ACID vs BASE Properties in Databases
When we use an application – whether it's online banking or a shopping site – we expect the data to be correct and the system to work reliably. If you transfer money and a glitch happens, you wouldn’t want the bank to deduct money from your account without adding it to the recipient’s account. This is why database consistency and reliability matter so much. A reliable database ensures that even if something goes wrong (like a crash or network issue), your data isn’t lost or corrupted.
In the world of databases, there are two common models for handling consistency and reliability: ACID and BASE. These acronyms stand for different approaches in database design. In simple terms, ACID is about keeping transactions strictly correct and reliable, while BASE is about keeping the system basically available and scalable (even if data might be briefly inconsistent). They’re often seen as opposites, but each has its own use cases and trade-offs. In this post, we’ll explain what each term means, give easy examples, compare their differences, and help you decide which approach fits which situation.
What is ACID?
ACID is a set of properties that guarantee database transactions are processed reliably. A transaction is a unit of work (like transferring money or booking a ticket) that may involve multiple steps. ACID stands for Atomicity, Consistency, Isolation, Durability. These four properties ensure that even if multiple transactions occur or failures happen, the data remains correct and stable.

Atomicity, Consistency, Isolation, Durability (ACID) are four guarantees that make transactions reliable. ACID-compliant systems make sure that transactions either happen completely or not at all, the database doesn’t violate its rules, concurrent operations don’t interfere with each other, and once a transaction is saved it won’t be lost. To understand ACID, let's break down each property with a simple example:
- Atomicity: All-or-nothing. A transaction is atomic if it executes completely or not at all – there are no partial completions. For example, in a reservation system, both steps – booking a seat and updating the customer’s details – must succeed together. If one part fails, the system will undo any partial changes so you don’t end up with a reserved seat under no name. In other words, you won’t have a situation where money is taken from an ATM but you get no cash; the whole operation is rolled back if any piece fails.
- Consistency: Valid state. The database must abide by all defined rules (constraints) after the transaction. This means any transaction will bring the database from one valid state to another. For example, when transferring $100 from Account A to Account B, the total money across both accounts should remain the same before and after. If the total was $600, it stays $600 after the transfer (like $100 goes out of A and into B). The data won’t violate things like balance never going negative, etc.
- Isolation: Don’t interfere. Even if multiple transactions are happening at the same time, each one should behave as if it’s the only one running until it’s finished. For instance, in an online inventory system, if one user is updating the stock count of a product, another user reading the stock at the same time should either see the old count or the new count, but nothing in-between. Each transaction’s intermediate steps are hidden from others to avoid confusion. This prevents concurrent operations from messing up each other’s data.
- Durability: Never lost. Once a transaction is successfully completed (committed), its changes are permanent – they will survive power failures, crashes, or errors. For example, if a messaging app tells you that your message was sent, that message should be stored and never disappear even if the server crashes right after. The database will have saved the data to stable storage so it can recover to that state if needed.
In essence, ACID makes sure that the database maintains integrity: transactions are all-or-nothing, always leave the data consistent, don’t step on each other, and don’t vanish after being applied. This is great for applications where accuracy is critical.
What is BASE?
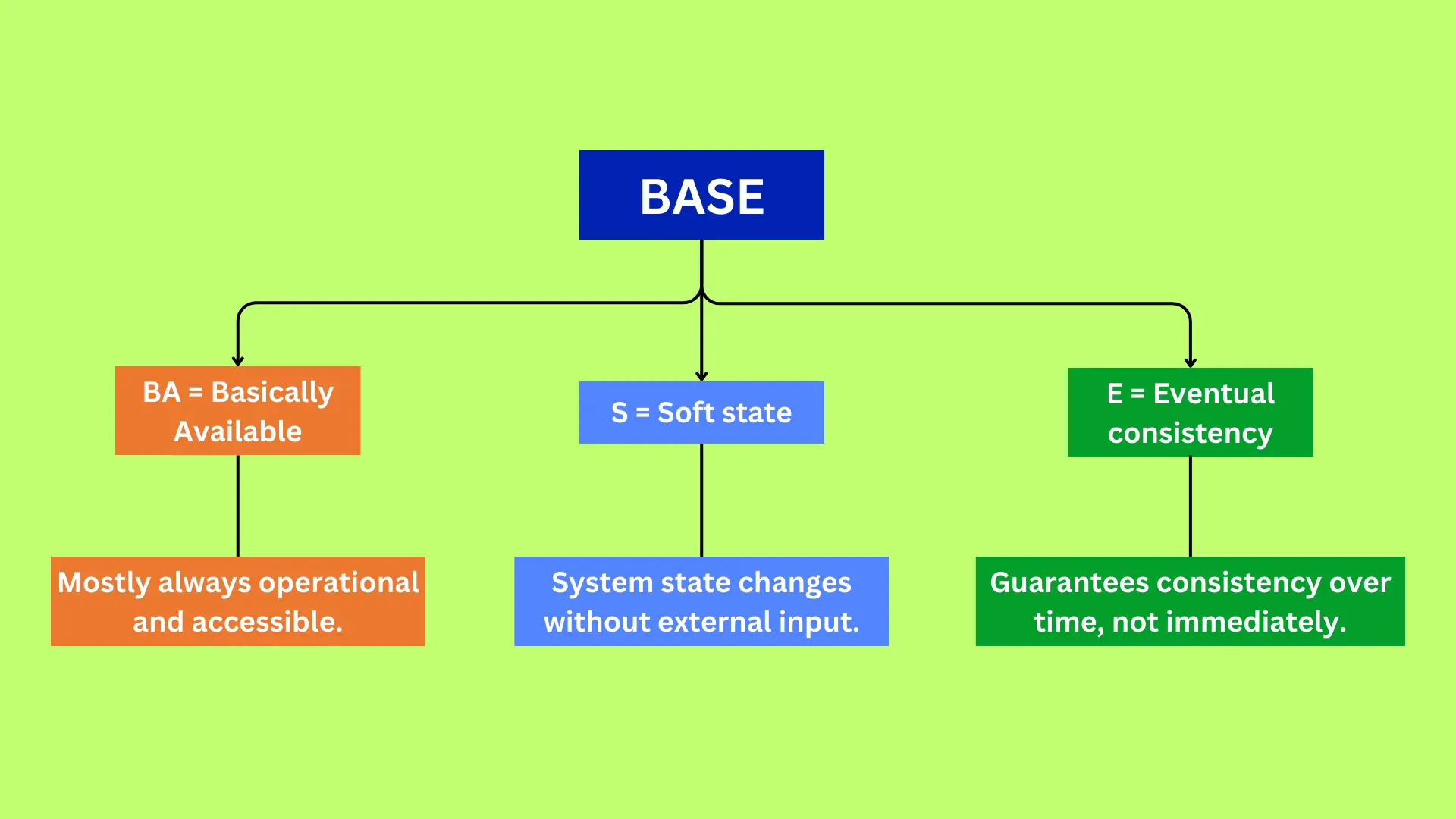
BASE is an alternative approach used mainly in many NoSQL and distributed databases. BASE stands for Basically Available, Soft state, Eventually consistent. It is almost the “opposite” of ACID in philosophy. Instead of enforcing strict consistency after every transaction, BASE systems prioritize availability and partition tolerance (being able to distribute data across many servers). The idea is that the system will be basically available at all times, and it accepts that the data might not be consistent immediately, as long as it eventually becomes consistent. Let’s break down the BASE properties with simple terms:
- Basically Available: The system guarantees availability – it will always try to give you some response, even under heavy load or if parts of the system are down. It may not be the most up-to-date data, but the service remains up. For example, during a massive online sale, an e-commerce site using a BASE model will continue to accept orders and show products even if the inventory counts are slightly behind. You might be able to place an order even if one server hasn’t caught up to an out-of-stock status, because the system chooses to stay responsive rather than lock everything. The focus is on keeping the service running.
- Soft State: The state of the system may change or fluctuate over time, even without new inputs, because updates propagate gradually. “Soft” means the data might be temporarily inconsistent or in flux. The database doesn’t enforce immediate consistency itself; instead, it’s understood that data will be updated over time and might require the application to handle interim inconsistencies. For example, if you edit a social media post, you might not see the update on your friend’s app instantly. The data is in a soft state – it’s changing in the background. After a short while, the changes will settle and everyone sees the same updated post, but in the meantime, different parts of the system might have slightly different information.
- Eventually Consistent: This is the key idea – though the system may not be consistent at every moment, if you wait a bit (and no new updates occur), it will become consistent. All replicas or nodes will eventually hold the same data. For example, imagine a distributed document editing app where two people edit the same doc simultaneously. Initially, their copies might differ. But the system will merge changes, and after some time everyone sees the same final version. There’s no guarantee when it will become consistent, only that it will happen eventually. The data might go through some conflicts or merging, but it will converge in the end.
In summary, BASE systems give up the immediate consistency that ACID guarantees, in order to gain other benefits like high availability and scalability. They let data be inconsistent for a short time, under the assumption that it will fix itself soon. This approach is common in large, distributed systems (like big web services) where it’s more important to keep the system running than to have every user see the exact same data instantaneously.
ACID vs. BASE – Key Differences and Trade‑Offs
ACID and BASE represent two different priorities in database design. A famous concept in distributed systems, the CAP theorem, says that in the presence of network partitions you can’t have both perfect consistency and perfect availability at the same time. ACID and BASE basically choose different sides of this trade-off: ACID favors consistency, and BASE favors availability. Here are the key differences and trade-offs between ACID and BASE:
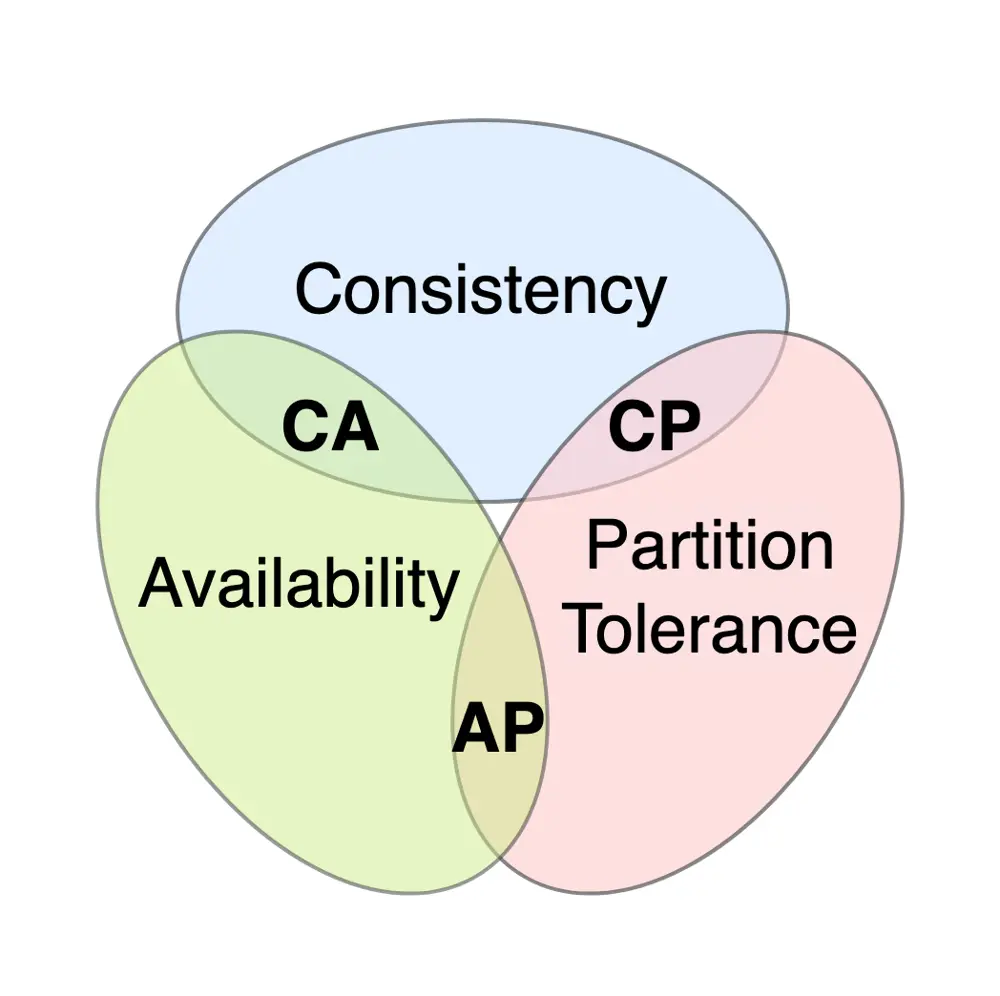
In the CAP theorem, a distributed system can only guarantee two out of three: Consistency, Availability, Partition tolerance. ACID systems choose consistency over absolute availability, while BASE systems choose availability and accept eventual consistency. In practice, this means ACID databases ensure every transaction is strict and correct at the cost of some performance or uptime, whereas BASE databases ensure the system is always responsive and can scale out, at the cost of data being momentarily inconsistent.
- Consistency vs. Availability: ACID provides strong consistency – data is correct and the same across the system right after each transaction. BASE provides high availability, often sacrificing immediate consistency. An ACID system might delay or block some operations to keep data perfectly in sync, while a BASE system would rather give a quick answer that might be slightly stale than make you wait or fail.
- Timing of Consistency: In ACID, once a transaction commits, all users see its effects immediately. Reads will fetch the latest writes. In BASE, updates propagate slowly; users might see old data for a while. Consistency is only guaranteed eventually, not instantly. For example, a comment you post on a BASE-based social network might appear to you but take a few seconds to appear for your friends.
- Transactional Approach: ACID is all-or-nothing. Transactions are completely rolled back if any part fails (ensuring atomicity). BASE can allow partial updates to be seen; it’s more flexible/loose in how transactions are handled. There isn’t usually a strict concept of a multi-step transaction in BASE – instead, it might update different pieces of data at different times and resolve inconsistencies later. This can make ACID safer for complex multi-step changes, while BASE is okay with simpler operations spread over time.
- Performance and Scalability: ACID systems often trade some performance for accuracy. They may need locks or wait times to keep transactions isolated and consistent, which can slow things down when there’s a lot of traffic. They can also be harder to scale horizontally (across many servers) because of the need to coordinate every transaction globally. BASE systems, on the other hand, excel at scaling out. They can spread data across many nodes and don’t need to coordinate every single update immediately, leading to better throughput and fault tolerance under heavy load. This is why many large web applications use BASE-oriented databases – they can handle millions of users by spreading data, at the cost of having to manage eventual consistency.
- Complexity and Handling Inconsistencies: With ACID, the database takes care of consistency automatically – developers can assume the DB will enforce the rules. With BASE, the burden of dealing with temporary inconsistencies often falls on the application developers. For instance, if two writes conflict or if data is out-of-sync, the system (or developer) must reconcile it later. The database doesn’t guarantee the data is the same everywhere at once. This makes ACID systems simpler to develop for in terms of data correctness, whereas BASE systems require careful design to handle eventual consistency (like conflict resolution or reminding the user that data may update shortly).
Use cases: Because of these differences, ACID and BASE tend to be used in different scenarios. If an application absolutely requires trustable, correct data at all times, ACID is the go-to model. For example, banks and financial systems almost exclusively use ACID-compliant databases – you can’t risk any inconsistency when dealing with money. A classic relational database (SQL database) in a banking system will ensure each transaction (withdrawal, transfer, etc.) is ACID so that errors like double-spending or lost transactions never happen. On the other hand, if an application needs to be highly available, scalable, and can tolerate slight delays in consistency, BASE is often chosen. For instance, large e-commerce websites or social media platforms with millions of users might use BASE principles – the priority is that the site is up and responsive globally, even if, say, a profile update or a product inventory change isn’t visible everywhere instantly. In an online shopping scenario, it might be more important that the website never goes down during a sale than every server knowing the exact stock count that very second.
Real-World Examples of ACID and BASE Databases
To cement the idea, let’s look at some real database systems that follow each model:
- ACID-compliant databases: Most traditional SQL relational databases adhere to ACID properties. Examples include MySQL, PostgreSQL, Oracle Database, SQLite, and Microsoft SQL Server – these systems are built to ensure strict transactional consistency. They are commonly used for applications like banking systems, e-commerce orders, or any scenario where data integrity is paramount. When you use a MySQL or PostgreSQL database, you can usually rely on transactions to be fully ACID (for instance, wrapping a series of SQL statements in a transaction that either commits all or rolls back all if something fails). This makes them reliable for critical data. Some newer relational databases and even a few NoSQL ones can also provide ACID transactions (for example, MongoDB in certain configurations), but as a rule of thumb, SQL = ACID is a safe assumption.
- BASE-oriented databases: Many NoSQL and distributed databases use the BASE philosophy. Examples include Apache Cassandra, Amazon DynamoDB, Couchbase, MongoDB, and Redis, among others. These databases are designed to run across clusters of machines, handle large volumes of data, and remain available under various conditions. They often give up ACID’s immediate consistency – for instance, Cassandra and DynamoDB provide eventual consistency (though some offer tunable consistency levels). These systems are typically used in big data, real-time web applications, content delivery networks, social networks, and other scenarios where scaling out and handling partitions are more important than instant consistency. For example, Cassandra is used by companies like Netflix and Facebook for its ability to store massive amounts of data across data centers while still being fast and available. DynamoDB (a NoSQL service by AWS) is used in many high-traffic websites where the data model can tolerate eventual consistency.
Conclusion – Choosing ACID or BASE
Both ACID and BASE have their strengths and weaknesses, and neither is “better” in all cases – it truly depends on your application’s needs. ACID guarantees a high level of data integrity and reliability (no half-finished transactions, no dirty reads, no lost updates), which is essential for scenarios like finance, healthcare, inventory management, or any system that can’t afford even minor inconsistencies. If your application demands strict accuracy and safety – for example, a banking app or an online order system – an ACID-compliant database (such as MySQL or PostgreSQL) is likely the right choice. The trade-off is that you might sacrifice some performance or flexibility in scaling, but you gain peace of mind that your data is always correct.
On the other hand, BASE is often the right choice for distributed systems and applications where availability and scaling are paramount, and where the business can tolerate slight delays in data consistency. If you’re building the next social media platform, a global online game, or a large content service, you might choose a BASE-oriented database (like Cassandra or DynamoDB) to ensure the system stays responsive and can handle partitions or server failures gracefully. You accept that users might not see the latest update instantly in exchange for the system being highly scalable and fault-tolerant.
In short, choose ACID when you need guaranteed consistency and integrity (and your data is structured in a way that fits a traditional database). Choose BASE when you need scalability and availability above all, and your use case can handle being “eventually” consistent. Many modern systems even blend the two approaches – for example, by using an ACID database for critical transactions and a BASE/NoSQL database for analytics or caching, finding a balance between consistency and performance. Understanding the differences between ACID and BASE helps you make an informed decision and design your data architecture with the right expectations. For a beginner, just remember: ACID = strong, immediate consistency (think banks), BASE = flexibility and availability with eventual consistency (think big web apps). By evaluating the needs of your project (do you need absolute accuracy, or can you afford some delay?), you can confidently choose the model that will keep your data safe and your users happy.
🤖 Don't fully get this? Learn it with Claude
Stuck on ACID vs BASE Properties in Databases? Open Claude, copy a block below, and it'll teach you this exact concept — visually and interactively.
Build the mental picture, not memorization.
I just read a lesson on **ACID vs BASE Properties in Databases** (System Design) and want to truly understand it. Explain ACID vs BASE Properties in Databases from first principles using ONE vivid real-world analogy and a visual mental model — draw it as ASCII art or a clear step-by-step diagram — with a concrete example using real numbers. Then ask me one question to check I got the mental picture, and wait for my reply. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Socratic — adapts to where you're stuck.
Teach me **ACID vs BASE Properties in Databases** interactively. Ask me ONE guiding question at a time, wait for my answer, and adapt to my confusion — build the idea with me step by step instead of explaining it all at once. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Active recall exposes what you missed.
Quiz me on **ACID vs BASE Properties in Databases** with 5 questions, easy to tricky, ONE at a time. Tell me if each answer is right; at the end, explain clearly what I got wrong and why. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Intuition + hook + flashcards for long-term memory.
Help me remember **ACID vs BASE Properties in Databases** for the long term: give the one-sentence intuition, a memorable hook/mnemonic, a tiny worked example, and 3 active-recall flashcards (Q -> A). If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.