What Is the Difference Between Content‑Addressable Storage and Location‑Based Addressing
Content-addressable storage identifies and retrieves data by its content (using a unique identifier like a hash), whereas location-based addressing finds data by its physical or network location (such as a specific file path or URL).
This fundamental difference affects how data is stored, accessed, and maintained in various systems.
Below, we break down the meanings of each approach, why they matter in the context of data storage, and how they differ in practical scenarios.
Understanding Content-Addressable Storage (CAS)
Content-addressable storage (CAS) is a data storage paradigm where each piece of data is accessed by a unique identifier derived from its content, rather than by a location or filename.
In practice, this means the system computes a cryptographic hash (a digital fingerprint) of the content and uses that hash value as the address to store or retrieve the data.
If you have the content’s hash, you can request the data from the storage system, and any storage node that has that content can serve it based on the hash match. This is analogous to identifying a book by a unique ISBN or fingerprint of its text, rather than by the shelf it sits on.
Key characteristics of CAS:
-
Content-Derived Addresses: Every file or data object is stored under an address that is generated from the content itself (often using a cryptographic hash function). If the exact same content is stored again, it produces the same address, ensuring no duplicates are stored (automatic deduplication). Conversely, if any bit of the content changes, a new address (hash) is generated, which means the changed data is treated as a new object. This guarantees that identical content isn’t needlessly duplicated and any change in content is immediately detected (because it results in a different hash).
-
Data Integrity and Immutability: Because the address is tied to the content, data integrity is inherently verified. If data were corrupted or tampered with, its hash would no longer match the expected content identifier. Thus, CAS ensures that stored content cannot be altered unnoticed; any modification creates a new content address. This makes content-addressable storage ideal for immutable data storage and scenarios where verifying content authenticity is important. For example, in decentralized storage networks and blockchain systems, content addressing guarantees that what you retrieve is exactly the original data (since any change would produce a different address).
-
Efficient Storage and Deduplication: CAS systems store unique content only once. If multiple users or references save an identical file, the system will recognize the content hash collision and store a single copy, pointing all references to that one stored object. This drastically reduces storage overhead for duplicate data and is valuable for backup systems or archives where many copies of the same document might exist. (For instance, if 100 users save the same email attachment in a CAS-enabled system, the attachment’s content is stored only one time and reused.)
-
Decentralization and Resilience: In a distributed context, content-addressable storage enables flexible data retrieval. Since the content address is universal, any server or peer that has the data can fulfill the request. This is how peer-to-peer networks like IPFS (InterPlanetary File System) work. You ask for content by its hash (called a CID in IPFS), and whichever node has it can deliver it. This provides resilience: even if the original source goes offline or moves, the data can still be obtained from another source, eliminating the problem of broken links or missing data as long as someone on the network has the content.
-
Examples of CAS in Action: Modern technologies quietly leverage CAS. Git, the version control system, is essentially a content-addressable storage for snapshots of files: each file and commit is identified by a hash of its content, which ensures integrity and avoids duplicate storage of identical file versions. IPFS and other decentralized storage systems use content addressing to make content permanent and verifiable on the Web. You retrieve files by their content hash rather than from a specific server. Some backup and archival storage solutions (like early compliance archiving systems and certain object stores) use CAS to prevent duplication and ensure that archived documents remain unchanged. Even hardware content-addressable memory (CAM) follows a similar principle at the silicon level, allowing retrieval of a data item by content match instead of an address (though CAM is a separate technical concept focused on fast lookups in networking hardware).
When to use CAS
Content-addressable storage shines when data integrity, deduplication, and distribution are top priorities. It’s excellent for data that doesn’t change frequently or that must be securely shared across decentralized networks.
For instance, once a piece of content is stored (like an image, document, or software package version), CAS ensures you can always fetch the exact same content by its identifier, and anyone with that identifier gets the same content.
This is crucial for systems like NFTs, blockchain, or scientific data sets where trust in the content is essential. It’s also great for caching and build systems (avoiding re-fetching or rebuilding content that hasn’t changed, since identical content reuses the same address).
However, CAS can introduce some overhead. Calculating hashes for large files and managing content indexes means write operations can be slower than simple location-based writes.
Also, when content updates frequently, CAS will treat each version as new data (since the hash changes), potentially increasing storage usage for many versions.
In such cases (high-churn, mutable data), a location-based approach might be more efficient.
Understanding Location-Based Addressing
Location-based addressing is the traditional way we access data, where we use a specific location reference to fetch the content. This could be a file path on a storage drive, an address in memory, or a URL/web address on the internet.
In essence, you ask the system to get "whatever data is stored at location X."
The identifier points to a place, not directly to the content’s identity.
Key characteristics of location-based addressing:
-
Explicit Locations (Paths/URLs): Data is retrieved by specifying its address in a directory or network. For example, on your computer a photo might be at
C:\Users\Name\Pictures\photo.jpg. The operating system finds the file by walking this path to the correct folder and file name. On the web, a URL likehttps://example.com/images/photo.jpgtells your browser to request the content stored at the serverexample.comin the path/images/photo.jpg. This is akin to saying "go to this specific shelf in the library to find the book". The approach is straightforward and human-readable: locations often reflect logical organization (hierarchical folders, domain names, etc.), which is why this method has been very popular and intuitive. -
Hierarchical Organization: Location addressing usually ties into a hierarchical system (folders within folders, domain names with subdirectories, etc.). This makes it easy for people to organize and navigate data (for instance, grouping related files in a directory). It’s the way most filesystems and the World Wide Web organize information. However, it also means the same content can reside in multiple locations. If you copy a file to two different folders, you now have two separate addresses for identical content. There’s no built-in mechanism to know they’re the same file. Each location is treated independently, potentially wasting storage.
-
No Automatic Integrity Check: When you fetch data by location, the system does not verify that the content is "correct" or unchanged. It simply retrieves whatever is at that address. If someone replaces the file at
photo.jpgwith a different image, anyone using that location will unknowingly get the new content. The address (location) stayed the same, but the content changed. There is no hash comparison by default in typical filesystems or HTTP to ensure the content is what it originally was. (Some systems add checksums or signatures on top, but it’s not inherent in location addressing.) -
Link Rot and Dependency on Infrastructure: A big downside of location-based addressing is that it’s tied to a specific place. If that place changes or disappears, the link breaks. We experience this as broken links or "404 Not Found" errors on the web when a page is moved or a site goes offline. This phenomenon is called link rot. Over time, links (locations) become invalid because the content was moved or removed. For example, a web URL might point to a server that later changes its domain or file structure, rendering the old URL useless. Similarly, a file path on your PC becomes invalid if the file is relocated. Location-based addressing therefore requires stable, centralized management: the owner of that location must keep it accessible and unchanged for links to remain valid. If data is relocated, all references to it must be updated manually, which is error-prone.
-
Ease of Use and Mutability: On the positive side, location addressing is very user-friendly and intuitive. We naturally think of finding things by where we put them. URLs and file paths can be descriptive (
/music/2025/Hits/song.mp3tells you exactly what to expect at that location). Also, updating content is simple: you can overwrite the file at a given path, and the address stays the same for consumers. This makes location addressing well-suited for dynamic or frequently updated content, e.g., a news website always usinghomepage.htmlfor its front page even as the content changes daily. Users and programs always go to that same address, and get the latest version. There’s no need to distribute a new identifier for each update, unlike CAS where new content means a new hash. -
Examples of Location Addressing: Almost all traditional systems use location-based addressing. Your computer’s file system, database records (identified by pointers or IDs which correspond to locations in storage), and the HTTP/HTTPS web are all location-addressed systems. For instance, when you use an
http://link, it points to a specific server and path. Whoever controls that server/location controls the content you get. If they move or change it, your link follows that location and you might get different data or none at all. Another everyday example: sending someone to a specific address to pick up a document (location) versus just handing them a copy of the document content. The location method requires the place to be accessible and the document to remain there.
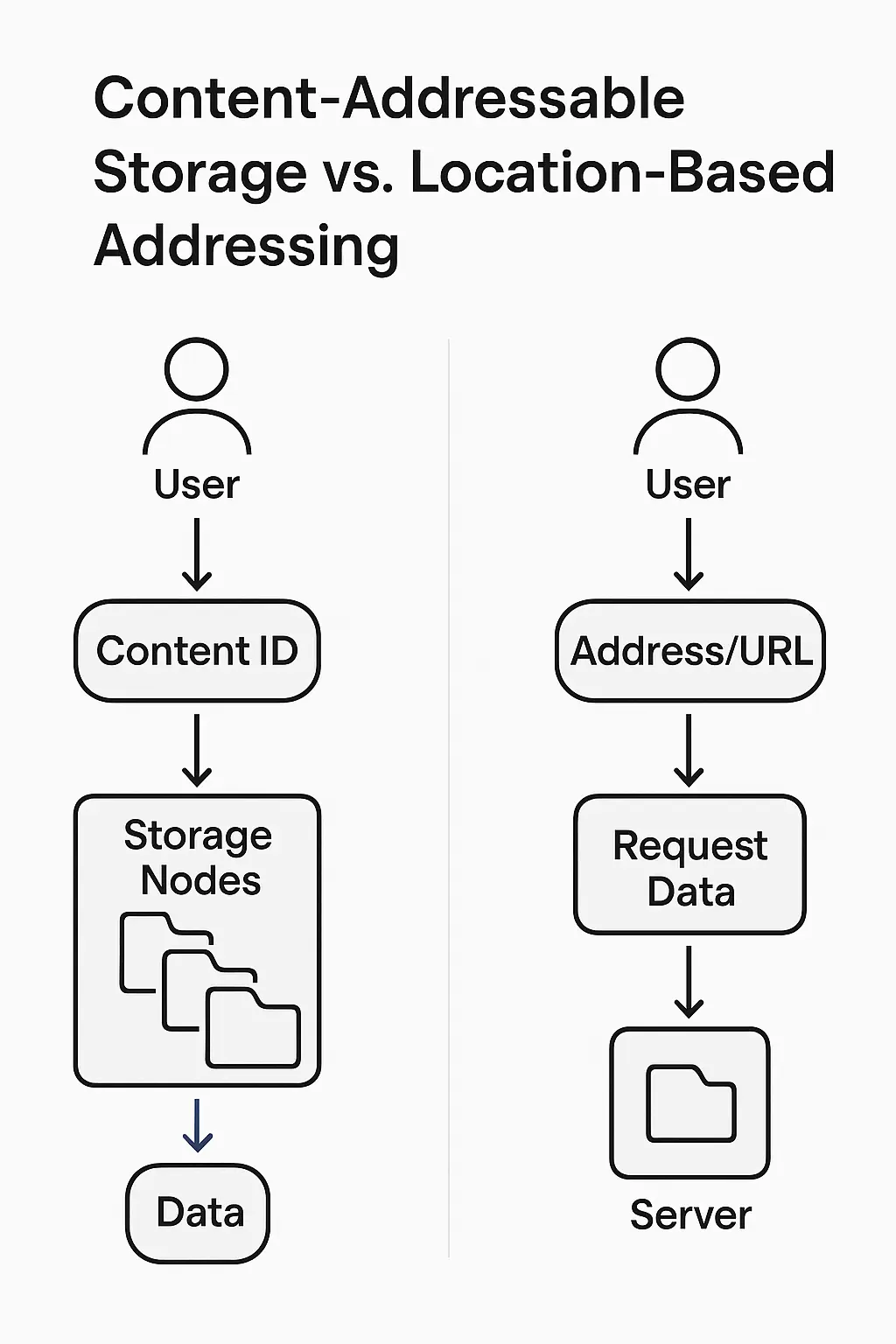
Key Differences Between Content-Addressable and Location-Based Approaches
Both content-addressable storage and location-based addressing serve the same basic purpose, allowing us to retrieve data, but they do so in fundamentally different ways.
Here are the core differences between the two approaches:
-
How Data is Identified:
– Content-Addressable: Identified by content. The address is a content-derived hash or fingerprint. You request data by saying "Give me the content that has hash XYZ."– Location-Based: Identified by location. The address is a path or pointer. You request data by saying "Give me whatever is stored at location XYZ."
-
Dependency on Physical Location:
– Content-Addressable: Location-agnostic. It doesn’t matter where the content is stored or how many copies exist. If a node has the content with the requested hash, it can serve it. This decoupling from physical location means content can be retrieved from anywhere, supporting decentralized and distributed storage easily.– Location-Based: Location-dependent. The address usually corresponds to a specific server, disk, or path. You must go to that designated spot to get the data. If the data moves, the address must change.
-
Data Integrity and Consistency:
– Content-Addressable: High integrity by design. Since the address (hash) changes when data changes, you’re guaranteed that content at a given address is exactly the original version stored. If the content is altered, its address is no longer the same, preventing inadvertent or malicious changes from going undetected.– Location-Based: No inherent integrity guarantee. The address doesn’t change if the data changes. The onus is on external measures to verify content. You might fetch data from a location and have to trust it’s the expected content unless you manually compare checksums or have version control.
-
Handling Updates and Mutability:
– Content-Addressable: Immutable addresses. Each unique version of content gets a new address. This is great for versioning and historical accuracy (you can have many versions coexisting, each with its own ID), but it means extra steps to track the “latest” version (some systems use an overlay index to point to the newest content hash). For frequently changing data, CAS isn’t as storage-efficient since every change creates a new object.– Location-Based: Mutable content at fixed address. Easy to update in place. Just change the data at the given location. Only one address to deal with, but you lose the historical trail unless you manually keep backups. This is efficient for data that changes often, as you don’t create a new address each time.
-
Storage Efficiency:
– Content-Addressable: Eliminates duplicates. The same content stored twice will be recognized by identical hashes and typically only one copy is kept, saving storage space.– Location-Based: Can have duplicates. The system treats each location independently. The same file saved in two places will occupy double the space because the addresses differ (no built-in deduplication).
-
Failure Modes (Link Rot):
– Content-Addressable: Robust links (if content exists somewhere). An address (hash) effectively becomes a permanent reference to that content itself, not tied to one server. As long as at least one node in the network still has that content, the link (hash) remains valid. There’s no concept of “moving” content. You just copy it, and it’s still accessible by the same hash. This virtually eliminates traditional link rot concerns (links breaking when servers or paths change).– Location-Based: Fragile links. If the resource moves or the server goes down, the link breaks (404 error). We’ve all encountered dead URLs – that’s link rot due to location dependency. Content could exist elsewhere identically, but the old link won’t find it because it was hard-coded to one spot.
-
Human Readability and Usage:
– Content-Addressable: Machine-friendly identifiers. Content addresses (like SHA-256 hashes or IPFS CIDs) are typically long alphanumeric strings. They’re great for computers and guarantees, but not meaningful to humans at a glance (e.g.,QmXo...123doesn’t tell you what the content is). This can make direct human interaction a bit less convenient. Systems often layer human-friendly names on top of CAS (for example, a filename that maps to a content hash behind the scenes).– Location-Based: Human-friendly paths/names. A URL or file path often describes the content (
/holiday/photos/beach.pngis intuitive). These addresses are easier for people to remember, guess, or manually type. The trade-off is we rely on those names remaining correct and the content not moving. -
Complexity and Infrastructure:
– Content-Addressable: Requires a lookup mechanism. To fetch data by content, systems maintain an index or use distributed lookup (e.g., DHT in peer-to-peer networks) to find which node has the content for a given hash. This adds complexity in design. Additionally, computing hashes for every stored object and managing a potentially large key-value store (hash -> data location) is computationally intensive, especially for large files or real-time changes.– Location-Based: Direct retrieval. The system knows exactly where to go (e.g., a filesystem knows which disk block or a URL knows which server). This direct mapping is straightforward to implement and typically faster for instantaneous lookups and writes (no hashing step on write). However, it centralizes control: the location’s host must coordinate any data distribution or replication separately.
Practical Examples and Analogies
To make these concepts more concrete, consider a few scenarios:
-
Web Pages (HTTP vs IPFS): The traditional web uses location addressing. For example, to view a blog post, you use a URL like
https://example.com/posts/123. That points to a server (example.com) and a path (/posts/123) on that server. If the site moves to a new domain or the post is relocated to a different path, that URL no longer works. In contrast, if the same article were stored on IPFS (which is a content-addressable decentralized storage network), you’d use a content identifier (CID) likeQmX...ABCto retrieve it. That CID is derived from the article content. If the original server goes offline, any other node that has the article can deliver it using the CID, and you’ll get the exact original content. This highlights how CAS provides content permanence: the address is bound to the content itself, not any single host. -
Version Control (File Path vs Git Hash): Imagine you have a file
Report.docxstored on your computer. You might update this file over time, but it’s always in the same folder location. If you accidentally overwrite it or corrupt it, the system has no inherent record of the old content (unless you manually saved copies). Now consider Git, which uses content-addressable storage for tracking file versions. Each version ofReport.docxthat you save in Git gets a unique hash (e.g.,abc123...) representing its content at that point in time. Git can have multiple versions of the file identified by different hashes, even if they all came from the same filename originally. You can always retrieve any version by its hash, ensuring historical integrity. In the normal filesystem (location-based), there’s just one location and it always points to the latest state of the file, losing the old content unless separately archived. -
Enterprise Storage (Backup/Archiving): Many enterprise backup solutions embraced CAS to avoid duplicate storage. For example, if employees constantly save the same attachment or document in different folders or emails, a CAS-based archive would store one copy identified by its content hash, instead of saving 100 copies. Traditional file servers (location-based) would happily keep all 100 copies in different folders, using up space. On the other hand, for a database that updates records every second, location addressing (by record ID or memory address) is simpler and faster, as the data is meant to be mutable and the old content is less relevant.
Why Does This Difference Matter?
Understanding the difference between content-addressable storage and location-based addressing is important for choosing the right approach in system design and data management:
-
Data Longevity and Links: If you need links that last over time and data that can be moved or shared without breaking references, content addressing is extremely powerful (it underpins the idea of the permanent web or Web3, where links don’t die and data can be verified as the original). In contrast, location-based links are brittle over long periods or across changes in infrastructure, which is a concern for digital preservation.
-
Security and Trust: Content addressing provides a built-in trust mechanism. If you know the expected hash of content, you can be confident in what you receive. This is why software package registries and Docker images often use content hashes (or content-derived checksums) to ensure you got the exact artifact you wanted and it hasn’t been tampered with. Location addressing alone can’t give that guarantee; it relies on trusting the source.
-
Performance and Scalability: Location-based addressing is simple and effective for centralized systems and frequently changing data, but it can struggle to scale globally (e.g., content delivery networks are essentially a layer to overcome location limitations by replicating data in multiple locations). Content-addressable networks inherently allow any node to serve content, which can be more scalable and fault-tolerant, though they require robust discovery mechanisms. Additionally, CAS can save storage and bandwidth by not duplicating data and by caching immutable content across the network.
-
Use Case Suitability: Ultimately, it's not that one method is universally better than the other. They serve different needs. Many systems actually combine them. For instance, IPFS (content-addressable) can be accessed through a gateway that has a human-readable URL (location-based). The gateway translates the content hash request to find the data. Another example is using a content hash in a URL (like
https://server.com/{hash}) to get benefits of both approaches (human can use the server address, but the server ensures the content matches the hash).
🤖 Don't fully get this? Learn it with Claude
Stuck on What Is the Difference Between Content‑Addressable Storage and Location‑Based Addressing? Open Claude, copy a block below, and it'll teach you this exact concept — visually and interactively.
Build the mental picture, not memorization.
I just read a lesson on **What Is the Difference Between Content‑Addressable Storage and Location‑Based Addressing** (System Design) and want to truly understand it. Explain What Is the Difference Between Content‑Addressable Storage and Location‑Based Addressing from first principles using ONE vivid real-world analogy and a visual mental model — draw it as ASCII art or a clear step-by-step diagram — with a concrete example using real numbers. Then ask me one question to check I got the mental picture, and wait for my reply. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Socratic — adapts to where you're stuck.
Teach me **What Is the Difference Between Content‑Addressable Storage and Location‑Based Addressing** interactively. Ask me ONE guiding question at a time, wait for my answer, and adapt to my confusion — build the idea with me step by step instead of explaining it all at once. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Active recall exposes what you missed.
Quiz me on **What Is the Difference Between Content‑Addressable Storage and Location‑Based Addressing** with 5 questions, easy to tricky, ONE at a time. Tell me if each answer is right; at the end, explain clearly what I got wrong and why. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Intuition + hook + flashcards for long-term memory.
Help me remember **What Is the Difference Between Content‑Addressable Storage and Location‑Based Addressing** for the long term: give the one-sentence intuition, a memorable hook/mnemonic, a tiny worked example, and 3 active-recall flashcards (Q -> A). If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.