System Design Building Blocks
Step 2 in the System Design path · 23 concepts · 0 problems
📘 Learn System Design Building Blocks from zero
System Design "building blocks" are the reusable primitives — caches, load balancers, replicas, partitions, indexes — you snap together to answer the open-ended "design X" interview question. The interviewer rarely wants the one right answer; they want to hear you reason about WHY a block belongs there, the exact mechanism by which it helps, and the cost it quietly adds (staleness, complexity, more failure modes). Each step below asks you a concrete question first — commit to an answer in your head before you reveal the reasoning. That habit of "decision → mechanism → trade-off" is exactly what separates a hire from a no-hire.✨ Added by the guide to build intuition — not from the source course.
Lessons in this topic
- ○What is a System Design Interview
- ○What are BackoftheEnvelope Estimations
- ○Things to Avoid During System Design Interview
- ○System Design Basics
- ○Key Characteristics of Distributed Systems
- ○Load Balancing
- ○Load Balancing Algorithms
- ○Caching
- ○Data Partitioning
- ○Indexes
- ○Proxies
- ○Redundancy and Replication
- ○CAP Theorem
- ○PACELC Theorem
- ○Consistent Hashing
- ○Bloom Filters
- ○Quorum
- ○Leader and Follower
- ○Heartbeat
- ○Checksum
- ○Importance of Discussing Tradeoffs
- ○System Design Interviews A step by step guide
- ○System Design Master Template
🏗️ Apply it — design walkthrough
Work through this after you've learned the concepts in the lessons above.
🤔 You're asked to design a Twitter-like feed for 200M daily users posting 2 tweets/day each. Before drawing a single box, what numbers must you derive, and why does this gate every later block?
Reveal the reasoning
Chain: 200M × 2 = 400M tweets/day → ÷ 86,400s ≈ ~4,600 writes/sec average, and peak is ~2–3x average → ~9,000–14,000 writes/sec (round to ~12K). Reads dominate: if each user refreshes a 100-tweet feed several times/day, you land around ~100K–1M reads/sec.
- This read:write ratio of roughly 100:1 is the single most important number — it is what justifies caching and read replicas later.
- Storage: 400M tweets × ~300 bytes ≈ 120 GB/day → ~44 TB/year of raw text → forces partitioning.
Cause → effect: the estimate dictates which blocks are mandatory — a read-heavy ratio mandates caches/replicas, the storage figure mandates sharding. Cost/trade-off: these are order-of-magnitude guesses, not precise figures — stating a wrong assumption confidently (e.g. forgetting the peak multiplier) makes you under-provision by ~3x. Always say your assumptions out loud so the interviewer can correct them cheaply.
🤔 You have 12,000 writes/sec hitting one server that maxes out at 2,000 req/sec. You add 10 servers. What exact problem does a load balancer solve, and what new single point of failure did you just create?
Reveal the reasoning
Chain: clients can't know which of 10 servers to hit → an LB sits behind one virtual IP / DNS name → it spreads 12,000 req/sec across 10 boxes = 1,200 each, comfortably under the 2,000 limit. It also runs health checks (e.g. every few seconds) and stops routing to a dead node within seconds, so one crash doesn't drop traffic.
- Mechanism: L4 LBs route on IP/port (fast, payload-opaque); L7 LBs parse the HTTP request and can route
/imagesvs/apidifferently (smarter, slightly more CPU per request). - When: the moment you have >1 server, or want zero-downtime rolling deploys.
Cost/trade-off: the LB itself is now a single point of failure — if it dies, all 10 healthy servers become unreachable. Fix: run LBs in an active-passive pair with a floating/virtual IP that fails over to the standby, which adds cost and one more component to monitor. You've traded many per-server failure modes for one smaller, centralized one that you then make redundant.
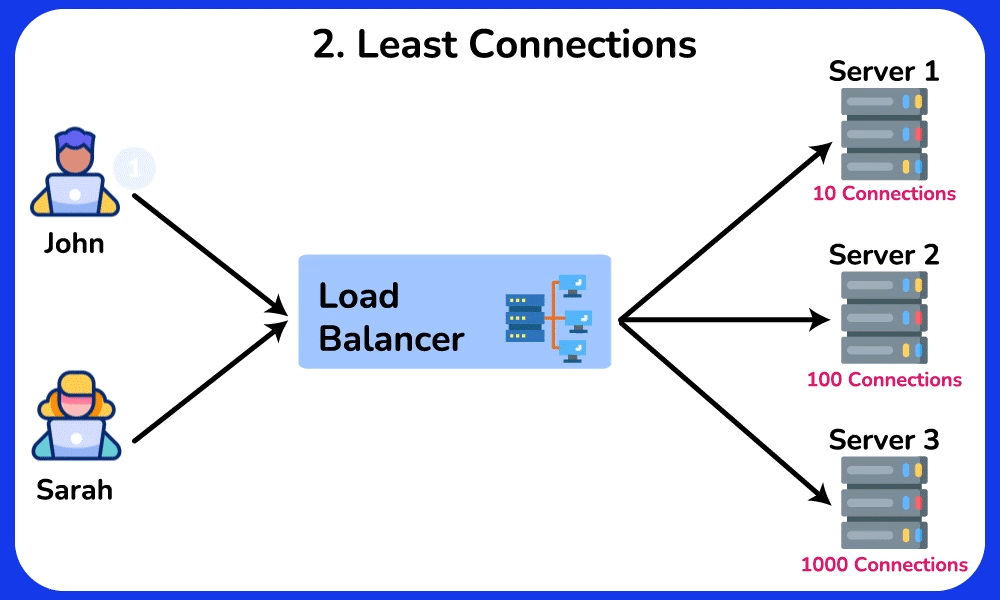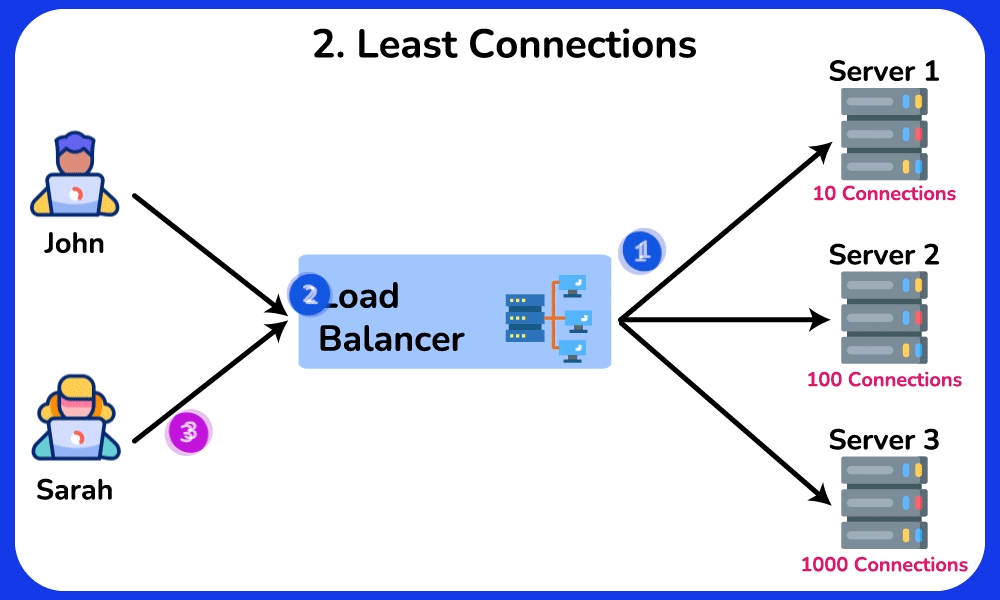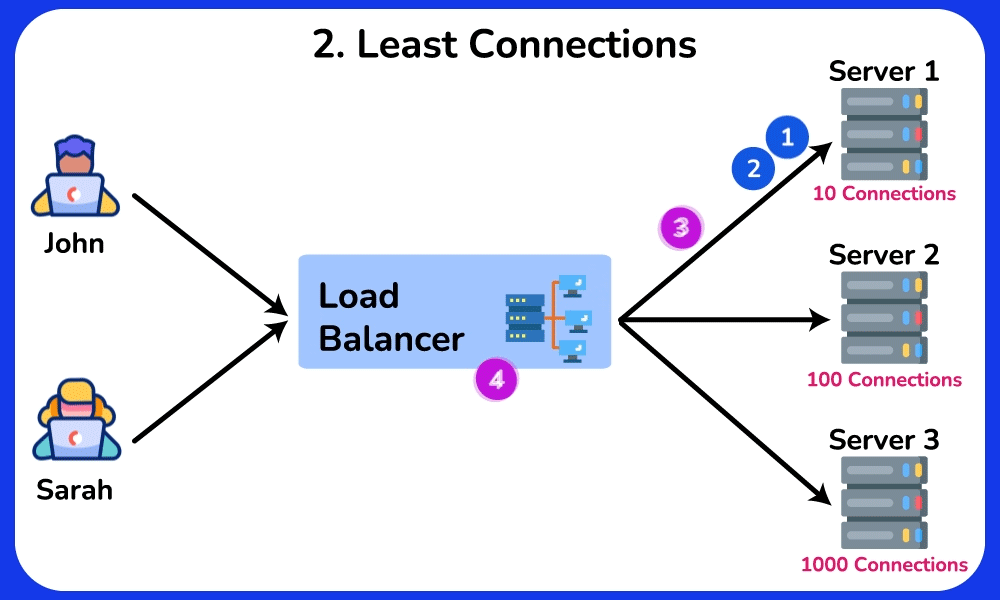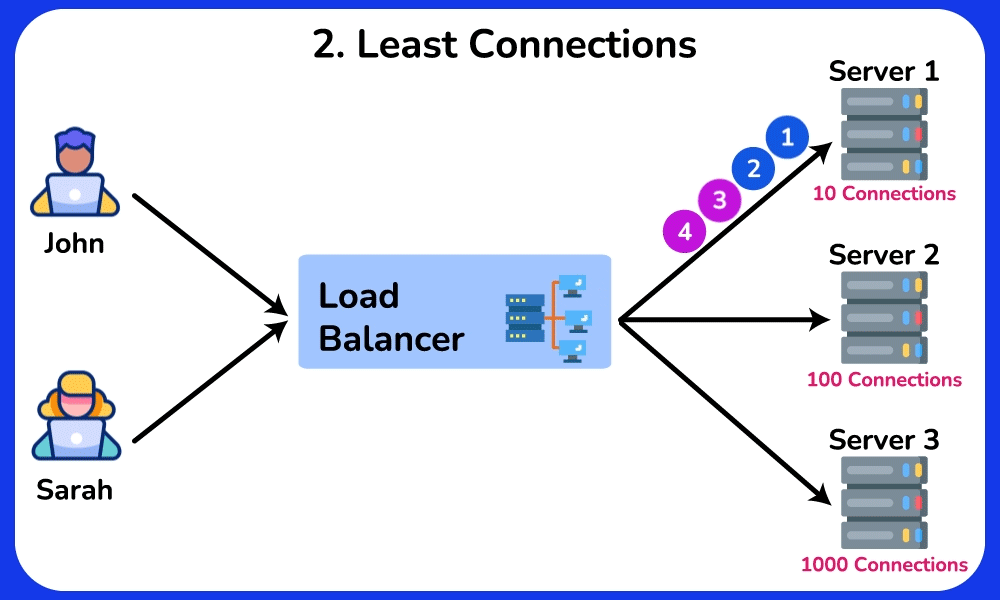
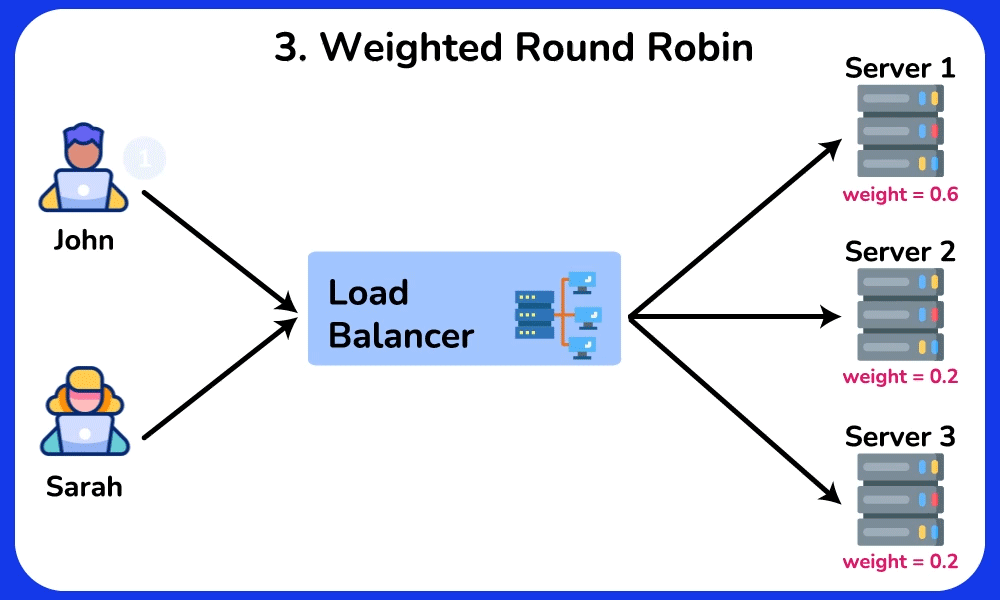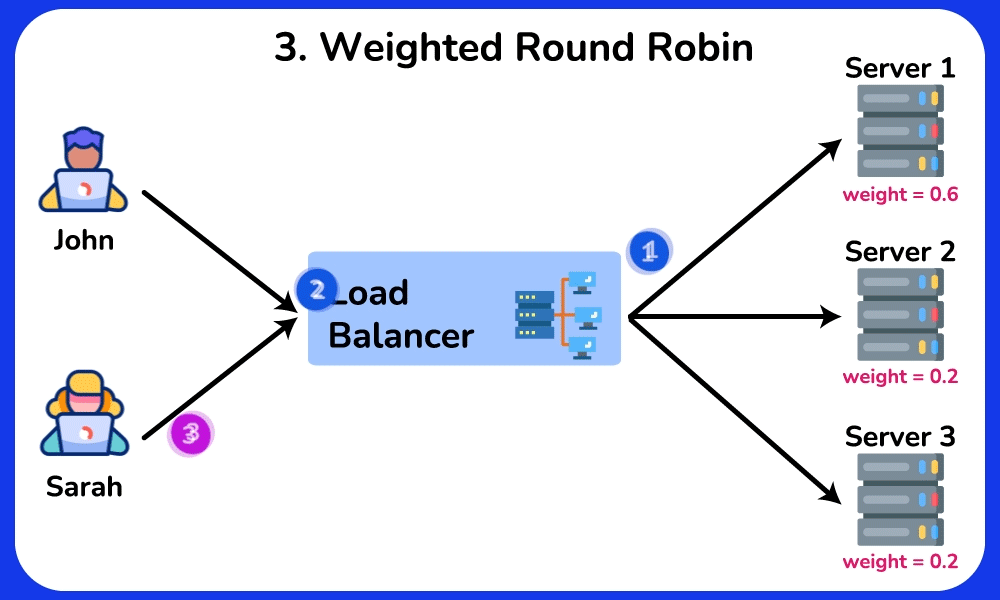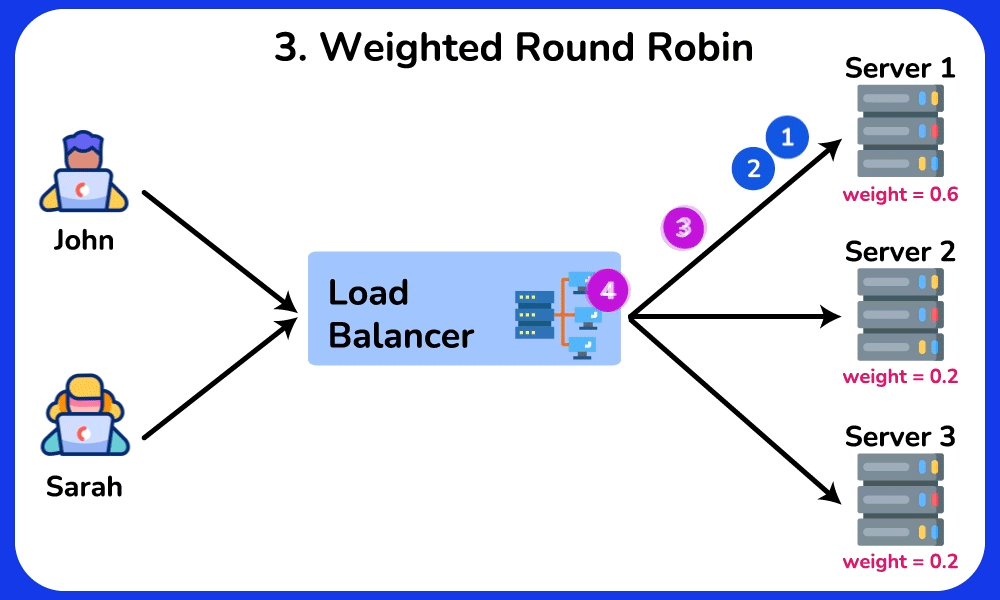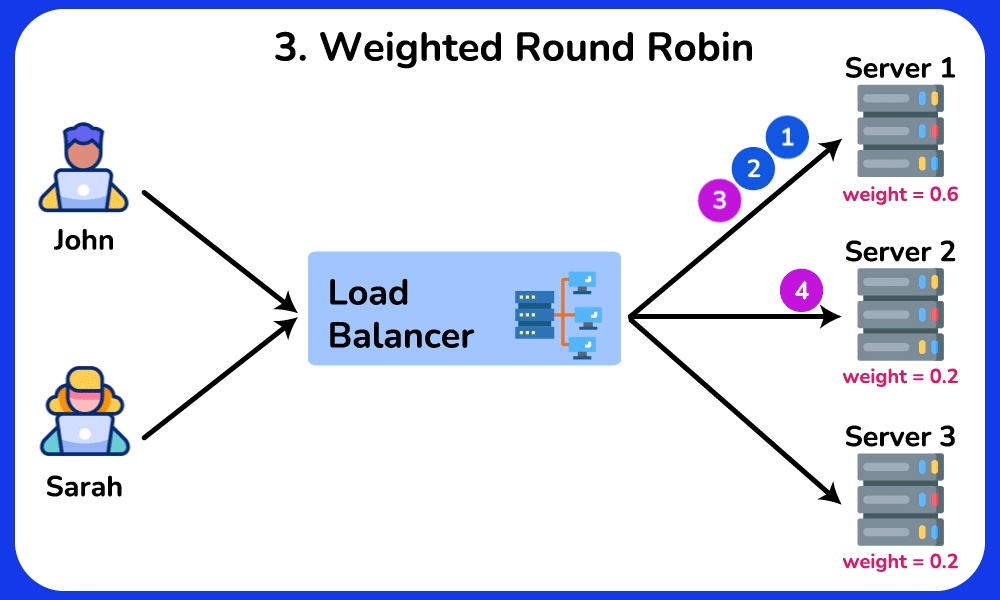
🤔 Round-robin sends request 1→server A, 2→B, 3→C, evenly. So why do real systems often NOT use plain round-robin, and when would "least connections" or a hashing algorithm be strictly better?
Reveal the reasoning
Chain: round-robin assumes every request costs the same. But if server A draws three 10-second report queries while B/C get 10ms lookups, round-robin keeps feeding A its even share → A's queue grows → its p99 latency spikes while B/C sit idle.
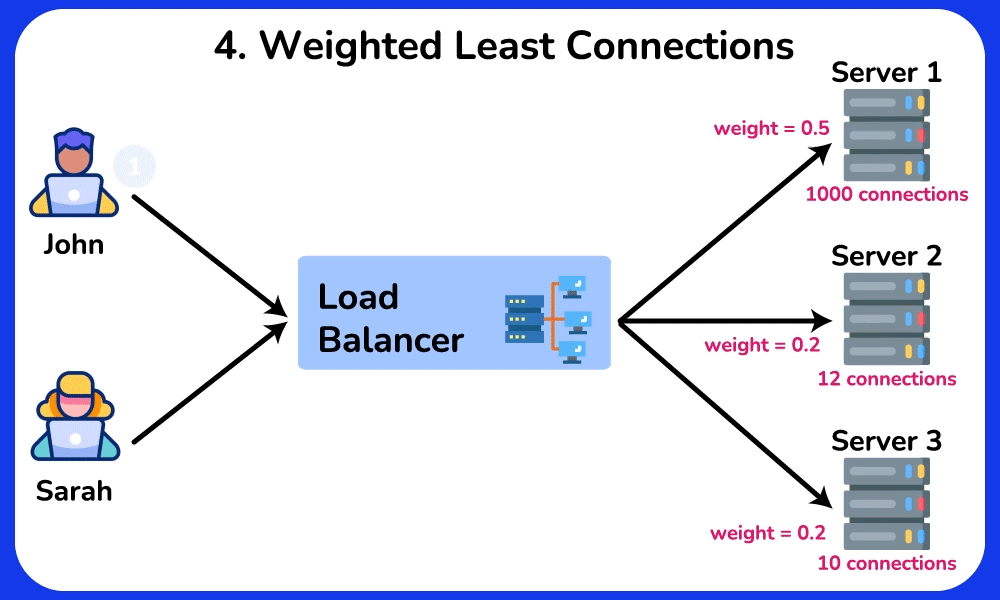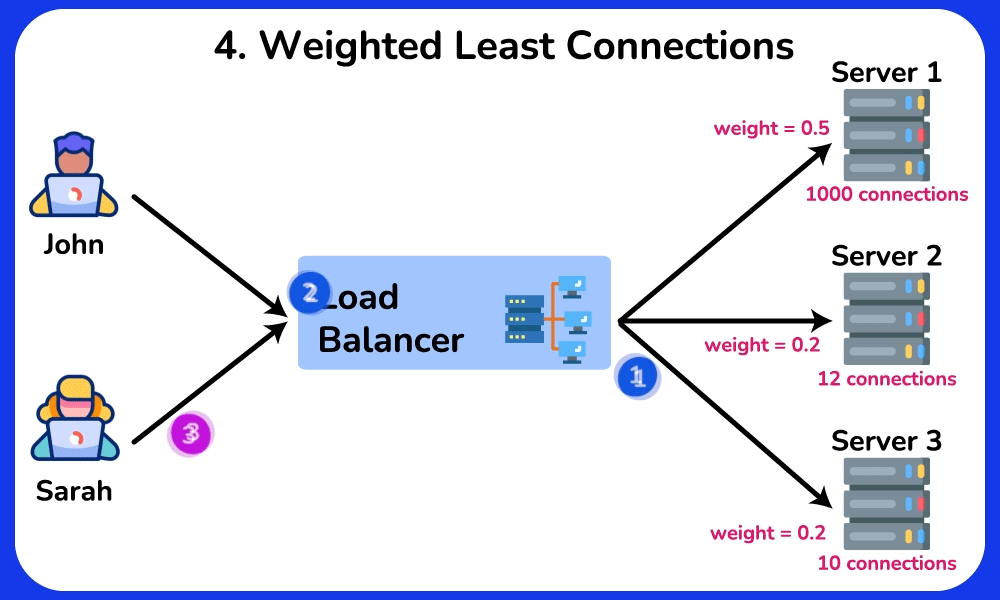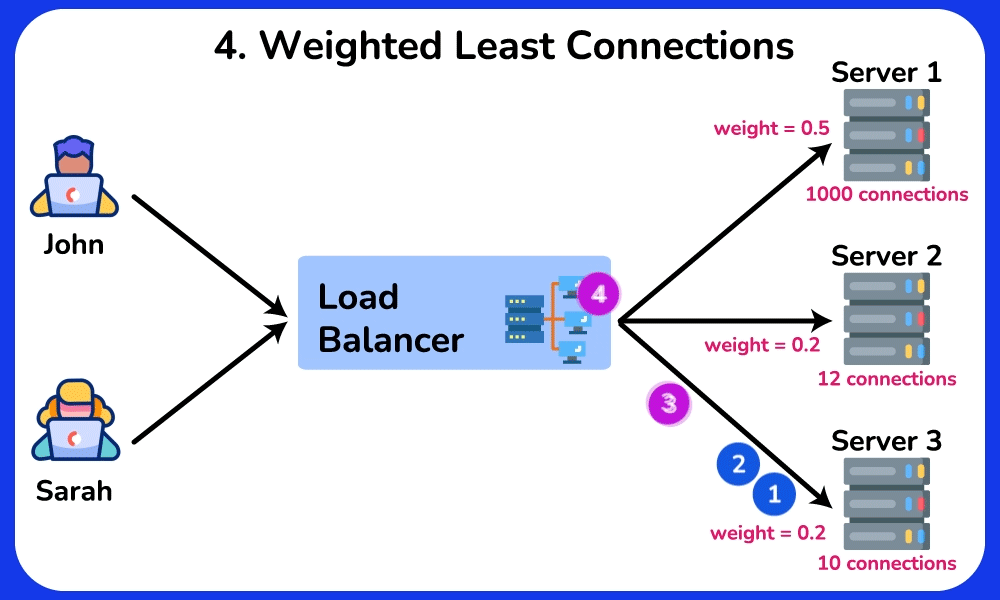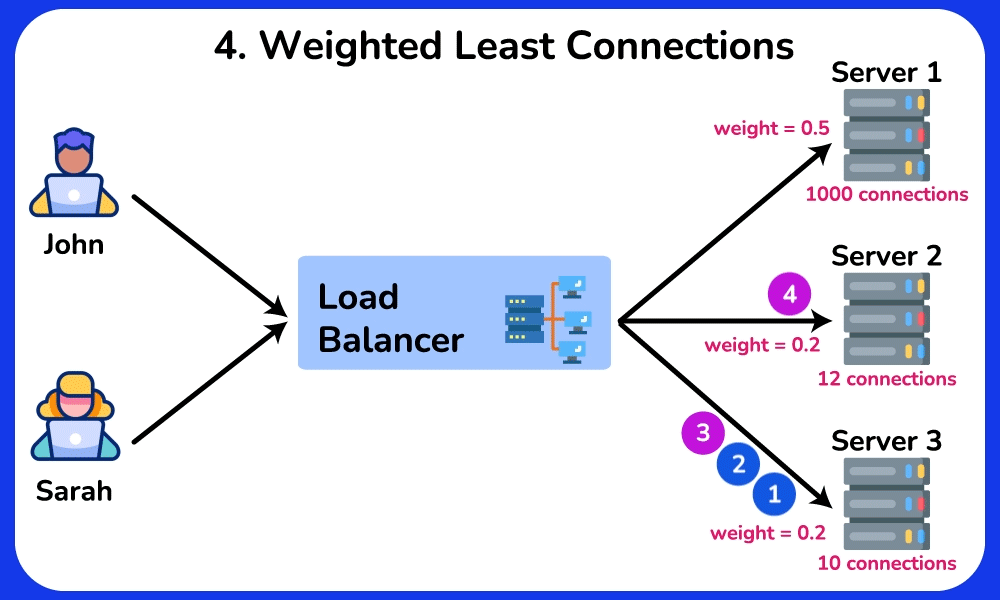
- Least-connections: routes to whoever has the fewest in-flight requests → naturally drains work away from the slow/overloaded A. Best for uneven request durations.
- Weighted round-robin: a 16-core box gets weight 4, a 4-core box weight 1 → handles heterogeneous hardware.
- IP/URL hash: the same client always lands on the same server → enables warm local cache hits / sticky sessions.
Cost/trade-off: least-connections needs the LB to track live connection counts (extra state and bookkeeping). Hash-based stickiness deliberately breaks even distribution: one whale client (a celebrity, a hot key) can overload its assigned server, and naive mod N hashing reshuffles nearly every client when a server is added or removed — which is the exact pain consistent hashing later solves by remapping only ~1/N of keys.
🤔 Your DB read takes 20ms; a Redis lookup takes 1ms. With a 100:1 read:write ratio and a 90% cache hit rate, walk through the exact latency and load math. Then: what breaks when the cached data is wrong?
Reveal the reasoning
Chain: cache-aside — the app checks Redis first; on a miss it reads the DB, then writes the value back to Redis with a TTL. At a 90% hit rate: 90% of reads cost 1ms, 10% cost 1ms + 20ms ≈ 21ms → weighted average ≈ 3ms vs 20ms before, and crucially the DB now sees only 10% of read traffic (e.g. 100K → 10K reads/sec). That drop is what lets the DB survive.
- p99 effect: the slow tail (DB queueing under load) is now hit by far fewer requests, so once the DB is no longer saturated the p99 collapses.
Cost/trade-off — staleness: a cached value can be out of date until its TTL expires. You pick the dial: short TTL (fresher, more DB load) or write-through / invalidate-on-write (consistent, more write-path complexity). Eviction: RAM is finite, so LRU drops cold keys — only worth it if the hot subset fits in memory. Stampede: when a hot key expires, thousands of concurrent misses hammer the DB at once — mitigate with a per-key rebuild lock (only one request repopulates) or jittered TTLs. Caching trades correctness-by-default for speed.
🤔 Your ~44 TB/year of tweets won't fit on one machine, and writes exceed one node's capacity. You decide to shard. What's the difference between sharding by hash(user_id) vs by date range — and what's the failure mode of each?
Reveal the reasoning
Chain: partitioning splits data across N nodes so each holds ~44 TB / N and absorbs ~12,000 / N writes/sec. The shard key decides everything downstream.
- Hash(user_id): spreads load evenly → no single hot node. But a query like "all tweets between Jan–Mar" has no single home and must scatter-gather across all N shards, and with naive
mod Nhashing, adding a node remaps nearly every key (use consistent hashing to limit churn). - Range by date: time-range queries hit one shard → fast and cheap. But today's shard takes ~100% of writes while older shards sit idle → a write hotspot that moves over time.
Cost/trade-off: the deeper pain is cross-shard operations — a JOIN or a transaction spanning two shards needs distributed coordination (two-phase commit, slow and failure-prone) or app-level stitching. Celebrity hotspot: one user with 100M followers can overwhelm their shard regardless of key choice. Partitioning buys horizontal scale at the price of cheap joins and global transactions — so you pick a key that matches your dominant query pattern.
🤔 A query "find tweets by @user" scans a 10M-row table at maybe 1M rows/sec — that's ~10 seconds. You add an index and it returns in ~1ms. What did the index actually build, and why isn't it free to just index every column?
Reveal the reasoning
Chain: an index is a separate sorted structure (typically a B-tree) mapping user_id → row locations. Instead of a full scan (O(n), ~10M row reads), the DB descends the tree (O(log n); log₂(10M) ≈ ~23 levels of comparison, and far fewer actual node reads thanks to high B-tree fanout) → the 10s scan becomes a handful of seeks ≈ ~1ms.
- Mechanism: it trades a linear scan for a logarithmic lookup by keeping the indexed column pre-sorted.
- When: columns you frequently filter / sort / join on AND that are selective (many distinct values).
Cost/trade-off: every index is extra storage and must be updated on every write — each insert/update/delete also rewrites every affected index's B-tree. So 5 indexes can make writes meaningfully slower (often ~2–3x) and bloat disk. Indexing a low-cardinality column (e.g. a boolean) barely helps because it can't narrow the candidate set. Indexes optimize reads by taxing writes — the wrong default for a write-heavy table.
🤔 Your single DB serves 10K reads/sec fine, but if that box dies you lose everything, and you can't scale reads further. You add 2 replicas. How does this fix both problems at once — and why might a user post a tweet and then NOT see it?
Reveal the reasoning
Chain: leader-follower replication — all writes go to the leader, which streams its change log to 2 followers. Now: (1) reads spread across leader + 2 followers → roughly 3x read capacity; (2) if the leader dies, a follower is promoted (failover) → no committed data lost, only a brief unavailability window.
- Mechanism: followers replay the leader's log, trailing it by anywhere from a few ms to seconds under load.
Cost/trade-off — replication lag: with async replication the leader acks the write immediately, so a user who posts (write → leader) and instantly reads from a lagging follower sees nothing yet → a read-your-writes violation. Fixes: pin that user's reads to the leader for a short window after a write, or use sync replication (the leader waits for a follower to confirm — safer, but every write now pays the slower of the two and write latency rises). Replication trades a window of inconsistency for availability and read scale — so you decide per read path how fresh the data must be.
📐 Architecture diagrams (8)
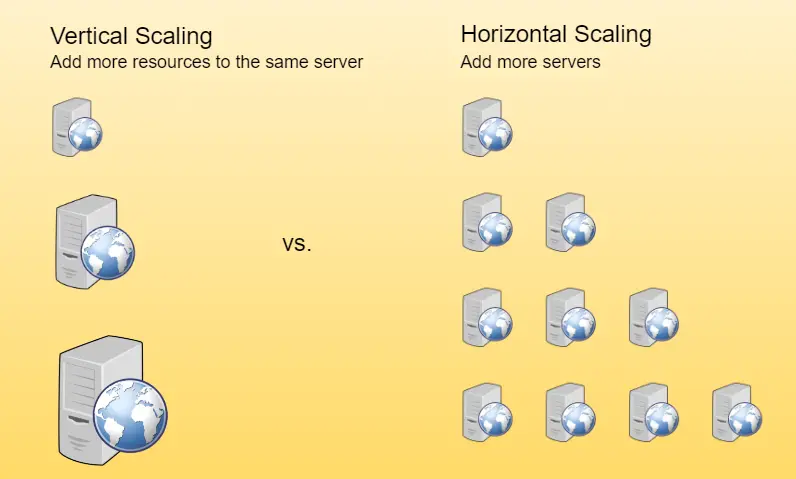
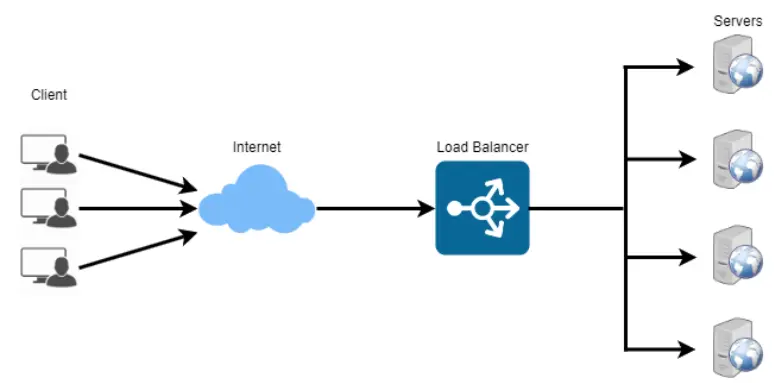

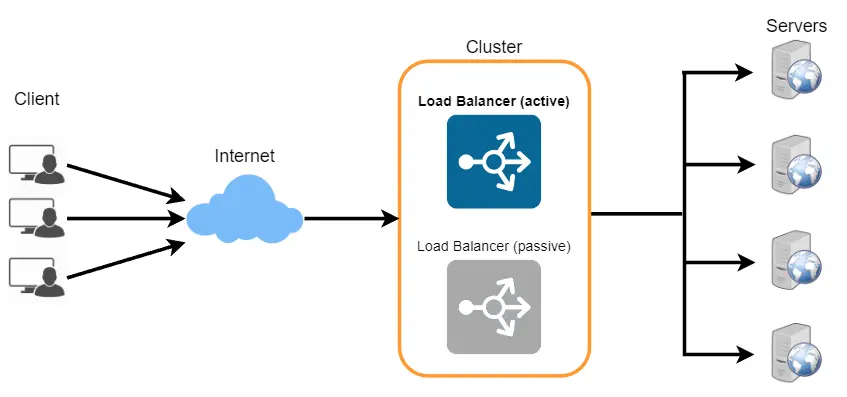
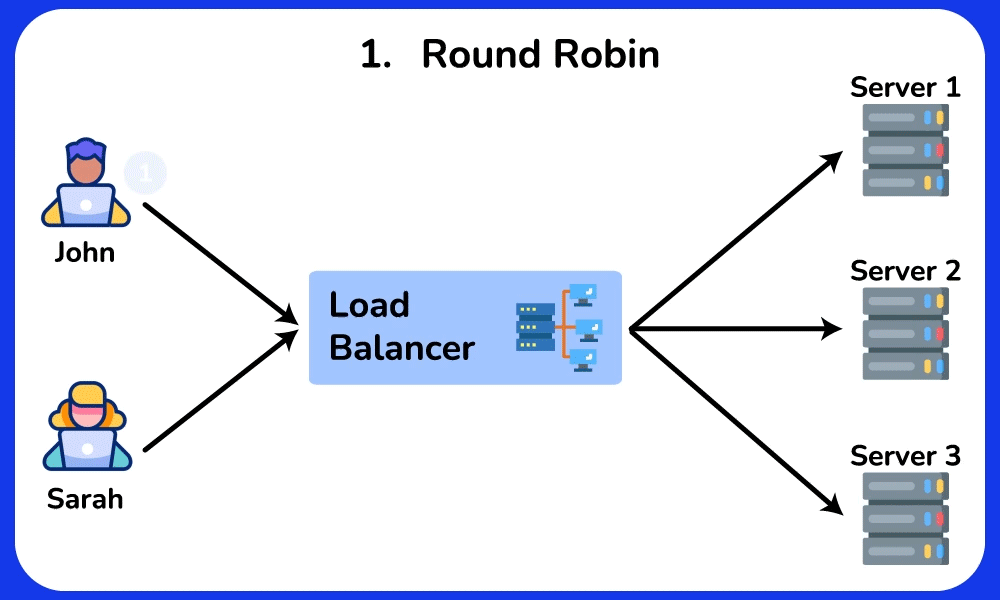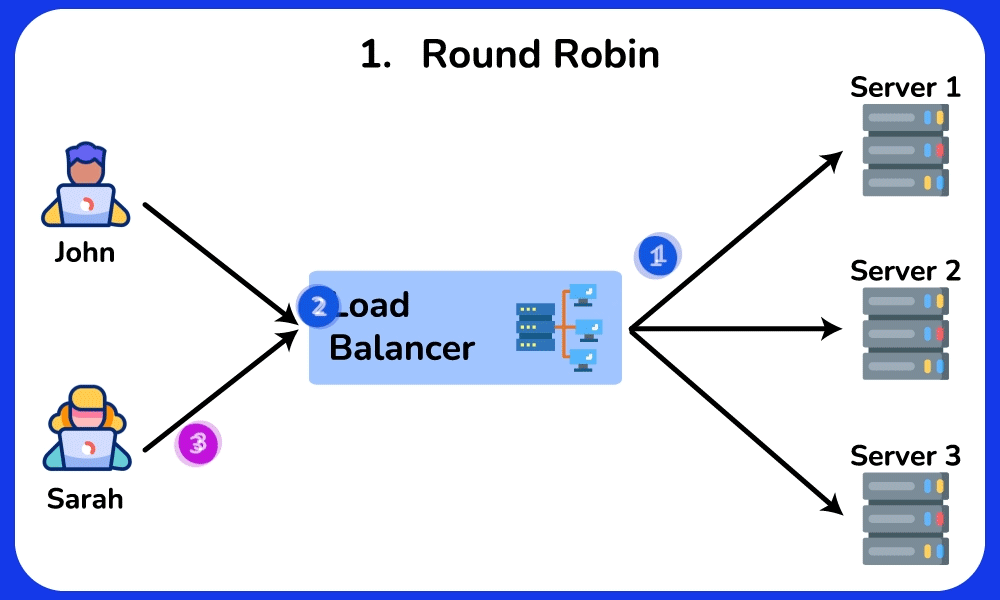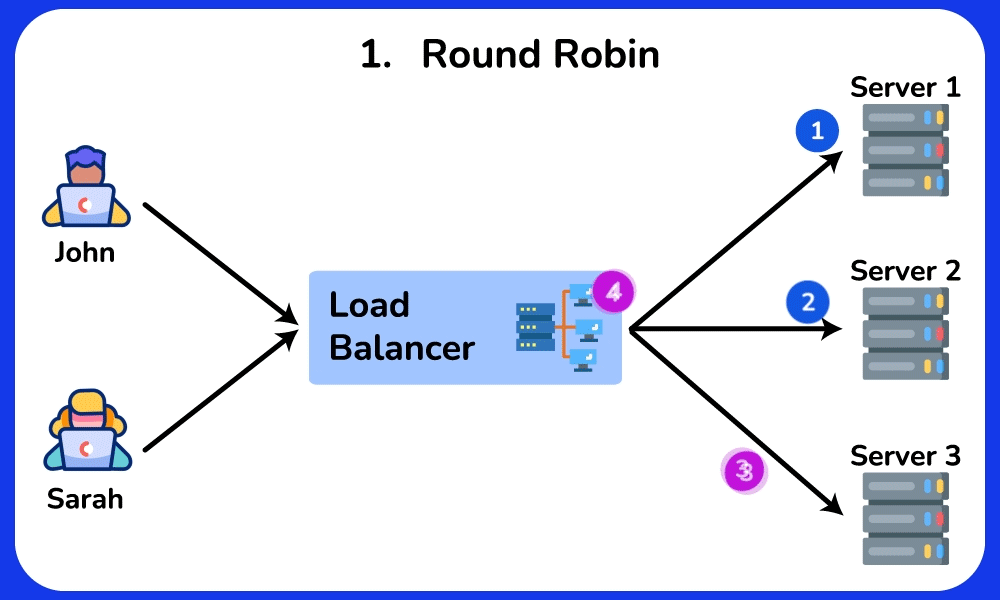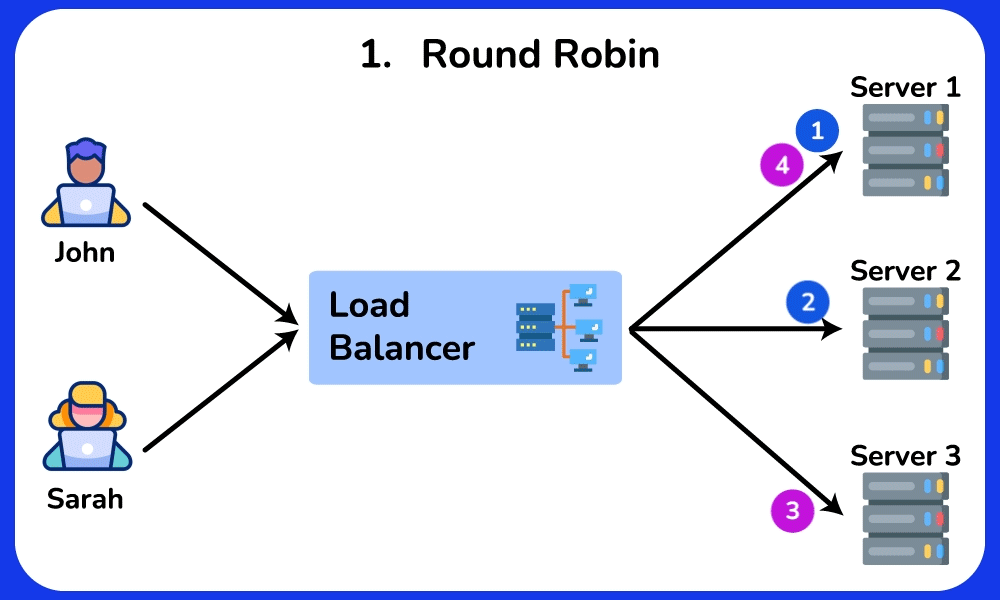
🎯 Guided practice
- Easy — Pick the right block. "A news site shows the same 50 trending articles to 2M readers/hour; the DB is melting under read load. What do you add?" Step 1: classify the workload — extreme read-heavy, tiny working set (50 items), repeated reads of identical data. Step 2: map the symptom to a limit — DB CPU/IO saturated by redundant identical reads. Step 3: the matching block is a cache in front of the DB using cache-aside: on a request, check Redis; on miss, read DB and populate the cache. Step 4: name the tradeoff — cached articles can go stale, so set a short
TTL(e.g. 60s) or invalidate on edit; guard the expiry moment against a thundering herd (request coalescing / lock-on-miss). Pattern learned: read-heavy + small hot set ⇒ cache; always pair a cache with an invalidation/expiry story. - Medium — Scale storage and survive failure. "Design the data layer for a chat app: 500M messages/day, must stay available if a server dies, and inbox queries must be fast." Step 1 (estimate): 500M / 86,400 ≈
5,800 writes/secaverage (size for a peak multiple, say 3–5×); one node can't hold or serve this → scale out. Step 2 (partition): shard byuser_id(or conversation_id) so one user's messages co-locate; use consistent hashing so adding capacity moves only ~1/N of keys, not the whole keyspace. Step 3 (availability): add replication — one leader per shard takes writes and replicates to followers; a heartbeat detects leader death and triggers failover so there's no single point of failure. Step 4 (fast queries): add a secondary index on(user_id, timestamp)for O(log n) range scans of a conversation. Step 5 (tradeoff): with async replication, a read served by a follower can lag the leader — you get eventual consistency and possible stale reads (no read-your-writes unless you route to the leader). This is not "AP" by itself: CAP only describes behavior during a partition, and a single-leader design typically sacrifices availability of the affected shard while a new leader is elected. Per PACELC, even with no partition (the Else branch) async replication trades consistency for lower latency. If correctness matters more, use synchronous quorum reads/writes withW + R > N. Pattern learned: scale via partition (+consistent hashing), survive via replication (+heartbeat/failover), query fast via indexes — and explicitly state the consistency/latency tradeoff each choice forces.
✨ Added by the guide — work these before the full problem set.