medium Designing YouTube Likes Counter

Problem Statement: Design a backend system to manage likes and dislikes for YouTube videos and comments at scale. The system must handle recording user reactions, updating aggregate counts, and retrieving these counts with low latency. It must be architected to support millions of concurrent users and billions of historical data points.
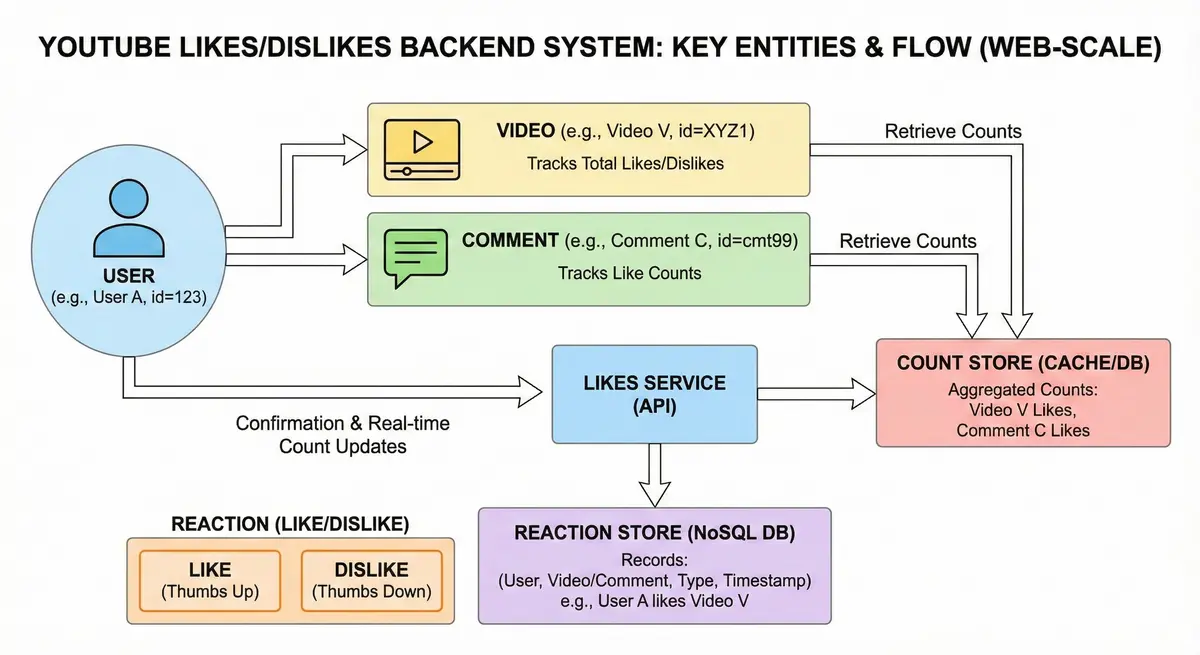
Key Entities:
- User: An individual viewer identified by a unique
userID(e.g., User A, id=123). Users are the actors who generate reaction events. - Video: A content item identified by a unique
videoID(e.g., Video V, id=XYZ1). The system must track total likes and dislikes for every video. - Comment: A user-generated response to a video, identified by a unique
commentID. Like videos, comments also track aggregate like counts. - Reaction (Like/Dislike): An association entity linking a User to a specific Video or Comment. It represents the type of interaction (Like or Dislike) and includes metadata such as a timestamp. A user can toggle or remove their reaction at any time.
Real-World Example:
Consider a scenario where user Alice watches the video “Funny Cats” (videoID: abc123).
- Video Interaction: Alice clicks the "thumbs up" button. The system records a Like event linking Alice to the video and triggers an increment to the video’s total like count.
- Comment Interaction: Alice reads a comment (
commentID: cmt99) and likes it. The system records this reaction and updates the comment's count. - Concurrent Interaction: Simultaneously, user Bob clicks "thumbs down" on the same video. The system records a Dislike event and increments the video’s dislike count.
The system must ingest these events and update the visible counts reliably and efficiently, ensuring data consistency even when millions of users interact with popular content simultaneously.
2. Requirements Analysis
Functional Requirements
- Reaction Management (Like/Dislike): Users must be able to like or dislike videos and comments. Each valid action must update the aggregate count for that content entity. A user is limited to one active reaction state per item (Like, Dislike, or None).
- State Transitions (Undo/Toggle): The system must support mutability. Users can undo a reaction (reverting to "None") or toggle their state (switching from Like to Dislike). A toggle action implies two simultaneous count updates: decrementing the old reaction count and incrementing the new one.
- Idempotency: The system must handle duplicate requests gracefully. Repeated processing of the same like/dislike event (e.g., due to network retries) must not erroneously inflate counts or corrupt data.
- Data Retrieval: The system requires an interface to fetch aggregate counts (total likes/dislikes) and the user's current status (e.g., "isLiked: true") for a given video or comment. This data is critical for rendering the UI on every page load.
- Read-Your-Own-Writes Consistency: To ensure a positive user experience, the system must provide immediate feedback to the actor. When a user likes a video, their UI should reflect the change instantly, even if the global count visible to other users takes a few moments to converge.
Non-Functional Requirements
-
Scalability: The system must be designed for web-scale traffic, capable of ingesting billions of reaction events and serving high-throughput read queries. The architecture should support horizontal scaling (sharding) to accommodate exponential growth in users and content volume.
-
Performance:
- Write Latency: Reaction processing should be rapid (ideally <100ms at p95) to ensure a responsive UI.
- Read Latency: Fetching counts must be extremely fast (ideally <20ms) as this occurs on every video/comment view.
- Trade-off: We prioritize high throughput and low latency over immediate global consistency.
-
Consistency Model: We accept Eventual Consistency for aggregate counts. It is acceptable if replicas or caches lag slightly behind the master data. The system guarantees that given enough time, all nodes will converge to the correct count. Strong consistency is not required for popularity metrics.
-
Availability & Reliability (CAP Theorem): In terms of the CAP theorem, this system favors Availability (AP) over Consistency. The service must remain operational even during network partitions or node failures. The design should utilize data replication to prevent data loss and support graceful degradation (e.g., serving slightly stale counts rather than returning errors).
-
Durability: While the system may use in-memory caching for write buffering to handle bursts, the final state must eventually be persisted to durable storage. No user reaction should be lost once acknowledged by the system.
3. Capacity Estimation & Constraints
Before defining the architecture, we must estimate the system scale to determine the necessary storage and throughput capacity.
Traffic Estimates
-
User Base: ~2 billion Monthly Active Users (MAU). We assume approximately 200 million Daily Active Users (DAU).
-
Write Throughput (Reactions):
- Daily Volume: Assuming 20% of DAUs are active daily and perform an average of 5 reactions (likes/dislikes) each, we expect ~200 million write events per day.
- Write QPS:
- Average: 200M / 86,400 seconds 2,300 QPS.
- Peak: Traffic is rarely uniform. Assuming a 5x peak during viral events or prime time, we must handle ~11,500 write QPS, with potential bursts up to 20k+ QPS.
-
Read Throughput (View Counts):
- Video Views: Assuming ~1 billion video views per day, the system fetches the video like count ~11,500 times per second.
- Comment Views: If an average view fetches counts for the top 20 comments, this adds = 230,000 read QPS.
- User State: The client must also check "Did I like this?" for every view.
- Total Read QPS: The system must sustain ~250,000+ read QPS. The extremely high Read-to-Write ratio (~100:1) dictates a heavy reliance on caching.
Storage Estimates
-
Count Storage (Aggregates):
- We store the total likes/dislikes per item. With hundreds of millions of videos and comments, this requires hundreds of millions of counter records. However, since each record is small (ID + Integers), the total dataset for active counts is manageable (in the gigabytes range) and fits easily in memory (Redis/Memcached).
-
Reaction Storage (User-Entity Relationship):
- To enforce "one like per user" and enable "unliking," we must store every specific user-to-video interaction.
- Volume: 200 million new likes/day translates to ~6 billion new records per month. Over 5 years, this grows to hundreds of billions of records.
- Size: If each record is ~64 bytes (IDs, timestamp, status), 6 billion records 384 GB of new data per month. This requires a scalable, sharded database solution (e.g., Cassandra, DynamoDB, or sharded SQL).
We use a REST API.
1. Cast Vote
POST /v1/votes- Request Body:
{ "target_id": "video_abc123", "target_type": "video", // "comment" "action": "like" // "dislike", "none" (remove) }
- Response:
200 OK(Empty body).
2. Get Counts & State (Batch)
GET /v1/votes/summary?target_ids=video_abc,comment_xyz- Headers:
Authorization: Bearer <token> - Response:
{ "items": { "video_abc": { "likes": 1500200, "dislikes": 4050, "user_state": "like" }, "comment_xyz": { "likes": 45, "dislikes": 0, "user_state": "none" } } }
5. High-Level Architecture
The system comprises multiple decoupled components designed to handle high concurrency, data persistence, and background processing. Below is an overview of the architecture and data flow:
-
Clients (Web/Mobile): Users on YouTube’s website or app. When a user clicks like/dislike on a video or comment, the client sends a write request to the backend. When viewing a video or a comment, the client requests the current like/dislike counts (and whether the user liked it).
-
API Gateway / Load Balancer: Routes requests from clients to the appropriate service cluster. It can also perform coarse rate limiting (e.g., block a single IP making too many requests) and handle auth (ensuring the user is logged in).
-
Like/Dislike Service (Microservice): This is the core application service that exposes endpoints for liking, disliking, and retrieving counts. There will be many instances of this service running (to handle massive concurrency). Key responsibilities:
- Write API Handling: On a like/dislike request, authenticate the user, then process the like/dislike logic (e.g., ensure they haven’t already liked it, handle toggling). It then records the event in a database. It will record two things: 1) User's actions like "Adam liked <content_id>", 2) Increment the like/dislike count of the content.
- Read API Handling: On a get count request, fetch the current like and dislike counts for the requested item (video or comment), possibly from a cache or database. Also determine the requesting user’s own reaction (to highlight the UI if needed).
- This service is stateless (it doesn’t keep data in process between requests), so it can be scaled horizontally and be resilient (one instance fails, others handle traffic).
-
Database for Likes/Dislikes (user-action DB): A write-optimized database that stores the latest state of each user's like/dislike per video or comment. This will be a NoSQL distributed database (like Apache Cassandra or DynamoDB). The write is an upsert (i.e., update or insert) that either creates a new like/dislike record or updates an existing one (e.g., if the user toggled from like to dislike). This immediate write enforces uniqueness – a user cannot like the same item twice because the DB record exists to track that. We choose NoSQL for its scalability and high throughput on writes/reads. For example, Cassandra is designed to scale to very large sizes across many servers with no single point of failure, and is optimized for high write throughput (Facebook used it to handle billions of writes per day). For high availability, this database is distributed and replicated across regions (e.g., using a multi-master or leaderless DB like Cassandra or DynamoDB, which are designed for eventual consistency across data centers). Each write is local to the region (fast and available) and replicates in the background to other regions. This ensures even if one region’s database goes down, the data exists elsewhere.
-
Counts Store (Aggregated Counts Database): This is a database or caching system optimized for reading the total like/dislike counts for each content item. It could be a distributed in-memory cache (like Redis) or a NoSQL table storing counters. Each entry is keyed by content ID and holds the current total likes and dislikes.

6. Data Model Design
Here is the NoSQL schema for tracking user like/dislike actions on posts and comments. It is optimized for high scalability and quick retrieval of the latest user actions, while minimizing query latency and ensuring efficient updates.
1. UserLikes Table (Likes/Dislikes per User per Content item)
Stores the latest like/dislike action by each user on a specific post or comment. This table is keyed by user_id and content_id (composite key) so that each user-item pair has at most one record (the most recent action).
| Field | Data Type | Description |
|---|---|---|
| user_id | String | Unique identifier of the user who performed the action. (Part of the composite primary key) |
| content_id | String | Unique identifier of the content (post or comment) that was liked/disliked. (Part of the composite primary key) |
| action_type | String (enum) | Type of action: either "like" or "dislike". Indicates the user's latest reaction on the content item. |
| timestamp | DateTime | Timestamp of the latest action by the user on this item. Used to record when the action occurred (or last changed). |
2. ContentStats Table (Aggregated Likes/Dislikes per content)
Maintains the total count of likes and dislikes for each post or comment. This table is keyed by content_id so the like/dislike counts for any item can be fetched in a single, fast lookup. It is updated whenever a user’s like/dislike on that item changes (often via an event or stream).
| Field | Data Type | Description |
|---|---|---|
| content_id | String | Unique identifier of the content (post or comment). Acts as the primary key for this table (one record per item). |
| total_likes | Integer | Cumulative count of all "like" actions for this item. Updated whenever a new like is added or a dislike is changed to a like. |
| total_dislikes | Integer | Cumulative count of all "dislike" actions for this item. Updated whenever a new dislike is added or a like is changed to a dislike. |
Architectural Approaches
When designing a scalable like/dislike system, various architectural strategies can be employed. Each approaches has its pros/cons, lets look into these:
1. Synchronous Updates (Direct Write to DB and Counters Together)
How it works: Every user like/dislike action is immediately written to the database, updating both the individual user-action record and incrementing/decrementing the total like counter in a single, synchronous operation (often within a transaction). For example, clicking "like" will insert a like record and update the post’s like count column in the same request.
Pros:
- Strong consistency: The moment a user action is processed, the stored count reflects it for all users. The count in the database is always up-to-date immediately after each action, which means any read after a write will get the latest value.
- Immediate visibility: Users can see the new like/dislike count right away after their action, as the system doesn’t delay or defer the update. There’s no waiting for back-office processes – the data is consistent in real-time.
- Simplicity in implementation: It’s straightforward – write directly to the database. There are fewer moving parts (no queues, caches, or batch jobs needed), making the logic easy to understand and implement.
Cons:
- High write contention: Under heavy load (e.g., a viral post with many concurrent likes), the single counter field becomes a hot spot. Transactions will contend on the same row/record, causing lock waits or conflicts. This can severely throttle throughput as concurrency rises.
- Database bottleneck risk: The database must handle every like/dislike event and serve reads for counts. This increases load and can slow down as traffic grows. If the DB slows or goes down, the whole like system is affected (no buffering or alternative path). In essence, it doesn’t handle sudden surges or very large scale well without vertical scaling or replication.
Use Cases: This approach is best in scenarios with low to moderate traffic or where absolute consistency is paramount. For example, a small community forum or an internal application can use direct DB updates for simplicity. It’s also acceptable when the rate of likes/dislikes is low enough that the database can easily handle it. However, it becomes problematic at large scale (millions of likes) where the single counter update is the choke point.

2. Hybrid Approach (User Action Stored Immediately, Counts Updated Asynchronously)
How it works: In this approach, the application handles like/dislike actions asynchronously using a message queue (Kafka) to update counts in batches:
- Immediate Write of Action: When a user likes or dislikes a content item, the individual action is recorded immediately in the database (e.g. inserting a row in a
Likestable with user_id, item_id, action_type). This ensures the source of truth for individual actions is always up-to-date. - Publish Event to Kafka: Instead of updating the aggregate like/dislike count on that content item synchronously, the service publishes an event to a Kafka topic (e.g. “like_events”). The event contains details such as the item ID, whether it was a like or dislike, etc.
- Kafka Consumers Aggregate Counts: One or more Kafka subscriber workers listen on the topic. These workers accumulate events and periodically update the total counts. For example, a worker might keep an in-memory counter for each item or buffer a batch of events. Workers can be configured to batch updates – for instance, after every 100 events or every X seconds, they will compute the new totals. This batching dramatically reduces write load on the primary database by coalescing many increments into a single update.
- Batched Database Update: When a worker’s threshold is met, it writes the aggregated count to the database. This could mean updating a counter field in an “Items” or “Posts” table (e.g. incrementing the like_count by 100). The update can be done with an atomic operation (like SQL
UPDATE ... SET like_count = like_count + 100) to avoid race conditions between batches. By processing in batches, the system can handle high throughput of likes/dislikes while keeping database load manageable.
Pros:
This Kafka-based asynchronous approach offers several benefits at large scale:
- High Throughput & Low Latency for Users: The user’s action is recorded quickly (just an insert and a publish, both of which are fast), and they are not blocked by expensive count calculations. The heavy lifting of updating the aggregate count is offloaded to background workers, allowing the system to absorb a very high rate of likes/dislikes.
- Reduced Load via Batching: By aggregating multiple events into one database update, we dramatically reduce write contention on the main counters. For example, 100 like events might translate to a single
UPDATEquery, which is much more efficient than 100 separate updates. This batching improves scalability of the database. - Scalability and Decoupling: Using Kafka decouples the frontend action from the backend processing. We can scale out multiple consumer workers to handle increasing event volume without affecting the user-facing app. The system is also more loosely coupled – the app doesn’t need to know how counts are aggregated, it just fires an event.
- Fault Tolerance: Kafka’s design (with replicated logs and consumer groups) combined with the idempotent processing means the system can recover from worker crashes or downtime without losing events. Each like event is durably stored in Kafka until processed, and will be retried if a failure happens.
Cons:
- Eventual Consistency: The total like/dislike count in the database is not updated immediately at the time of the user action. There is a small delay (depending on batch frequency – maybe a few seconds or less) before the new like is reflected in the official count. During that window, a user might not see the most up-to-date count unless additional measures are taken (as addressed in the caching approach below). This is a classic trade-off of eventual consistency for higher performance.
- Complexity of System: The introduction of Kafka and asynchronous workers adds complexity. You need to manage a Kafka cluster and ensure consumers are working correctly. The code to handle batching, offset commits, and failure recovery is more complex than a simple synchronous update. There is more that can go wrong, so thorough monitoring and error-handling logic is necessary.
- Idempotency & Duplicate Handling: Ensuring exactly-once processing requires careful design. If not done properly, you could double-count likes (if a message is processed twice) or miss updates (if offsets are mismanaged). Implementing and testing the deduplication (such as maintaining a processed message store or using Kafka transactions) adds development overhead. Also, any deduplication store (like Redis or an extra DB table) must be maintained and can itself become a point of failure or performance bottleneck.
Use Cases: The hybrid approach is useful when you need to handle a decent volume of likes and want to avoid slowing down the user’s action, but you still want the reliability of logging every action. Many systems use this pattern in combination with slightly delayed updates. For example, an application might show counts that update every few seconds or on page refresh, which is acceptable in social apps where seeing the count “eventually” is good enough.

3. Asynchronous Count Updates with Kafka and Caching (Revised Third Approach)
How it works: This approach builds on the Kafka asynchronous update mechanism but adds a caching layer to provide instant feedback and fast reads. The steps are:
- Immediate Write of Action to DB: Just like the previous approach, each like/dislike action is recorded as a separate entry in the database right away. This ensures durability and a trace of each user’s action.
- Update Cache’s Count: The system then updates the cache for the total like/dislike count of that item immediately. For example, if a post had 50 likes in cache, and a new like comes in, the application or a caching layer will increment the cached count to 51. This gives real-time feedback – the next time someone fetches the like count (even the same user immediately after liking), they will see “51” from the cache without waiting for the backend aggregation. This cache is typically a fast in-memory store like Redis or Memcached. The update can be done with an atomic operation (e.g., Redis
INCR) to handle concurrent updates safely – ensuring two simultaneous likes both get applied without losing one. - Publish Event to Kafka: In parallel, the service still publishes an event to the Kafka topic for likes (so the asynchronous pipeline is informed of the new like). The event will be used by background workers to eventually reconcile the persistent count in the database.
- Kafka Workers Update Database: Kafka consumer workers operate similarly as in Approach 1: they consume like events in batches. The difference now is that these updates to the database’s aggregate count are somewhat redundant in the short term (because the cache already has the latest count), but they serve to persist the aggregated count for long-term consistency and as a fallback. Workers might batch 100 events and then do an SQL
UPDATE posts SET like_count = like_count + 100 WHERE post_id=.... Over time (every few seconds or minutes), the database’s stored count catches up with what the cache shows. If the cache was updated for each like, the DB update should match that total after processing the batch. - Cache and DB Convergence: The cache entry for the count can be given a short TTL (Time To Live), say 5 seconds, or some small window. This means every few seconds, if no new updates happen, the cache will expire and the next read will fetch the count from the database (which by then should include all recent updates from the Kafka consumers). This helps correct any discrepancy that might have occurred between cache and database. Alternatively, the system can invalidate the cache or refresh it when the database is updated by the worker (a mini write-through on the aggregated count update).
Read Path: For any client retrieving the like/dislike count, the application will read from the cache. If the cache has a value (not expired), it returns that almost instantly. This ensures that users always see the most up-to-date count (including recent likes) with low latency, as long as the cache is being kept in sync. If the cache entry expired or is missing (cache miss), the service can fall back to the database: fetch the persisted count from DB (which might be slightly behind), return it, and repopulate the cache with that value (cache-aside pattern). However, because of the short TTL and continuous updates, such cache misses for a hot item would be rare. Essentially, the cache acts as the primary source for reads, with the DB as backup and long-term storage.
Pros:
The Kafka + Cache approach provides the best of both worlds – responsive updates and scalable processing:
- Real-Time User Experience: Users see their like/dislike actions reflected immediately in the count, thanks to the cache update. The interface feels instant and interactive, with no waiting for the backend to catch up. Reads hitting the cache are extremely fast (in-memory lookups), which is crucial for high-traffic scenarios where many users are viewing counts.
- Reduced Database Load on Reads: With the cache as the primary source for counts, read traffic to the database for these counts drops dramatically. This frees the database to handle other queries and reduces the chance of it becoming a bottleneck. The cache shields the database from reads, and the batched writes (from Kafka workers) are infrequent and efficient.
- Scalability and Throughput: Like the previous approach, writes are still handled asynchronously via Kafka, allowing the system to handle a massive stream of likes/dislikes. The addition of caching also means that even if the like count is requested very frequently (e.g., a viral post being liked and viewed by thousands of users), those requests don’t overwhelm the DB. The architecture can scale horizontally: more app servers to handle user actions (each updating cache and sending events), more Kafka partitions/workers to handle the firehose of events, and a distributed cache cluster to handle fast reads.
Cons:
While this approach is powerful, it adds more components to manage:
- Higher Complexity: There are now three moving parts (DB, Kafka, Cache) instead of two. Ensuring all three stay in sync and debugging issues can be challenging. Developers must handle cache invalidation properly (a notoriously hard problem) – e.g., if a bug prevents invalidation on a DB update, the cache could serve stale data for longer than intended. Understanding the interplay of TTL, cache updates, and Kafka timing requires careful design and testing.
- Cache Consistency Issues: Despite our strategies, there can be edge cases of inconsistency. For instance, if the Kafka consumers are delayed (say the system is briefly overwhelmed), the cache might carry “unconfirmed” increments for longer. If the cache TTL expires before the DB is updated, users might see the count jump down then up again, which could be confusing. In practice this window is small, but it’s a trade-off: we prefer showing a possibly temporary count increase (optimistic update) for responsiveness, accepting that in rare cases it might momentarily correct downward. Keeping the TTL very short minimizes this inconsistency window but too short a TTL could increase database reads (striking a balance is key).
- Cache Memory Overhead: Storing counts for many items in cache consumes memory. If the app has millions of content items, you wouldn’t cache all of them permanently – likely you cache the hot ones that are being actively liked/viewed. The short TTL helps avoid filling the cache with rarely-accessed items, but it means those items will cause a DB read occasionally when they expire. This is generally fine, but it’s a consideration (this is a balance between cache hit rate and staleness).
Use Cases: The revised third approach combines Kafka for scalable, reliable processing with caching for instant user feedback and fast reads. It handles failures by ensuring no single point (cache or worker) being down will permanently lose data or show wrong counts for long. The use of short TTLs, cache invalidation, and idempotent message processing collectively address the consistency challenges, making this approach suitable for large-scale systems where both performance and accuracy are required. Users get a snappy experience, and the system can handle the load and recover from issues gracefully, at the cost of a more complex architecture that must be carefully managed.

Database Sharding & Partitioning
Both the UserLikes store and the ContentStats store must be partitioned to scale out. We cannot rely on a single monolithic database.
UserLikes (Per-User actions) Partitioning:
-
We choose a sharding strategy that balances load and avoids hot spots. A good approach is to shard by user ID (or a hash of user ID). This means all likes by a particular user go to the same partition.
- Rationale: When users add likes, different users are acting independently, so writes are naturally spread across shards by user. This avoids the scenario where one very popular video causes all writes to target one shard (which could happen if we sharded by content ID). By sharding on user, even if one video is extremely popular, the workload is spread across all the users who like it (because their user IDs hash to many different shards).
- Additionally, when reading or updating a specific user’s like (which we do for uniqueness checks and toggles), we know exactly which shard to hit (based on user id). This yields efficient point lookups or updates.
- The drawback is if we ever needed to list all users who liked a given video (which we don’t in this design), that would require querying many shards. But that operation is not required for serving the like count (the count is maintained separately).
-
In a NoSQL context like Cassandra, the distribution is handled by the cluster’s partitioner. We would choose the partition key as user_id (maybe with a hash to ensure even distribution). Cassandra will store partitions across many nodes (with replication). This gives automatic sharding and failover. We would tune the replication factor (e.g., RF=3 in each data center) and consistency level (e.g., LOCAL_QUORUM for reads/writes to ensure the local region has two copies in sync, prioritizing availability).
-
Replication: We replicate data across regions for resilience. For example, with Cassandra or a globally distributed NewSQL database, each user’s data might exist in multiple regions. This way if an entire region goes offline, the user’s like data can be served from another region.
-
Indexing: The primary key on (user_id, content_id) serves as our unique index.
ContentStats (Counts) Partitioning:
- We shard the ContentStats table by content ID (video or comment ID). Each item’s count is independent, so this is a natural key.
- Because some videos are much more popular than others, there is a potential for hot spots: one shard might receive a disproportionate number of updates if a single video on that shard becomes globally viral. To mitigate this:
- Ensure that the number of shards is large enough and use a good hash, so even very popular content’s updates can be handled by one shard’s resources. If a single counter update is, say, a lightweight row update, one DB instance can handle thousands per second easily. If one video is getting, for example, 50k likes/sec, we may consider more advanced partitioning (like splitting a single content’s count across multiple subtables or using a distributed counter). But realistically, 50k/sec sustained on one item is extreme. For planning, if needed, we could assign particularly hot items a dedicated node or do manual splitting.
- Some systems use tiered counters: e.g., maintain per-region counts for a video, then sum them for global. Our design could incorporate that: each region’s aggregator updates a local regional count (stored under contentID+regionID). Periodically, those are aggregated to a global total. This reduces cross-region writes but complicates reading the total in real-time (you’d need to sum or have a background job). Given eventual consistency is acceptable, we might simply show region-local counts that approximate global in short term. However, a simpler approach is to centralize the count per item and rely on the ability of one shard to manage it with eventual updates.
- When using a NoSQL like DynamoDB, partition keys that concentrate too many writes can be an issue. Dynamo might require a composite key to distribute even one item’s increments (which is tricky). Cassandra counters automatically distribute by partition key (one partition per item), so that has to hold up or be handled at app level if not.
🤖 Don't fully get this? Learn it with Claude
Stuck on Designing YouTube Likes Counter? Open Claude, copy a block below, and it'll teach you this exact concept — visually and interactively.
Progressively stronger hints — you still solve it.
I'm working on the problem **Designing YouTube Likes Counter** (System Design). Give me a HINT LADDER: start with the tiniest nudge, then wait. Only reveal the next, stronger hint when I ask. Do NOT show the full solution unless I type 'show solution'. Keep me doing the thinking. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
See the technique, not just code.
Explain the optimal approach to **Designing YouTube Likes Counter** with a VISUAL walkthrough: trace it on a small concrete example using ASCII art / a step-by-step diagram, narrate what changes each step, then give time & space complexity with a one-line derivation. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Catch bugs, edge cases, sub-optimality.
I'll paste my solution to **Designing YouTube Likes Counter**. Review it for correctness, missed edge cases, and time/space complexity, then coach me toward the optimal — don't just rewrite it. Ask me to paste my code now. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Lock in recognition with look-alikes.
Give me 2 problems that use the SAME underlying pattern as **Designing YouTube Likes Counter**. For each, let me attempt first, then review my answer and name the trigger signal that reveals the pattern. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.