by access pattern + relational need, not popularity.
- SQL (Postgres/MySQL): strong schema, multi-row
ACIDtransactions, ad-hoc joins. Single primary caps writes at roughly5k–20k writes/sec. - NoSQL wide-column (Cassandra/DynamoDB): denormalized, partition-key access, horizontal writes to
100k+/sec, but joins/transactions are weak.
Cause→effect: timeline = "give me last 50 tweets for a key" → single-partition lookup → NoSQL is a clean fit. Billing/payments = needs ACID → SQL. Cost of NoSQL: you denormalize, so one logical update fans out to many rows you must keep in sync in app code — no foreign keys to save you.
🤔 Adding a batch step takes one request from 50ms to 300ms but lets the system handle 10x more requests/sec. Did you improve performance — and which word in the SLA tells you whether that's acceptable?
Reveal the reasoning
They're orthogonal. Latency = time for ONE request. Throughput = requests/sec across all.
- Batching
100writes into one disk flush: each waits longer (+250mslatency) but you do10kinstead of1kops/sec (throughput up). - The SLA word decides: if it says
p99 latency < 200ms, the batch breaks it. If it sayshandle 10k req/s, the batch is the fix.
Cause→effect: pipelining/batching amortizes fixed per-op cost over many ops → throughput rises → but in-flight queuing → tail latency rises. Trade-off: on fixed hardware you generally trade one for the other; raising both at once means buying capacity, not free lunch. Name which one the user actually feels.
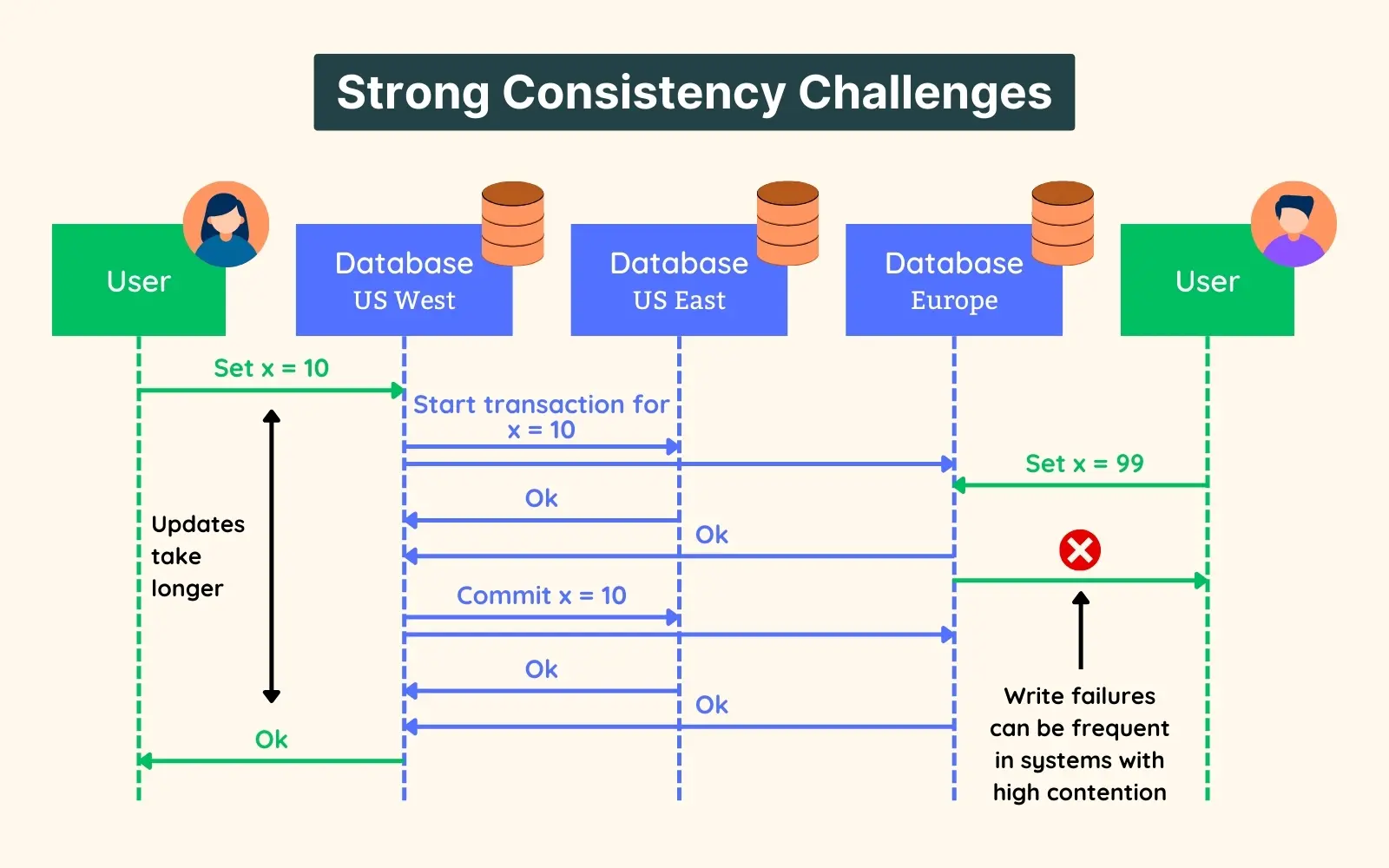
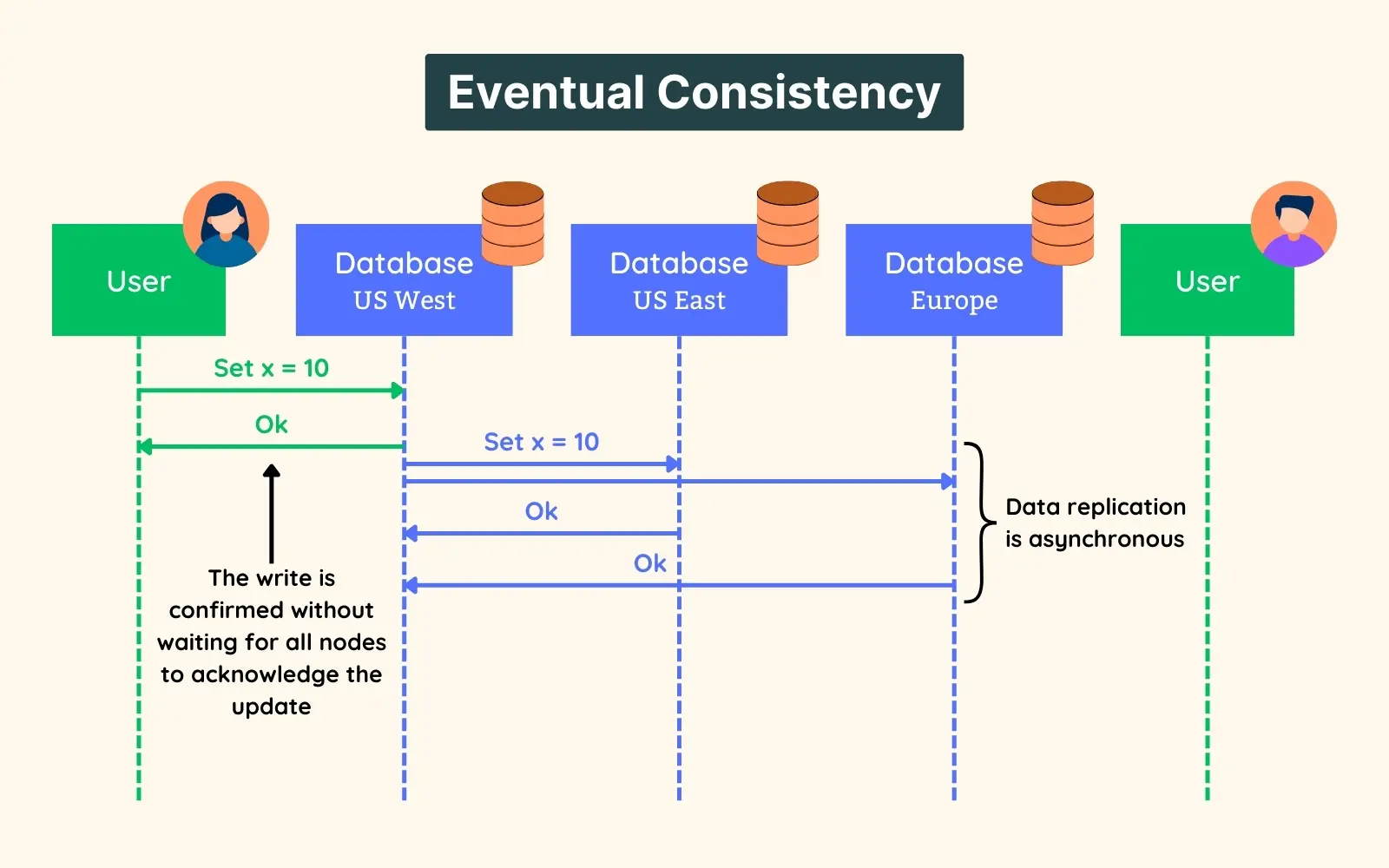
🤔 A user updates their profile photo. On a strongly consistent store every read after the write sees the new photo; on an eventually consistent one, some reads show the old one for a few hundred ms. Why would anyone CHOOSE the stale option?
Reveal the reasoning
Because consistency trades against availability + latency (CAP under partition / PACELC when there's no partition).
- Strong: the write must be acknowledged by a quorum/primary before reads see it → a cross-region read may pay
+80mscoordination, and if the primary is partitioned, writes BLOCK. - Eventual: any replica answers immediately (
~5mslocal) and converges in~10–500ms→ stays available during partitions.
Cause→effect: a profile photo being 200ms stale harms nobody → choose eventual for speed + uptime. A bank balance must be exact → choose strong, accept the latency and reduced availability. Cost of eventual: your app must tolerate reading its own stale writes ("read-your-writes" anomalies) unless you add sticky routing.
🤔 Your DB read is 40ms and you put a Redis cache in front at 1ms. With a 90% hit rate, what does the latency profile actually become — and what THREE new failure modes did you just sign up for?
Reveal the reasoning
Mechanism: cache serves hot keys from RAM, skipping disk + query planning.
- Mean read ≈
0.9×1ms + 0.1×40ms = 4.9ms. But the p99 isn't this average — it's dominated by the misses, so it still lands near the DB's own tail (~40ms+) unless the DB tail itself shrinks. - Why the tail also improves:
90%of traffic never reaches the DB → offered load drops → the DB's queue drains → even the10%misses wait less. So p99 falls, but because the DB got faster, not because 4.9ms is the p99.
Three costs you must name:
- Staleness/consistency: cache and DB disagree until TTL expires or you invalidate. Pick TTL by tolerance:
60sfor a feed,0(write-through) for a price. - Eviction: RAM is finite → LRU/LFU drops cold keys → a scan can blow the working set out and tank the hit rate.
- Stampede: a hot key expires → 10k requests miss simultaneously → they all hammer the DB at once. Fix with request coalescing / a short lock / probabilistic early refresh.
🤔 Two cache strategies: one populates the cache lazily on a miss, the other writes to cache and DB together on every write. A read-heavy feed vs a price-sensitive checkout — which gets which, and why?
Reveal the reasoning
- Read-through: on a miss, the cache loads from DB, stores it, returns it. First read of a key is slow (
40ms); all subsequent are fast (1ms). Cache only holds what's actually requested → small footprint. - Write-through: every write goes to cache AND DB synchronously → cache is never stale, but every write pays both latencies (
~5ms + ~40ms) and you cache data that may never be read.
Cause→effect: a feed is read 100:1 and tolerates seconds of staleness → read-through, let cold data stay out. A checkout price must never be wrong and is read right after write → write-through guarantees freshness. Cost: read-through risks serving stale until next load (and eats a cold-miss on first access); write-through wastes writes + RAM on rarely-read keys. (Write-back is faster still — ack the write from cache, flush to DB later — but risks data loss if the cache dies before flushing.)
🤔 Your single Postgres primary is at 80% CPU from read traffic. You add 3 read replicas. What problem does this fix, what problem does it NOT fix, and what weird bug will users report?
Reveal the reasoning
Mechanism (primary–replica): writes go to the primary, which streams its change log to replicas; reads fan out across replicas.
- Fixes reads: 1 primary + 3 replicas ≈ 4x read capacity → CPU drops, read p99 falls.
- Does NOT fix writes: every write still funnels through the one primary → write ceiling unchanged. For that you need sharding or peer-to-peer (multi-primary).
The bug: replication lag (10–500ms) → a user posts a comment (write→primary) then refreshes (read→replica that hasn't caught up) → "my comment vanished!" Fix with read-your-writes routing (send that user's reads to the primary briefly). Trade-off vs peer-to-peer: P2P/multi-primary lets any node take writes (higher write availability) but introduces write–write conflicts you must resolve (last-writer-wins, vector clocks) — primary–replica avoids conflicts but has a single write bottleneck + a failover gap when the primary dies.
🤔 Three boxes all sit "in front" of your servers and all forward traffic. So why does a real architecture often have a load balancer AND an API gateway, instead of just one box?
Reveal the reasoning
They operate at different layers and do different jobs:
- Reverse proxy (nginx): the base primitive — terminates TLS, forwards to a backend, can cache static assets. "Hide my servers behind one address."
- Load balancer: a reverse proxy specialized for distributing traffic across N identical instances (round-robin/least-connections) + health checks. Job: spread load, survive an instance dying. Operates L4 (transport) or L7 (HTTP).
- API gateway: L7, per-API logic — auth, rate-limiting (
1000 req/min/key), request routing to different microservices, response aggregation, versioning. Job: one front door with policy for many services.
Cause→effect: the LB answers "which of my 10 identical app servers?"; the gateway answers "is this caller allowed, throttled, and which service owns /payments?". You run both because they solve different problems: a common topology is LB → gateway → services, where the LB spreads raw connections across a fleet of gateway instances and the gateway then applies policy and fans out to the right microservice. Cost: two hops, two more components to operate, monitor, and fail over — extra latency and operational surface in exchange for clean separation of "distribute load" from "enforce API policy."
📐 Architecture diagrams (8)


🎯 Guided practice
Easy — chat vs live sports scores. You must push server updates to clients in two products: (a) a 1-on-1 messaging app, (b) a live cricket scoreboard. Which transport for each?
Step 1 — name the direction of data flow. Chat is bidirectional (both sides send, often many messages/sec). Scores are one-way server-to-client.
Step 2 — map to the trade-off. Bidirectional, low-latency, persistent connection points to WebSockets. One-way server push over plain HTTP, with built-in auto-reconnect (the browser
EventSourceresumes viaLast-Event-ID) and simpler infrastructure, points to Server-Sent Events (SSE).Step 3 — sanity-check the rejected option. WebSockets for scores works but is overkill: you pay for full-duplex machinery you never use, drop SSE's free reconnection, and SSE rides ordinary HTTP so it traverses proxies and CDNs more cleanly. Answers: chat = WebSockets, scores = SSE. Core pattern: match transport to data-flow direction and update frequency, not to "newest tech."
Medium — design rate limiting for a payments API. Clients may send legitimate bursts (a merchant batch-charging at midnight) but the downstream bank caps you at a steady 100 req/sec. Token bucket or leaky bucket?
Step 1 — separate the two constraints. Constraint A: allow short bursts from clients. Constraint B: never exceed the bank's smooth 100 req/sec.
Step 2 — recall each algorithm's shape. Token bucket refills tokens at a fixed average rate but lets accumulated (up to bucket-size) tokens be spent at once — it permits bursts up to a cap. Leaky bucket (as a queue) admits requests into a buffer that drains at a strictly constant rate regardless of arrival pattern — it enforces a smooth output.
Step 3 — combine, because one mechanism rarely covers a two-sided constraint. Use a token bucket at ingress to admit the merchant's burst (allowing the spike up to the bucket cap), then a leaky bucket at egress toward the bank to enforce the constant 100 req/sec. Requests that overflow the ingress token bucket are rejected with
429 Too Many Requests(and aRetry-Afterheader).Step 4 — state the cost. The egress leaky bucket adds queuing latency for bursty traffic, and the buffer needs a bounded size with a drop/backpressure policy — acceptable here because never breaching the bank's cap dominates over per-request latency. Core pattern: when constraints pull in opposite directions, compose two mechanisms and explicitly name the latency and buffering cost you accept.
✨ Added by the guide — work these before the full problem set.