Problem 16 Scenario Multithreaded Web Crawler
Overview
A web crawler is a tool designed to browse the internet methodically and systematically to gather information from web pages. When deploying a multithreaded web crawler, one can expect significant performance improvements due to the concurrent fetching of multiple web pages. However, concurrency introduces challenges, especially when multiple threads try to access shared resources like a queue containing URLs. The primary concern is avoiding duplicate work, where two or more threads might end up processing the same URL because of simultaneous access.
Step-by-step Algorithm
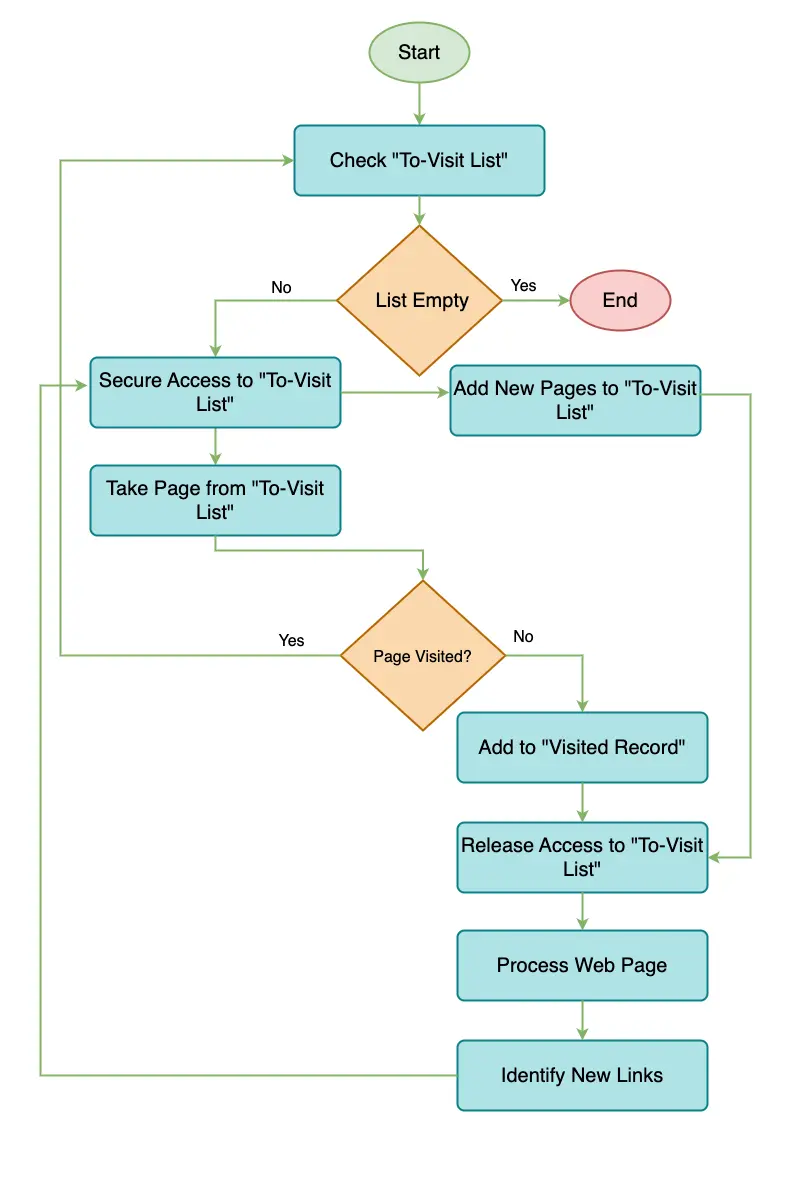
- Prepare a list of web pages to be visited, named "To-Visit List".
- Maintain a record of web pages that have been visited, named "Visited Record".
- Each crawler agent follows this routine:
- Check if there are still web pages in the "To-Visit List".
- If the list is empty, stop.
- Secure exclusive access to the "To-Visit List".
- Take a web page from the "To-Visit List".
- Ensure the web page is not in the "Visited Record". If it is, go back to the first step of this routine.
- Mark this web page as visited by adding it to the "Visited Record".
- Release exclusive access to the "To-Visit List".
- Access and process the web page.
- Identify new web pages linked from this page.
- Secure exclusive access to the "To-Visit List".
- Add these new web pages to the "To-Visit List", ensuring no duplicates.
- Release exclusive access to the "To-Visit List".
- Start the routine for all crawler agents simultaneously.
- Continue until all agents stop.
Algorithm Walkthrough
Let's walk through a dry run of the web crawler example you provided, paying special attention to the synchronization aspects.
Initialization
- toVisitList: Initialized with a seed URL "http://example.com".
- visitedRecord: Initialized as an empty set.
- queueLock: Mutex initialized to protect access to
toVisitList. - visitedLock: Mutex initialized to protect access to
visitedRecord. - Crawler Agents: 5 threads are created to act as crawler agents.
Execution
The execution for each crawler agent can be divided into several steps:
-
Get URL from Queue
- Acquire
queueLockto get exclusive access totoVisitList. - If
toVisitListis not empty, pop a URL from the queue and releasequeueLock. - If
toVisitListis empty, releasequeueLockand exit the loop (terminate the thread).
- Acquire
-
Check if URL is Visited
- Acquire
visitedLockto checkvisitedRecord. - If URL is in
visitedRecord, releasevisitedLockand go back to step 1. - If URL is not in
visitedRecord, insert it and releasevisitedLock.
- Acquire
-
Process Page: Print "Processing: URL" and sleep for 1 second to simulate processing time.
-
Add New Links to Queue
- Simulate fetching links from the page using
getLinksFromPage. - Acquire
queueLock. - For each link fetched:
- Check if it is not in
visitedRecord. - If it’s not, add it to
toVisitList.
- Check if it is not in
- Release
queueLock.
- Simulate fetching links from the page using
-
Repeat: Go back to step 1.
Synchronization Aspects
-
queueLock
- Ensures that only one thread can access
toVisitListat a time. - Prevents race conditions where two threads might try to pop the same URL.
- Protects integrity of the data in the queue.
- Ensures that only one thread can access
-
visitedLock
- Ensures that only one thread can access
visitedRecordat a time. - Prevents race conditions where two threads might process the same URL simultaneously.
- Protects integrity of the data in the set.
- Ensures that only one thread can access
Final Result
Through the use of mutex locks (queueLock and visitedLock), the program ensures that the shared resources (toVisitList and visitedRecord) are accessed in a thread-safe manner, preventing race conditions and preserving data integrity. The program simulates a web crawler where multiple agents are concurrently processing URLs, fetching new links, and ensuring that each URL is only processed once.
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Set;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Solution {
private static final int NUM_AGENTS = 5; // Number of crawler agents
private final Queue<String> toVisitList = new LinkedList<>(); // URLs waiting to be visited
private final Set<String> visitedRecord = new HashSet<>(); // URLs that have been visited
// Locks to protect shared resources
private final Lock queueLock = new ReentrantLock();
private final Lock visitedLock = new ReentrantLock();
public static void main(String[] args) {
Solution crawler = new Solution();
crawler.startCrawling("http://example.com");
}
public void startCrawling(String initialUrl) {
// Seed the toVisitList with an initial URL
toVisitList.add(initialUrl);
// Create and start crawler agents
Thread[] agents = new Thread[NUM_AGENTS];
for (int i = 0; i < NUM_AGENTS; i++) {
agents[i] = new Thread(this::crawlerAgent);
agents[i].start();
}
// Wait for all agents to finish
for (Thread agent : agents) {
try {
agent.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("Crawling finished.");
}
public void crawlerAgent() {
while (true) {
String url;
// Try to get a URL from the queue
queueLock.lock();
try {
if (toVisitList.isEmpty()) {
break;
}
url = toVisitList.poll();
} finally {
queueLock.unlock();
}
// Check if URL has been visited
visitedLock.lock();
try {
if (visitedRecord.contains(url)) {
continue;
}
visitedRecord.add(url);
} finally {
visitedLock.unlock();
}
// Simulate processing the page
System.out.println("Processing: " + url);
try {
Thread.sleep(1000); // Simulate a delay for processing the page
} catch (InterruptedException e) {
e.printStackTrace();
}
// Simulated function to get links from a web page.
String[] links = getLinksFromPage(url);
// Add new links to the queue
queueLock.lock();
try {
for (String link : links) {
if (!visitedRecord.contains(link)) {
toVisitList.add(link);
}
}
} finally {
queueLock.unlock();
}
}
}
public String[] getLinksFromPage(String url) {
// For the sake of this example, return some dummy links.
return new String[] { "link1", "link2", "link3" };
}
}
🤖 Don't fully get this? Learn it with Claude
Stuck on Problem 16 Scenario Multithreaded Web Crawler? Open Claude, copy a block below, and it'll teach you this exact concept — visually and interactively.
Progressively stronger hints — you still solve it.
I'm working on the problem **Problem 16 Scenario Multithreaded Web Crawler** (Concurrency). Give me a HINT LADDER: start with the tiniest nudge, then wait. Only reveal the next, stronger hint when I ask. Do NOT show the full solution unless I type 'show solution'. Keep me doing the thinking. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
See the technique, not just code.
Explain the optimal approach to **Problem 16 Scenario Multithreaded Web Crawler** with a VISUAL walkthrough: trace it on a small concrete example using ASCII art / a step-by-step diagram, narrate what changes each step, then give time & space complexity with a one-line derivation. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Catch bugs, edge cases, sub-optimality.
I'll paste my solution to **Problem 16 Scenario Multithreaded Web Crawler**. Review it for correctness, missed edge cases, and time/space complexity, then coach me toward the optimal — don't just rewrite it. Ask me to paste my code now. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.
Lock in recognition with look-alikes.
Give me 2 problems that use the SAME underlying pattern as **Problem 16 Scenario Multithreaded Web Crawler**. For each, let me attempt first, then review my answer and name the trigger signal that reveals the pattern. If you're unsure or a claim isn't standard, say so and reason from first principles instead of guessing.