What Is a Write‑Ahead Log WAL, and How Does It Ensure Durability
A Write-Ahead Log (WAL) is a technique where all changes are written to a separate, durable log file on disk before being applied to the main database or storage system, so that if a system crash occurs, the log can be used to recover the data and thus ensure no information is lost.
Durability is the “D” in the ACID properties of transactions. Iit means that once a transaction is committed, its changes are permanent and will survive any system failure.
WAL is a fundamental mechanism databases use to guarantee this durability (and it also helps with atomicity, the all-or-nothing property of transactions) by maintaining a sequential log of changes that acts as a safety net for recovery.
In simple terms, think of it like jotting down planned changes in a notebook before making them. If something goes wrong, you can always read the notebook to restore the intended changes.
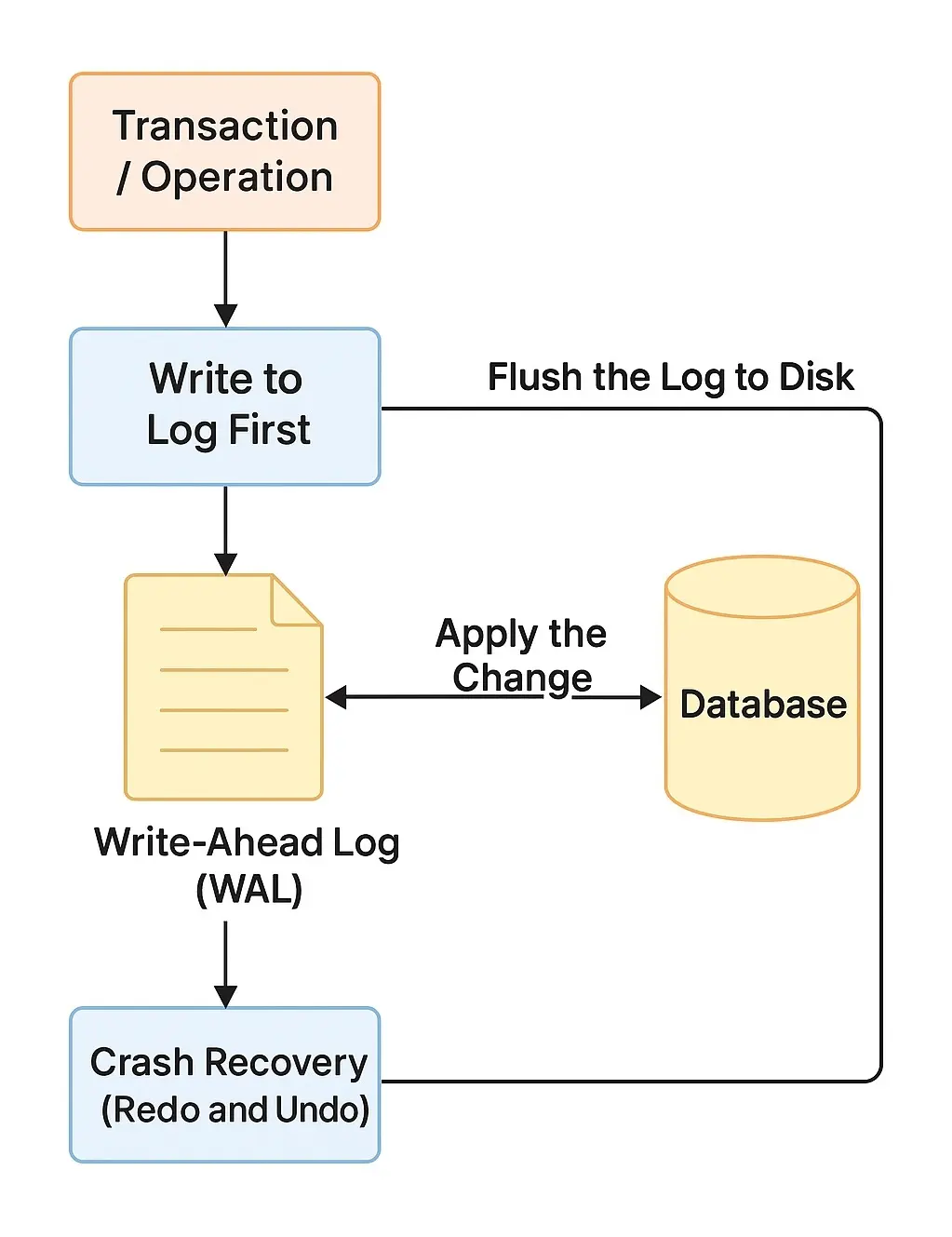
How Write-Ahead Logging Ensures Durability
WAL follows a strict order of operations to protect data.
The basic process is as follows:
-
Write to the Log First: When a transaction or operation wants to modify data, the details of that change are appended to the WAL (a log file) before any changes are made to the actual database. The WAL is an append-only journal on disk, meaning new entries are added sequentially to the end of the log. This log entry typically contains enough information to redo the change (and often to undo it, if needed).
-
Flush the Log to Disk (Durable Storage): The log entry is immediately flushed to stable storage (e.g. written to disk with an
fsyncor similar call) to ensure it’s really saved on non-volatile media. The system does not consider the transaction committed until this log write is safely on disk. (In fact, WAL guarantees that no data modifications are written to the database storage before the corresponding log record is on disk, preserving the proper order of writes.) This step is what gives WAL its durability guarantee even if a crash or power loss occurs right after, the record of the intended change is not lost. -
Apply the Change to the Database: Only after the WAL entry is securely stored does the system apply the actual change to the database’s data (often this means updating an in-memory cache or buffer which will later be written to disk). The database state is updated, but this may happen asynchronously. Because the modification was logged first, the system can always “catch up” later. Notably, WAL allows databases to do in-place updates to data files safely. You don’t have to write data to new locations every time, since the log is safeguarding the ability to recover those updates.
-
Crash Recovery (Redo and Undo): If the system crashes or fails before the recent changes are fully written to the main database (for example, in between database writes or before a memory buffer was flushed), the WAL enables recovery. Upon restart, the database software will read the WAL and redo any operations recorded in the log that had not been applied to the data files, bringing the database back to the last committed state. Because every committed change was written to the log, the database can replay those entries and no committed transaction will be lost. This two-step logging process ensures that no committed data is ever lost, even in the event of a crash. (Similarly, if a transaction was only partially complete or was aborted, the system can use the WAL to undo any changes that were recorded but not supposed to be permanent, maintaining atomicity.) The end result is that the database recovers to a consistent state with all durable transactions preserved.
Example Scenario
Imagine a banking database transferring $100 from Account A to Account B.
With WAL, the system first records entries in the log describing “decrement $100 from A” and “increment $100 in B” and flushes that log to disk.
Only then does it actually update the account balances.
Now, if a crash happens right after the log is written (but before the changes were fully applied to the database), the recovery process will read the WAL after reboot and find those two operations. It will redo them, deduct $100 from A and add $100 to B so the transfer is not lost. This way the durability of the completed transaction is guaranteed.
If the transfer had failed or been canceled, the log would similarly record that, and the recovery could roll back the partial changes.
Checkpointing
In normal operation, the system will periodically take a checkpoint, writing all recent in-memory changes to the main database files and marking a point in the WAL up to which changes have been applied.
After a checkpoint, the older portion of the log can be archived or truncated.
Checkpointing prevents the log from growing indefinitely and optimizes recovery time (since only changes after the last checkpoint need to be replayed after a crash).
Benefits and Importance of WAL
-
Reliable Crash Recovery & Durability: The foremost benefit of WAL is data durability and integrity. If a server crashes or loses power, the WAL provides a reliable record to bring the database back to a consistent state without losing any committed transactions. This gives users confidence that once a transaction is reported as committed, it will “stick” even if unforeseen failures occur.
-
Guarantee of ACID Durability: Using WAL, a database ensures the ACID durability property. Once data is committed, it’s safely stored on disk via the log. The WAL serves as an authoritative source of truth for recovery, meaning the system can always replay the log to recover committed operations. In other words, a successful commit means the data is preserved in the log, which acts as an insurance policy against crashes.
-
Atomicity (All-or-Nothing Transactions): WAL also contributes to atomicity. Because changes are logged and applied together, if a transaction fails midway, the partial changes can be rolled back (undone) using the log, or if a crash occurred, incomplete changes won’t be applied without their full context. Either the entire transaction’s effects are redone or none are. There’s no scenario where a transaction is half-applied. This prevents corruption and inconsistency.
-
Performance Optimizations: Interestingly, WAL can improve overall performance in many cases. Appending a record to a sequential log is typically fast (especially on modern storage) compared to random writes scattered across a disk. The WAL lets the database defer the more expensive writes to the main data files. Many changes can be batched and written at once during a checkpoint instead of every time. This reduces random I/O and allows the use of efficient batch writes while still maintaining safety. The trade-off is the overhead of writing the log, but because the log is sequential and often smaller than the full data changes, it’s usually very efficient. In essence, WAL provides durability without forcing every data file update to be flushed to disk immediately, striking a balance between safety and performance.
-
Foundation for Replication and Backup: The WAL is not only useful for crash recovery; it is often used for replication and backup strategies. For example, the log can be streamed to a backup server or copied to archival storage. In the event of disaster recovery or for creating a replica (standby database), replaying the WAL on another copy of the database can reconstruct the same state. Many databases support shipping WAL records to replicas in real-time, ensuring that the replicas stay in sync and providing high availability. This way, WAL helps achieve durability not just on one machine but across multiple systems (for distributed durability).
-
Widely Used Technique: Write-ahead logging is a proven design that underpins reliability in countless systems. It’s used in almost all modern relational databases and many non-relational storage systems because it’s conceptually simple yet powerful. Alternative approaches (like shadow paging) exist, but WAL is by far the more common approach to ensuring durability.
Examples of WAL in Practice
-
Relational Databases: Nearly all major relational database management systems use a form of WAL for their transaction logs. For instance, PostgreSQL’s WAL is central to its design. It guarantees that no committed transaction is ever lost, even in the face of crashes or power failures. SQL Server and Oracle use a similar approach (often calling it the transaction log or redo log), following the rule that modifications to data pages are not written until the log record is safely on disk. MySQL/InnoDB uses a WAL (called the redo log) to achieve crash-safe commits, and SQLite can operate in a WAL mode for concurrency and durability. In all these systems, the write-ahead log is the backbone that makes ACID transactions possible, ensuring that even if the database shuts down unexpectedly, it can recover by reading the log and applying any missing updates.
-
NoSQL and Key-Value Stores: Many non-relational databases and storage engines also use WAL internally for durability. For example, MongoDB uses an oplog (operations log), which is essentially a write-ahead log that records all writes to the database; this is critical for both durability and for replication to secondary nodes. Storage engines like RocksDB and LevelDB (used in many key-value stores) use WAL files to record new writes so that even if the application crashes before flushing data to their storage tables, the data can be recovered from the log. This pattern appears in embedded databases and caches as well. Whenever you need to ensure data isn’t lost on crash, an append-only log is a common solution.
-
File Systems (Journaling): Write-ahead logging isn’t just for databases. Modern file systems use a similar concept called journaling for file system metadata (and sometimes file data). For example, ext4, NTFS, and others will write file system metadata changes to a journal on disk before applying them to the main file system structures. This way, if the system crashes in the middle of, say, updating a file’s inode or directory entry, the journal (WAL) can be replayed to ensure the file system isn’t left in a corrupt state. Journaling file systems thereby protect against corruption by using WAL principles: they log changes to critical structures so they can recover or complete them after a failure.
-
Distributed Systems & Messaging: In distributed data systems, logs are often the core method of ensuring durability and ordering. For example, Apache Kafka (a distributed streaming platform) is built around the idea of an append-only log. In fact, every partition in Kafka is essentially a log file to which messages are appended (this is effectively a WAL for messaging data). Kafka brokers fsync their log writes to disk and even replicate them to multiple nodes before acknowledging messages, providing strong durability guarantees similar to database WAL (no message acknowledged to the producer is lost). Many other distributed systems (like distributed databases, consensus systems such as Raft, etc.) also rely on write-ahead logs to record state changes so that they can recover or replicate that state reliably. In summary, the WAL pattern is ubiquitous in systems that require fault tolerance.
🤖 Don't fully get this? Learn it with Claude
Stuck on What Is a Write‑Ahead Log WAL, and How Does It Ensure Durability? Open Claude, copy a block below, and it'll teach you this exact concept — visually and interactively.
Build the mental picture, not memorization.
I just read a lesson on **What Is a Write‑Ahead Log WAL, and How Does It Ensure Durability** (System Design) and want to truly understand it. Explain What Is a Write‑Ahead Log WAL, and How Does It Ensure Durability from first principles using ONE vivid real-world analogy and a visual mental model — draw it as ASCII art or a clear step-by-step diagram — with a concrete example using real numbers. Then ask me one question to check I got the mental picture, and wait for my reply. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Socratic — adapts to where you're stuck.
Teach me **What Is a Write‑Ahead Log WAL, and How Does It Ensure Durability** interactively. Ask me ONE guiding question at a time, wait for my answer, and adapt to my confusion — build the idea with me step by step instead of explaining it all at once. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Active recall exposes what you missed.
Quiz me on **What Is a Write‑Ahead Log WAL, and How Does It Ensure Durability** with 5 questions, easy to tricky, ONE at a time. Tell me if each answer is right; at the end, explain clearly what I got wrong and why. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Intuition + hook + flashcards for long-term memory.
Help me remember **What Is a Write‑Ahead Log WAL, and How Does It Ensure Durability** for the long term: give the one-sentence intuition, a memorable hook/mnemonic, a tiny worked example, and 3 active-recall flashcards (Q -> A). If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.